
语义、实例分割
研究语义分割,源于现在的文字检测和识别算法,为了提高正确率,要变态地去区分到像素级别,比如在EAST、PSENET、TextScanner等算法当中,都应用到语义分割网络。而语义分割网络,作为目标识别的重要算法,也确实非常重要,之前虽然看过,但是,不自己撸一篇文章,还是很容易遗忘很多细节,所以,写下此篇,把一些细节总结下来,他日可以快速回忆起来。
目前主要的语义分割网络,有很多种,如FCN、UNet、Mask-RCNN、SegNet、DeepLab、RefineNet、PSPNet等等,我这里仅仅研究了FCN和UNet和Mask-RCNN,其他的有时间再去看了。
作为一个工程党,我不会去研究论文细节和原理本质,而是更关注实现的细节。对这个领域感兴趣的同学,可以看一下这篇知乎上的综述,快速了解一下这个领域。
FCN
先说说FCN(Full Convolutional Network) 全卷积网络,论文地址:Fully Convolutional Networks for Semantic Segmentation。名字由来:这名很容易和FCN(Full Connection Network)- 全连接网络混淆啊。其实,全卷积网络就是为了避免全连接网络的弊端(比如必须固定尺寸,比如全连接层参数过度哦,不得不用dropout这类手段防止过拟合啥的),改进成,所有的位置都使用卷积网络,避免使用全链接。这名就是这么来的。他不像全连接那样,把图像全部拉平,所以,还可以保持图像的空间结构。
全卷积网络三大件:
- 全卷积化(Convolutionalization):跟之前差不多,但是去掉了全连接层
- 反卷积(Deconvolution):用在把小的feature map上采样上去
- 跳层结构(Skip Layer):就是把不同层柔和到一起的方法
反卷积
原始经过卷基层,如VGG或者ResNet后,变成了1/32 x 1/32大小,缩小了32倍,我们为了做语义分割,肯定是要把他还原成原图大小,这样才好判断每个像素的分类。
如何把小的feature map变成原图的大小,最简单的办法是①线性插值,或者用②反池化,但是这种过于简单粗暴,还有一个更好一些的办法,就是通过③“反卷积”,需要使用一个的卷积核,来帮着变大。到底如何做呢?看下图:
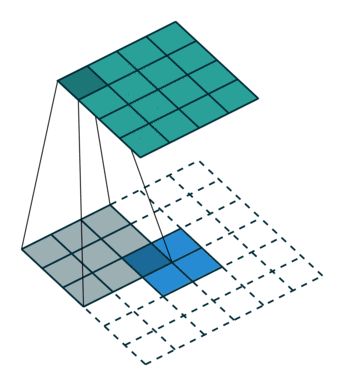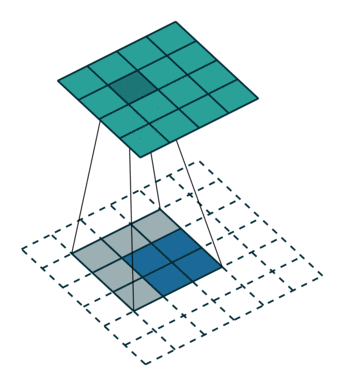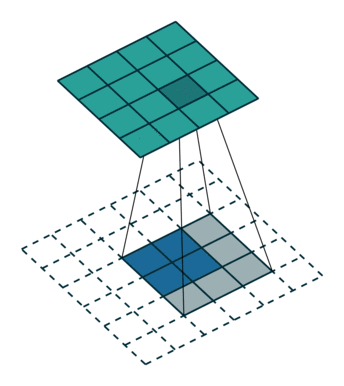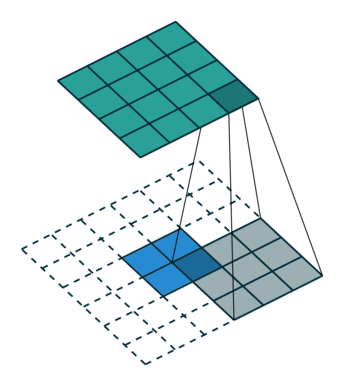
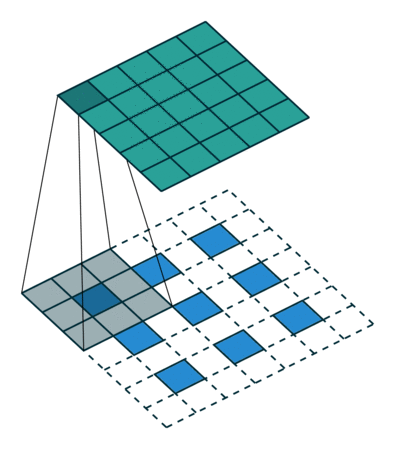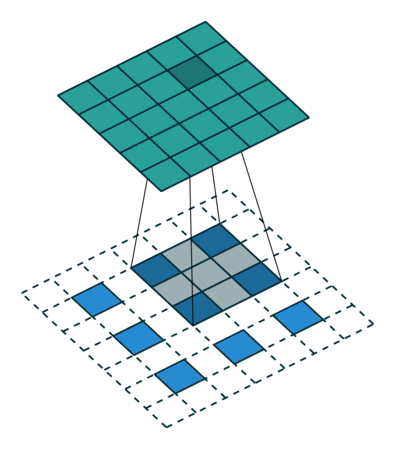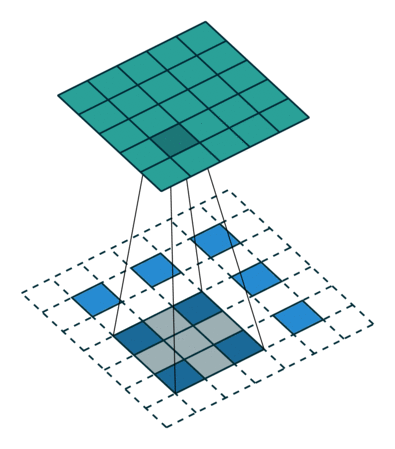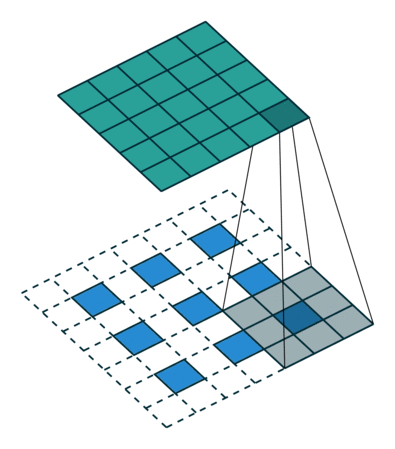
一图胜千言,如上图,下方是反卷积之前的输入的feature map,阴影是反卷积核,上面深绿色的是反卷积后的结果,因为原图小,所以要给他加padding(白色),这样就引出反卷积的两种方式(上图所示)。第二种更常用。可以读一下知乎上的这篇文章,了解更多细节。
跳层
如果只把最后一层(如何pool5,原图1/32)直接上卷积,妈呀,一下子就把最后的feature map的宽和高,增大了32倍,这会丧失很多细节啊!所以,最好是把之前的卷积层(如pool4,甚至pool3)的反卷积到原图大小,这样好多细节信息就不会都是了,这些信息也揉到一起,这件事就叫做跳层(skip-layer)。
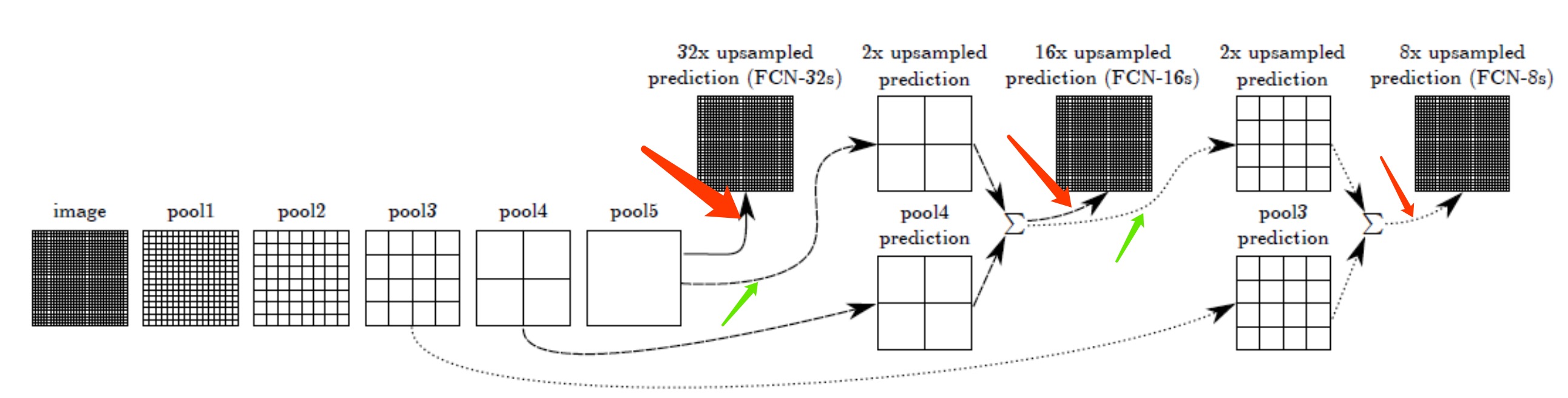
参考:
这里用的是VGG为例,pool1到pool5是五个最大池化层,因此图中的pool5层的大小是原图image的1/32(1/251/25),最粗糙的做法就是直接把pool5层进行步长为32的上采样(逆卷积),一步得到跟原图一样大小的概率图(fcn-32s)。但是这样做会丢失掉很多浅层的特征,尤其是浅层特征往往包含跟多的位置信息,所以我们需要把浅层的特征加上来,作者这里做法很简单,就是直接“加”上来,求和操作,也就完成了跳跃融合。也就是先将pool5层进行步长为2的上采样,然后加上pool4层的特征(这里pool4层后面跟了一个改变维度的卷积层,卷积核初始化为0),之后再进行一次步长为16的上采样得到原图大小的概率图即可(fcn-16s)。另外fcn-8s也是同样的做法,至于后面为什么没有fcn-4s、fcn-2s,我认为是因为太浅层的特征实际上不具有泛化性,加上了也没什么用,反而会使效果变差,所以作者也没继续下去了。
另外,
- FCN-16s就是pool4+pool5的信息,柔和到一起
- FCN-8s就是pool3+pool4+pool5的信息,柔和到了一起,是最精细的了。
ResNET50的FCN
FCN的backbone可以是任何主流的backbone,常用的ResNet50应该是怎么样的呢?我们来详细说说。
首先,可以看看Resnet50的结构,我们都知道Resnet50就比较深了,为了防止梯度小时,设计了shortcut结构。
好,可以先看看Resnet50的详细结构,参见这篇。
不过这个太复杂了,我们找个简化版本的:
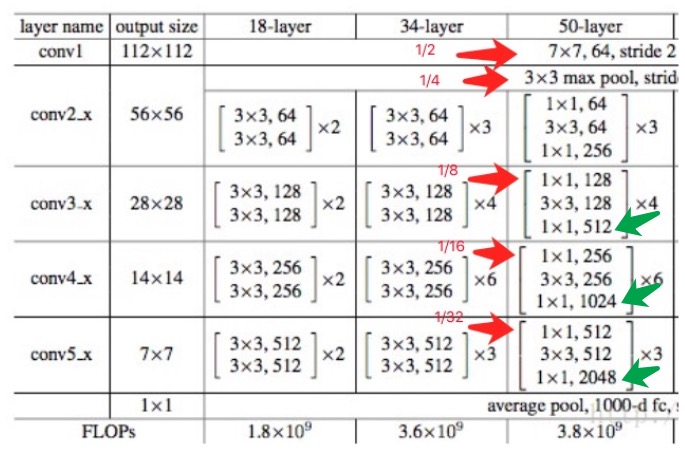
我们最关心的是他什么时候feature map缩小一倍,如图所示,我标识到了上图中。
为什么是这些位置了,具体可以参考这篇
#conv1 ->1/2 , 1/4
x = Conv2d_BN(x, nb_filter=64, kernel_size=(7, 7), strides=(2, 2), padding='valid')
x = MaxPooling2D(pool_size=(3, 3), strides=(2, 2), padding='same')(x)
#conv3_x ->1/8
x = identity_Block(x, nb_filter=128, kernel_size=(3, 3), strides=(2, 2), with_conv_shortcut=True)
#conv4_x ->1/16
x = identity_Block(x, nb_filter=256, kernel_size=(3, 3), strides=(2, 2), with_conv_shortcut=True)
#conv5_x ->1/32
x = identity_Block(x, nb_filter=512, kernel_size=(3, 3), strides=(2, 2), with_conv_shortcut=True)
Identity_Block,是Resnet设计的一个可重复的卷基层,由3组个卷积、BatchNormal、Relu激活组成,就是上图中中括弧表示的内容。
但是,我们不是直接在它刚刚变成1/2的地方就取出来去做FCN,而是在上图中的逻辑层Conv?_x的输出,也就是最后一个Relu激活函数后输出。另外,我们FCN其实只用到后3层的输出,也就是Conv3_x、Conv4_x、Conv5_x的输出,对应的在一般的pretrain的Resnet50的层的命名中,对应着activate_22,activate_40,activation_49三处。详细位置和标号,可以参见这张图。
对于原图尺寸不断缩小一半的地方,有必要再啰嗦两句:参考代码
- 1/2的时候:line 143:
x = Conv2D(64, (7, 7), data_format=IMAGE_ORDERING,strides=(2, 2), name='conv1')(x) - 1/4的时候:line 149:
x = MaxPooling2D((3, 3), data_format=IMAGE_ORDERING, strides=(2, 2))(x) - 1/8的时候:line 151:
x = conv_block(x, 3, [128, 128, 512], stage=3, block='a') - 1/16的时候:line 162:
x = conv_block(x, 3, [256, 256, 1024], stage=4, block='a') - 1/32的时候:line 170:
x = conv_block(x, 3, [512, 512, 2048], stage=5, block='a')
可以看出,除了第二个(1/4处 line149),剩下的都是靠stride=2的卷积实现的缩小一倍。
反卷积的实现
tensorflow提供了反卷积函数,采用的方式就是上面提到的“第二种”的反卷积方式,即在feature map的像素之间padding零,padding多少个呢?就是strip-1个。
TF的函数tf.nn.conv2d_transpose:
传入函数的参数有value,filter,output_shape,strides,padding,data_format和name,最主要的三个参数是value,output_shape和strides。value传入函数是为了确定输入尺寸,output_shape是为了确定输出尺寸,strides就是kernel在vertical和horizon上的步长。
- value的格式为[batch, height, width, in_channels],height和width是用来计算输出尺寸用到的最重要的两个参数,表示输入该层feature map的高度和宽度,典型的NHWC格式;
- filter的格式为[height, width, output_channels, input_channels],务必注意这里的channel数是输出的channel数在前,输入的channel数在后。
- output_shape是一个1-D张量,传入的可以是一个tuple或者list,在不指定data_format参数的情况下,格式必须为NHWC。注意:这里的C要与filter中的output_channels保持一致;
- strides的格式为一个整数列表,与conv2d方法在官方文档中写的一样,必须保证strides[0]=strides[3]=1,格式为[1, stirde, stride, 1];
- padding依然只有’SAME’和’VALID’;
- (与conv2d方法不同的是,这里需要人为指定输出的尺寸,这是为了使用value、output_shape和strides三个参数一起确定反卷积尺寸的正确性,具体在下个部分解释。)
FCN的实现
先贴论文Fully Convolutional Networks for Semantic Segmentation。
我分别找了4种实现,其实细节上还是有不少不同的,为了简化分析,我只关注fcn-32s的实现:
- Keras实现
o = f5 o = (Conv2D(4096, (7, 7), activation='relu',padding='same', data_format=IMAGE_ORDERING))(o) o = Dropout(0.5)(o) o = (Conv2D(4096, (1, 1), activation='relu',padding='same', data_format=IMAGE_ORDERING))(o) o = Dropout(0.5)(o) o = (Conv2D(n_classes, (1, 1), kernel_initializer='he_normal',data_format=IMAGE_ORDERING))(o) o = Conv2DTranspose(n_classes, kernel_size=(64, 64), strides=(32, 32), use_bias=False, data_format=IMAGE_ORDERING)(o)看!反卷积之前,对原始的feature map做了3次卷积(7x7和1x1和1x1)
- Tensorflow实现
conv_final_layer = image_net["conv5_3"] pool5 = utils.max_pool_2x2(conv_final_layer) W6 = utils.weight_variable([7, 7, 512, 4096], name="W6") conv6 = utils.conv2d_basic(pool5, W6, b6)<--------------7x7卷积 relu6 = tf.nn.relu(conv6, name="relu6") W7 = utils.weight_variable([1, 1, 4096, 4096], name="W7") conv7 = utils.conv2d_basic(relu6, W7, b7)<---------------1x1卷积 relu7 = tf.nn.relu(conv7, name="relu7") W8 = utils.weight_variable([1, 1, 4096, NUM_OF_CLASSESS], name="W8") conv8 = utils.conv2d_basic(relu7, W8, b8)<---------------1x1卷积 W_t1 = utils.weight_variable([4, 4, deconv_shape1[3].value, NUM_OF_CLASSESS], name="W_t1") conv_t1 = utils.conv2d_transpose_strided(conv8, W_t1, b_t1, output_shape=tf.shape(image_net["pool4"]))<----------------反卷积(这个是pool5经过一些列卷加后的反卷积,strip=2) fuse_1 = tf.add(conv_t1, image_net["pool4"], name="fuse_1")<----------和pool4融合这块有个疑问?pool5经过卷积后的conv8,为何要上卷积呢?论文里明明是2 x unsampled,也就是反池化啊?!
不过,这里还是跟上面的做法一样,反卷积之前,对原始的feature map做了3次卷积(7x7和1x1和1x1)。
- Caffi的实现,
n.fc6, n.relu6 = conv_relu(n.pool5, 4096, ks=7, pad=0) n.fc7, n.relu7 = conv_relu(n.drop6, 4096, ks=1, pad=0) n.score_fr = L.Convolution(n.drop7, num_output=60, kernel_size=1, pad=0,param=[dict(lr_mult=1, decay_mult=1), dict(lr_mult=2, decay_mult=0)]) n.upscore = L.Deconvolution(n.score_fr,convolution_param=dict(num_output=60, kernel_size=64, stride=32,bias_term=False)也是7x7卷积,2个1x1卷积后,才做反卷积
- Pytorch实现
self.pool5 = nn.MaxPool2d(2, stride=2, ceil_mode=True) # 1/32 self.fc6 = nn.Conv2d(512, 4096, 7)<----7x7卷积 self.relu6 = nn.ReLU(inplace=True) self.fc7 = nn.Conv2d(4 。 pool5是只做了一个crop剪切,, 1)<----1x1卷积 self.relu7 = nn.ReLU(inplace=True) self.score_fr = nn.Conv2d(4096, n_class, 1)<----1x1卷积 self.upscore = nn.ConvTranspose2d(n_class, n_class, 64, stride=32,bias=False)一样一样,都是7x7,1x1,1x1三个卷积。
我查看了原始论文中,并没有这样的一个固定的结构。
输出和损失函数
好像大家都不太提最后的输出是啥shape,都是抄来抄去的。我理解,他一定是和原图一边大,对,一样大。 那维度呢?维度是你要分类的种类加一。 算了,举个例子吧,比如说你宽高是800x600,分类是10种。那最后的结果输出,就是800x600x11(11是因为多了背景)。
然后,你算损失函数,其实就是一个简单的softmax平均值就可以。让这个800x600个softmax(是一个11维度的概率向量)的平均值最小化,这样来训练即可。
参考
UNet
好,来说说UNet(论文),UNet就是对FCN的改进,UNet是为了一次医学识别比赛专门搞的一个网络。
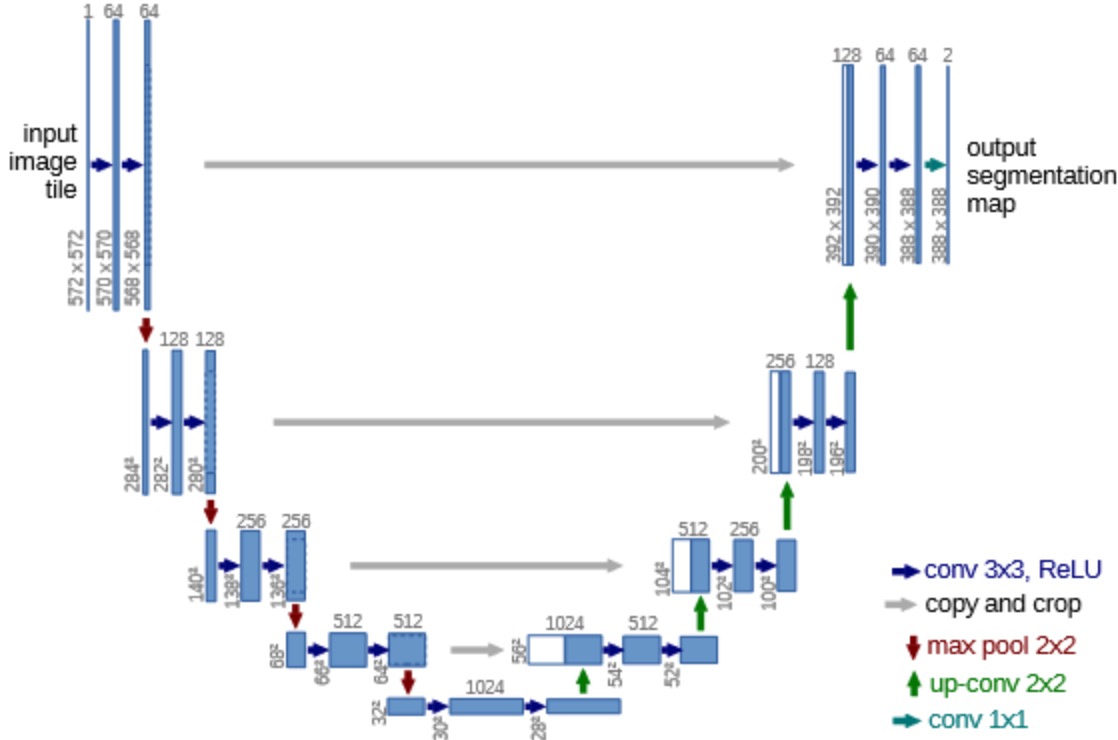
仔细看看网络结构,总共用了C1,C2,C3,C4 四层做融合,C5是最下层,只做反卷积即可。 每次融合前,都得做crop,比如第一个融合C4的融合,64x64被切成了56x56,咋切呢?其实就是直接去掉两边边就可以。
我自己觉得UNet也没啥好说好说的,就是用CNN做特征抽取,然后不同的层次反复融合(concat和反卷积),然后融到最后一个原图大小差不多的一个图,这个图是2通道的。
损失函数,原论文搞了个带权重的交叉熵损失函数,据说是为了突出边缘,是为了他的专有的比赛。我的理解,我们要做自己任务的时候,完全没必要,直接就交叉熵就可以。
UNet和FCN的区别
Unet实际上是改进了FCN,究竟做了哪些改进呢?
UNet用了更低层次的feature map,不像FCN只用了pool3、pool4、pool5,他还用了pool1,pool2。 pool5是只做了一个crop剪切。至于为何需要做crop,是因为,UNet做卷积的时候,没有做padding,会导致每做一次卷积,特征的长宽就会减少两个像素,最后网络的输出和输入大小不一样,所以去融合的时候,得切来切去的。
另外,和FCN的融合是用了ADD不同,UNet的融合是concat!
而且,UNet的输入和输出不一样,你发现了么?从572x572,变成了388x388,这个据说是因为原图太大,用个572的滑动窗口来搞,不过这块我也没太明白,所以就作罢了。在我看来,其实两边可以一样大小的。
另外,最后的输出你看网络图是上388x388x2,为何是2,这个是因为他这个比赛就是为了做一个病灶区域和健康区域,要是我们搞多分类,就是K分类+1(背景了)。
总之,就是这个UNet是为了比赛做了很多不太好理解的动作,但是,整体思想还是比FCN改进了很多,结构更清晰了,不想FCN 16s,8s啥的,UNet就是一个每层都参与,一共用了4次融合,而且,取代了Add是用了Concat,让feature更多。
参考
Mask Faster-RCNN
Mask R-CNN是一个实例分割(Instance segmentation)算法,比目标检测检测的更细,比语义分割更多的识别出不同的种类。
大体思路
关于识别过程,这篇参考写的很好,照搬过来了:
1,输入一幅你想处理的图片,然后进行对应的预处理操作,或者预处理后的图片;
2,将其输入到一个预训练好的神经网络中(ResNeXt等)获得对应的feature map;
3,对这个feature map中的每一点设定预定个的ROI,从而获得多个候选ROI;
4,将这些候选的ROI送入RPN网络进行二值分类(前景或背景)和BB回归,过滤掉一部分候选的ROI(截止到目前,Mask和Faster完全相同,其实R-FCN之类的在这之前也没有什么不同);
5,对这些剩下的ROI进行ROIAlign操作(即先将原图和feature map的pixel对应起来,然后将feature map和固定的feature对应起来)(ROIAlign为本文创新点1,比ROIPooling有长足进步);
6,对这些ROI进行分类(N类别分类)、BB回归和MASK生成(在每一个ROI里面进行FCN操作)(引入FCN生成Mask为本文创新点2,使得本文结构可以进行分割型任务)。
Mask-RCNN演变之路
Mask-RCNN是从RCNN –> Fast-RCNN –> Faster-RCNN –> Mask-RCNN,一路演变而成的。
Mask-RCNN是faster rcnn基础上的再改进,所以,有必要回忆一下从RCNN开始的物体检测过程。注意哈,rcnn、fast-rcnn、faster-rcnn都是在做物体检测,但是mask-rcnn是做了实例分割,这点和前辈们是有区别的。这也是,为何讨论语义分割的帖子里,要扯出一堆的物体检测的东西来的原因。
这里对rcnn、fast-rcnn、faster-rcnn的讨论不会太过详细,都是把核心要点和演变过程讲述一下,一切都是为了帮助更好的理解mask-rcnn。
RCNN
最早的物体检测,也是开创性的,是RCNN。
最重要的是要确定哪些区域是有物体的,也就是常说的ROI。RCNN用聚类来确定ROI,对图像点做聚类,聚类后得到一片片区域作为备选ROI,比暴力的滑动窗口方式好多了,降低了复杂度,这个过程叫selective search。
通过selective search终于得到一个个的ROI,然后交给cnn去预测是哪一个类了,不过还得同时,还得做一个回归,用于微调ROI,即bbox的x,y,w,h的预测,用于修正。
所以,RCNN做了分类和回归。
这里引入那个很诡异的$G_x、P_x$的公式,就是Tx啥的那个变换,这样做我理解是为了做归一化,让x,y中心点的偏移和bbox的宽高是成比例一致的,是归一化的。毕竟不同大小的bbox的偏移规格是不一样的,只有归一化了,才在一个尺度里吧。
其实,我觉得直接预测$\Delta_x,\Delta_y$是不是也可以?不知道,谁知道呢?估计那帮人肯定是验证过的,这样效果更好。
Fast-RCNN
RCNN还是非常慢,大约会搞出2000个selective search得到的ROI,然后每个ROI都要过卷积CNN进行计算,慢死了!
于是Faster-CRNN就做出了改进,不再每次把每个ROI过CNN,而是在最终的最后一层的feature map上,直接得到缩小版的ROI。
他用的ROI还是selective search方法,也就是聚类的结果哈,这个是在原图上。但是,他不在每个都过CNN了,而是按照CNN的缩小比例,把每个ROI等比例缩小,直接得到对应的在最后一层Feature Map上的ROI。 比如我的ROI在原图上是24x32,我的CNN缩小了8倍,那最终就是3x4的FeatureMap上的ROI了。(这个会损失信息么?我没想清楚。。。反正他们就是这么粗暴的干了!)
不过,得到3x4,是不定大小的,所以,要统一成一个size,才能接后面的全连接啥的,所以这里有个trick,这块就是常说的ROI pooling,说白了,就是把多大的图都resize成一个统一尺寸。
ROIpooling,是把3x4⇒2x2,是变小,我开始以为是变大呢,变小的时候肯定是是不均匀的,所以只能凑活的切,所以会存在不均衡的池化,这个也是后来mask-rcnn的改进。
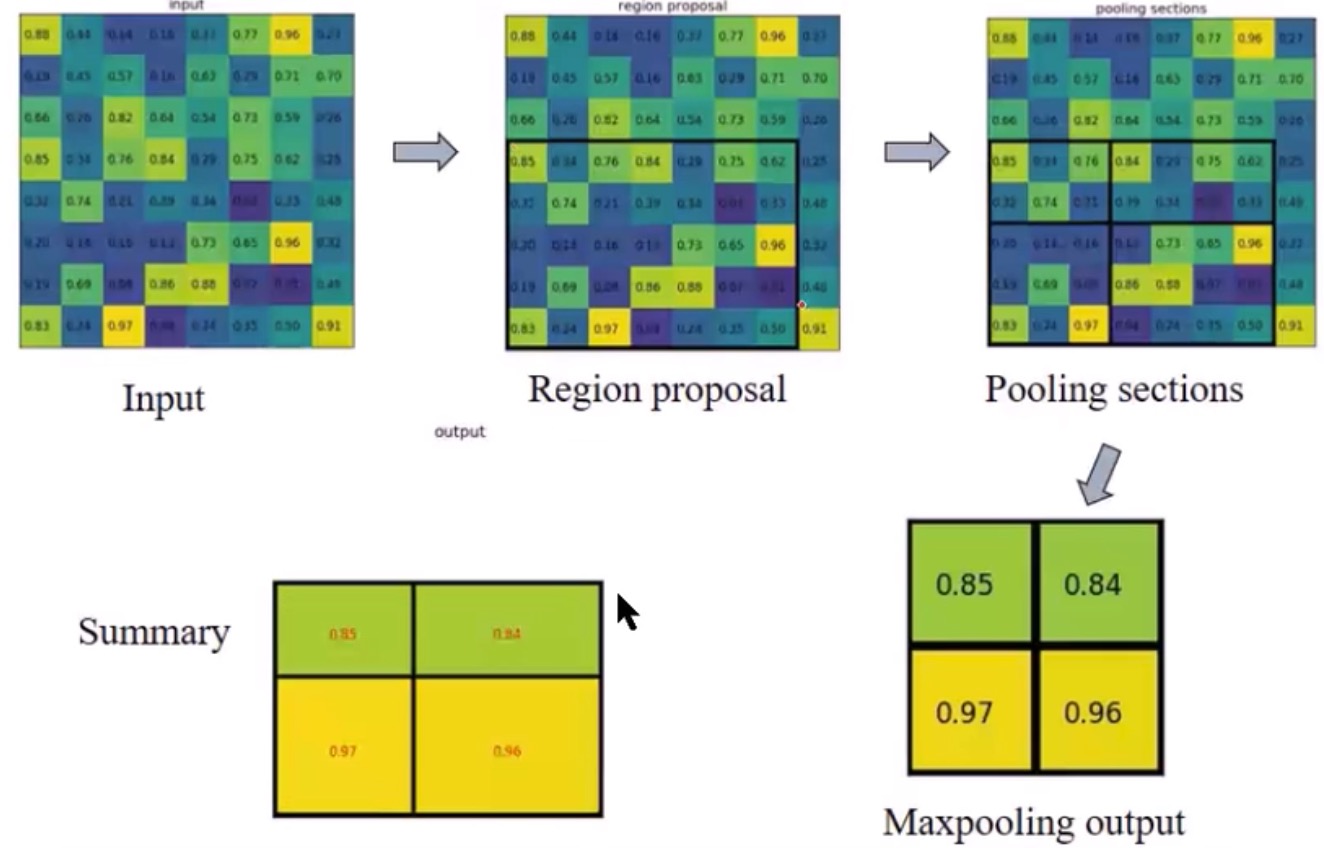
这图就图示了这个过程,要把ROI(黑框区域)max-pooling成2x2的,可是对不齐啊,5x7咋变成2x2啊,所以就得取舍了。
Faster-RCNN
现在再看Fast-RCNN,还是可以改进。比如ROI的确认,之前都用的selective search方法,即聚类方法,得到2000个roi,可是,聚类太慢了,所以faster-rcnn的faster,就是改进这个过程。
所以用 一个cnn网络,替代聚类了,这个网络就是叫RPN(region proposal network),帮我确定这些roi,恩,就改进了这点。其他都和fast-rcnn一样。
他怎么做的呢?
就是anchor,就是用最后的feature map的最后的一层的点当做轴心,每个点都扩展出10个anchor,然后用这些框当做roi。
那么多anchor,我用哪个去套真实物体呢,用iou,去算GT和我anchor的IOU最大的那个,我就选哪个。这个是训练的时候。真正预测的时候,用类别可以算出置信度,大的,就是对应训练的时候最大IOU那个。
注意!这个只是RPN网络,用RPN的损失函数,训练出来一个RPN,这也就是faster-rcnn里面说的stage1的训练。
有stage1,就有stage2,stage2就是用RPN帮我筛出来的ROI,再进一个网络进行这些ROI的类别判断和更精细的边框大小和位置的回归。
这里我一直不太明白:既然RPN已经做了ROI区域的宽高中心位置的回归,干嘛后面的网络还要做一遍,我看文献里说,是为了做“更精细”的回归,这岂不是多此一举了呢?!迷惑啊…
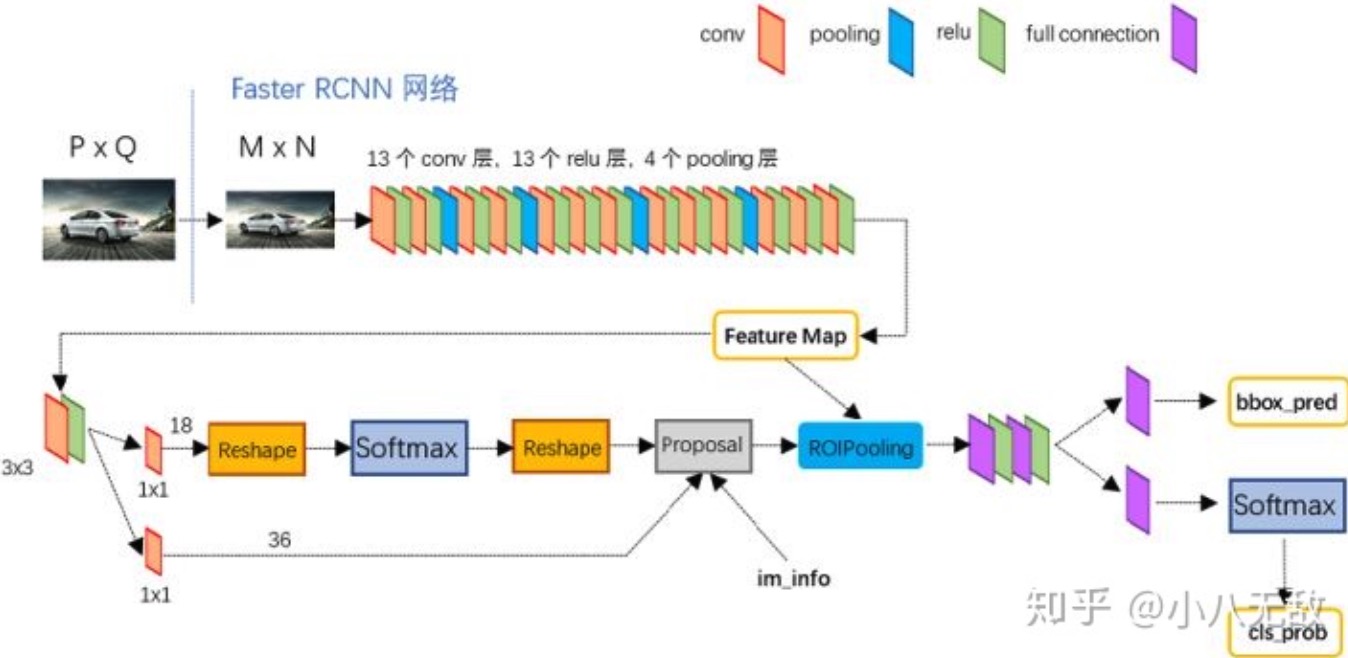
后面的ROI类别和更精细边框回归,都需要全连接,所以还是要做上面提到的ROI pooling,给他们搞成同样大小好做FC全连接。
回顾一下,stage1做proposal区域的二分类(是不是proposal)和边框回归;stage2做多类别判断和更精细边框回归。
白裳的这篇一文读懂Faster RCNN讲的超详细,推荐!
到目前为止,faster-rcnn还可以改进,就是他还是个单尺度的检测,由于特征抽取只用了最后一层,所以,只能检测大颗粒度的物体,对小物体咋办?这就要引入下面的FPN了。
FPN
FPN和FCN名字很像,样子又很像UNet,特容易混。恩,其实,在我看来FPN就是借鉴了FCN,用同样的办法,融合了不同感受野的feature map。
特征金字塔网络(FPN)来解决多尺度目标检测的问题,对,是为了解决目标检测的,不是语义分割的,这点要注意。
在我看来,虽然是为了解决目标检测而生的,但是他也是借鉴了FCN的思想,都是通过不同感受野的feature map的融合,从而更好地抽取图像中的不同尺度的语义信息的。
【FCN、UNet、FPN的关系和区别】
FCN是鼻祖,2014.11年就出来了,2015年3最终稿,它是开山之作。为了解决XXX问题。
UNet是2015.5发表,FPN都是2016.12发表,终稿是2017.3的。他俩都是站在FCN的基础之上。
区别: 引自知乎参考链接
- FPN出自detection任务;U-Net出自segmentation任务
- FPN的“放大”部分是直接插值放大的,没有deconvolution的filters学习参数;U-Net“放大”部分就是Decoder,需要deconvolution的filters学习参数的。
- FPN及其大多数改进都是把原Feature Map和FPN的Feature Map做加法;U-Net及其大多数改进都是把原Feature Map和Decoder的Feature Map做Concatiantion,再做1x1卷积。
- FPN对每一个融合的层都做detection;U-Net 只在最后一层做segmentation的pixel预测。
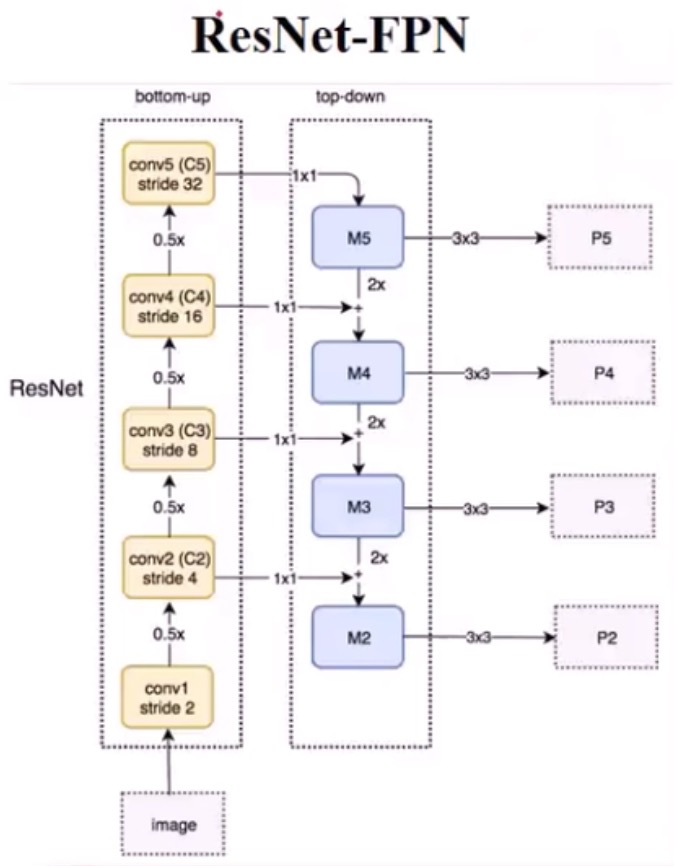
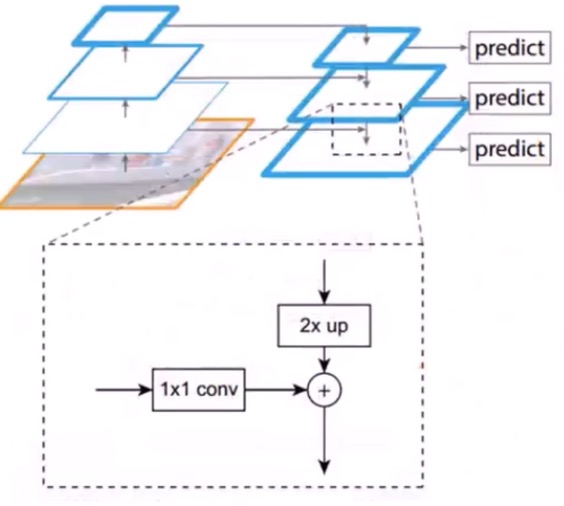
一般backbone都是缩小32倍,比如vgg,输入标准化为224x224,最后的feature map都7x7了,这么小,还ROI pooling个屁啊,这样还怎么预测小尺度的目标啊。
我能不能用用之前曾的feature map,比如缩小2倍、4倍的那些feature map,可是有个问题啊,这些层的语义信息是不明显的,越往后抽象语义信息越丰富啊。咋办?结合起来呗。把不同层的feature map融合起来。
咋融合?
是一个直接的下采样和一个1x1卷积,然后和上一层的结果进行相加,完成融合,下采样就是用1个值填4个值,没参数;但是1x1卷积有参数。为何用1x1卷积呢,说是降低通道数,我理解是比如resetnet的C5出来是7x7x1024,我用1x1,把他变成7x7x128,恩,你看,计算量下来很多了,就是去通道呀。
在融合层用去做预测之前,还要做一个3x3卷积,干嘛用?他们都说是为了去除混叠效应,我理解就是你粗暴的把下层和上层相加了,这样融合过于粗暴,需要用一个3x3再揉合一下你们俩。
FPN还搞了一个P6,就是resetnet的c5,再做一次下采样的结果,干嘛用呢,用来做RPN的输入,就是产生那些anchor们用的。而p5,p4,p3,p2,都用于产生每个anchor的回归和置信度的结果用了。可以产生,恩,4个批,4个不同层次的。
现在有了FPN,faster-rcnn被更增强了,变成了:
FPN+RPN+Fast-RCNN⇒牛逼的faster-rcnn,比之前的faster-rcnn牛逼的地方就在于多尺度了!
多个地方都可以预测物体,那到底我用那个预测呢?这个在训练的时候需要考虑。比如我一个20x30的物体,是用p5\p4\p3\p2 这四个中的哪个去预测呢,这样我才好算后续的loss呀。论文给了一个公式 $k= 下界(k_0+log_2(\sqrt{w*h}/224))$,算出来的k,对应的就是P#的#序号。说的很玄乎,就是按照目标(GT)不同的大小,给你归队到某个尺度的预测上去。
其他都一样,还是roi pooling,预测网络我理解用的是一个,就是不同尺度的roi pooling后一样大小的feature map,交给这个最后的预测网络(只有一个),然后预测回归和分类即可。
mask-rcnn
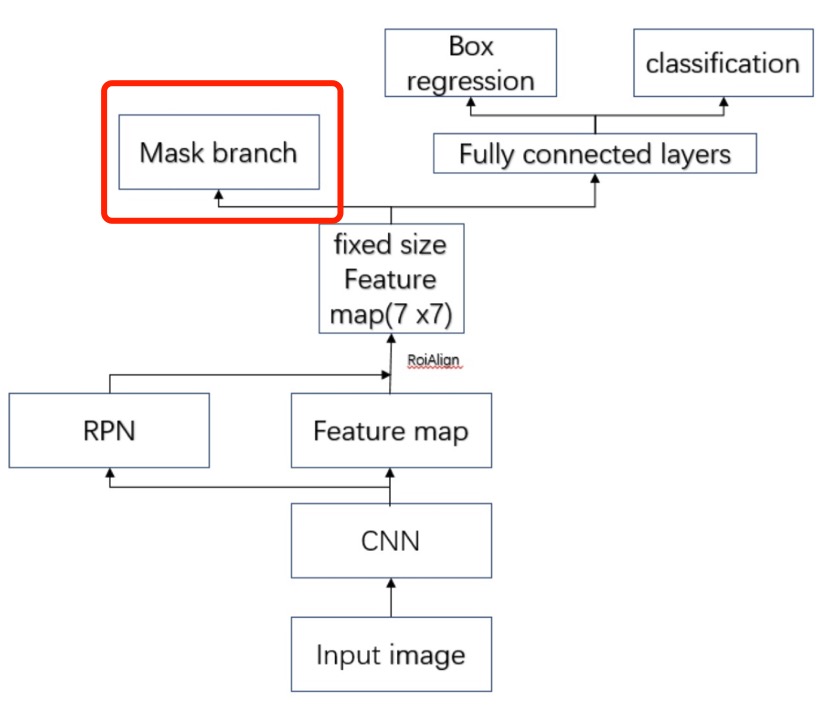
何凯明在fpn的faster-rcnn基础上,多了一个mask预测分支(之前只有分类回归分支),这个分支就是mask分支,用来在一个roi里面,预测每个像素的分类。这个就不再是物体检测了,而变成语义分割了,不,是实例分割了(实例分割每个像素可以属于不同类别,语义分割只能属于一个)。
三个创新点:
- 创新点1:改进了ROI Align,使用双线性插值,比ROIPooling有长足进步
- 创新点2:引入mask分支,用来预测
- 创新点3:损失函数的计算,作者放弃了更广泛的softmax,转而使用了sigmoid,避免了同类竞争
FPN的P_x输出是7x7x256, 但是mask-rcnn用的是28x28x256?怎么大了一倍?
mask输出是28x28x类别数,是固定的,所以你还得还原回你的roi区域大小去。
Mask分支
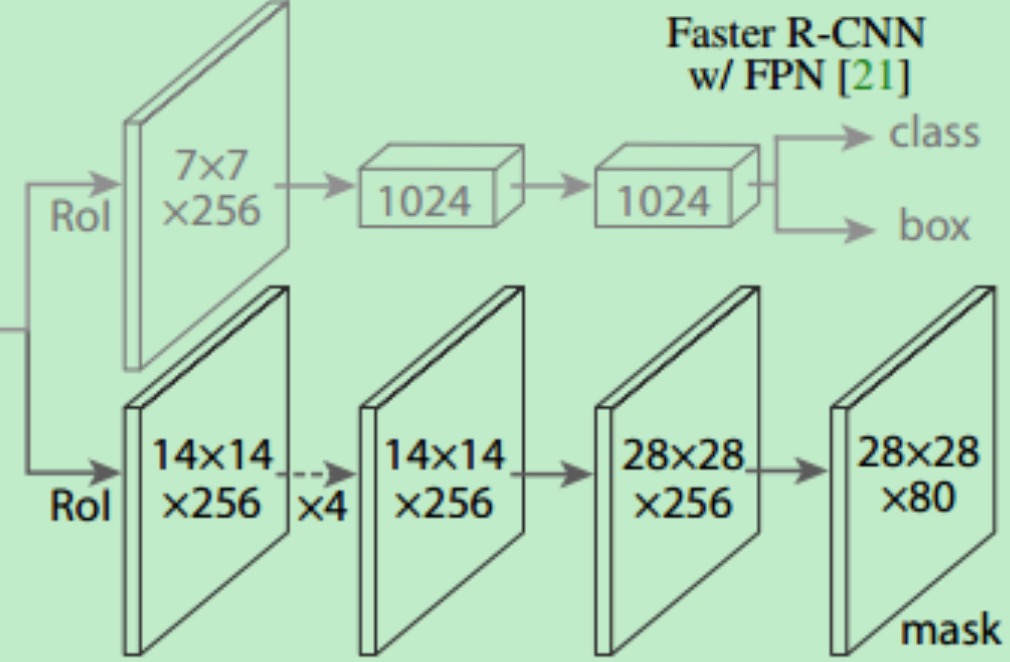
何凯明在fpn的faster-rcnn基础上,多了一个mask预测分支(之前只有分类回归分支),这个分支就是mask分支,用来在一个roi里面,预测每个像素的分类。这个就不再是物体检测了,而变成语义分割了,不,是实例分割了(实例分割每个像素可以属于不同类别,语义分割只能属于一个)。
FPN的P_x输出是7x7x256, 但是mask-rcnn用的是28x28x256?怎么大了一倍?
mask输出是28x28x80(80是类别数),这个ROI大小是固定的,所以你预测换,还要还原到你原图大小的坐标上去。
按理说,最后mask损失应该是80维度的一个softmax概率向量和one-hot的标签做交叉熵就好了。不过,那样貌似没法解决多预测问题,也就是1个点既是A类,也是B类的实例分割问题,咋办呢?何凯明想了一个招,就是用sigmod,不用softmax。具体咋操作呢?
你看上图中,右上角的class,即,你可以知道你预测出来的这个ROI是那一个类,对吧?然后你就去80个类里面,去找对应的那个类的图,这样就从28x28x80里面,找到了一张图,也就是28x28x1,对,这张图和你的GT一对比,一样的地方都是1,不一样的地方都是0,然后你就做sigmod的损失就好了。
双线性插值
为何要做差值呢?之前的faster-rcnn里,有一个操作是ROI pooling,
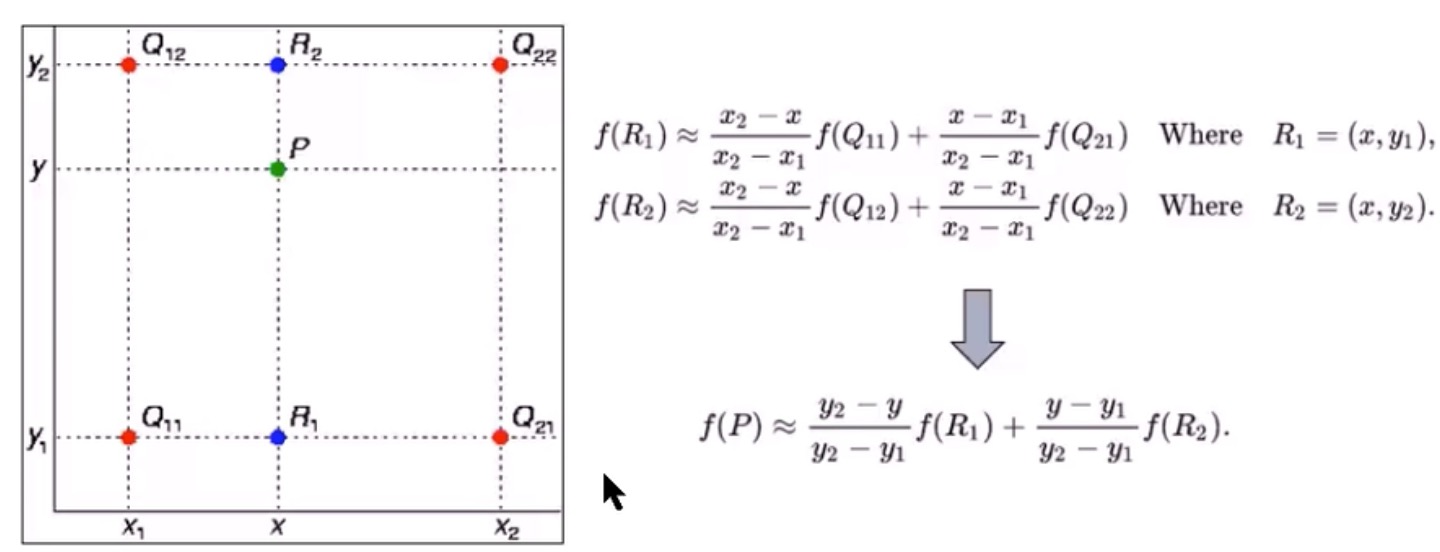
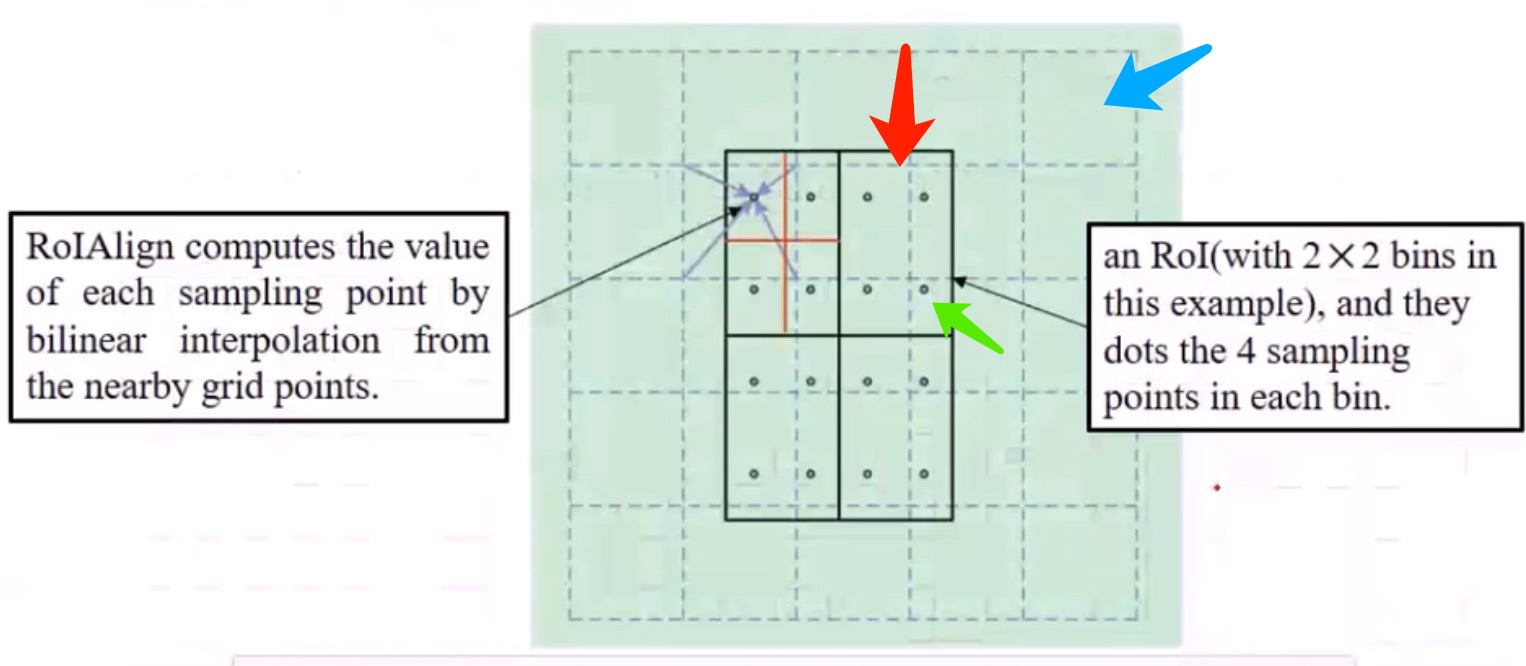
左图,就是用周边4个点($Q_{11},Q_{12},Q_{21},Q_{21}$)的值,来确定中间位置的点P的值。恩,这就是双线性差值。
右图,黑框是ROI,3.2x2.2的一个框,要pooling成2x2,咋办?虚线交叉点都是像素值。 做法是,先化成4个小黑框,然后4个黑框里面找4个对齐的点,然后算这些点的双线性差值的值。 然后这4个点里面,再max pooling一个出来,作为这个小黑框的值。 最终,得到了2x2的值。
这么做有啥好处呢?好处是,考虑了其位置和值,而不是想之前的ROI pooling那样粗暴。
参考
【视频】
- 小象学院的专题分享,讲的最好
- 鱿鱼哥的讲解,讲的很不错,有理论有实战
- 七月在线的讲解
- 一个培训的大嗓门讲的
- 声音腼腆的小哥讲的
- Faster-RCNN就是淦,讲fasterrcnn的
- 纯撸论文的视频
- 小象的深度视觉课中的关于分割和识别的2节
- 一个培训机构的讲解,凑活
- 将门的mask-rcnn的分享
【文章】
- cnblog,最好的一篇
- 语义分割综述 ,stone的,就是小象讲maskrcnn最好的那哥们,他的语义分割专栏.
- stone的讲mask-rcnn的
- 雷鸣的SIGAI的语义分割综述
- mask-crnn的解析 目前我们用的mask-rcnn的代码对应的文章
- RFCN,是听小象里知道的网络,需要了解一下