
最近
最近,苦于要解决文字中生僻字、低频词的识别,以及识别正确率的问题,做了一些研究。
之前用的crnn,3770的一级字库,使用我们自己标注的图片,正确率跑到84%,不是特别满意,曾经看过阿里读光OCR团队分享过,他们通过注意力方式,切出单字来,大大正确率:
生僻字的解决方法如上图所示,首先使用行识别,再进行了Attention单字识别方案解决了生僻字语料偏少的问题,Attention可以解决单字切字问题。通过上述方法,我们对2万多生僻字测试集进行了测试,精确度从21%提高到了99%,基本上解决了生僻字问题。
所以我就尝试实现Attention OCR,但是,总是不收敛,于是开始尝试各类方法,包括回顾了我实现过程中主要参考的Aster的TRN网络、Focus Attention以及最近比较火的TextScanner模型,把自己的一些心得体会记录下来,形成此文。
先说说Aster的TRN
先贴论文:Aster:An Attentional Scene Text Recognition with Flexible Rectification
论文团队给了一个代码实现:Github Aster,主要包括了变形纠正的SRN网络和后面的文字识别TRN网络,前面的变形纠正网络,我没有细研究,目前没有需求,略过,主要是看了看文字识别网络,感兴趣主要是因为,他是一个典型的注意力识别模型,是具代表性的,当然这也不是他的原创,RARE里最早提出来的,他只不过借鉴过来。这里我把论文学习的过程的一些理解整理出来:
论文说,CTC的问题是说,他是一个组合概率的$\Sigma$,即所有的排列组合的关系,很难确定字之间的关系,这点不是很特别赞同,因为CRNN其实也是使用了bi-LSTM来捕捉图像前后的顺序贯彻习的,但是CRNN确实不太好确定字的位置,在解码每个字的时候,全靠之前的bi-LSTM抽取的特征,这个时候遇到对齐问题,所以也只好靠B变换,插入空白来解决了。
注意力实际上是另外一种尝试,他用注意力机制,来在输入的bi-LSTM抽取的特种中来回跳转,通过注意力捕捉后的注意力向量,来参考这些信息,“聚焦到”对应的需要解码的图像特征,然后,避免了对齐问题。
不过,金连文教提过,微软亚洲研究院做过评测,注意力是干不过CTC的,特别是在长文本的情况下,论文也提到了,超过11个字就明显干不过了.
As can be seen, the recogintion accuracy is farely even on words whose lengths are equal to or less than 11. Beyond this length, a drop in accuracy is observed.
先说说网络结构
网络结构上,有个细节有些迷惑,第5页里面提到“Next, the feature map is converted into a feature sequence by being split along its row axis. The shape of the feature map is $(h_{conv},w_{conv},d_{conv})$,respectivly its height, with and depth.”,这句很含糊,因为前面提到了,高度已经被卷集成1了,第7也的Table1图中的Block5输出为1,也表明了这点,但是这里有提到了所谓的$h_{conv}$,很矛盾啊?!而且,Fig7中的这张图也没有把高度画成1。
他的Conv用了backbone的网络,我看Table6中,尝试了VGG和ResNet,我是自己搭了一个网络,当然也不是自己啦,是照抄了CRNN的Conv网络部分,但是是从头自己训练的,是不是应该借鉴一下,使用vgg或者resnet初始化呢?鉴于我不收敛的悲惨现状,确实应该去尝试一下。
解码器上有点意思,他用了一个bi-RNN,注意啊,是decoder,encoder也用了,但是这里是decoder。然后他会前向解码一次,后向解码一次,然后各自$\sum$一下,谁大就用谁的答案,这个做法挺有意思。注意,他不是挨个字比较,挑概率高的字,而是整个解码结果sum后比较。所以,他的lost也是逼着前后解码都要好。这个玩法,很有意思。他的Table5,也比较了一下,bi-RNN确实比单向RNN效果要好一些。
训练细节
他说了,2天才收敛的,大概是用了100万batchx64张图片,6400万张。使用的数据集包括Synth90K和SynthText,Synth90K是专门为识别训练合成的数据集,大概有900万张;SynthText是为了检测用的,数量我也没查,他们把文档给切出来用的。基本上每个batch,这两种数据一样一半。我看了图,差不多2万个batch以内是明显变化的,差的情况,4万个batch之内,也是明显变化的,这个和我自己写的那个网络不收敛是不一样的,555555。
他提到了个细节,他的图都是直接暴力resize成32x256的,像我那样,保持比例resize然后padding,他说效果反倒次,这个让我有点意外。不过他没又给出差多少的定量分析数据。
其他
他提到了,如果用aster的STN获得的变形矫正的点,可以帮助更精确地定位文字,也就是可以帮助提高检测的精度,这个思路也挺有意思的,不过我没有细看,回头有时间研究一下。
我的Attention OCR,也是借鉴了这个思路,不过我没有用backbone的conv,而是照着crnn弄了一个,另外,我也没有用它的bi-rnn的decoder,我训练的过程就是不收敛,我tensorboard观察梯度直方图,根本梯度变化就是0,唉,究竟哪里出了问题呢?至少从他的论文上看,人家训练上来是慢慢收敛的,而不是一开始就跟我那个似的,不停震荡。
接下来说说FA(Focus Attention)
先贴论文:Focusing Attention: Towards Accurate Text Recognition in Natural Images
2017.10的论文了,日期有点老,不过,我还是去啃了一下。
上来,他先抛出了“attention drift”的概念,大白话就是说,你解码的时候,你还原出编码器的对应位置,发现,根本不是要解码的那个区域,那还能解码的对啊?!
作者说,他们率先采用了Resnet做backbone,这个听着有点扯啊,anyway,有个预训练的应该是好的,CRNN还用vgg呢。他们还参考人家语音识别的ctc+attention的方法,失败啦。
作者说,传统的AN(attention network)不好train那种海量的样本集,比如800百万(我估计是笔误,是800万)的合成样本集。这句话,让一直train不出来自己撸的网络的我,稍感宽慰。
FA网络
(…未完成)
说说CA-FCN
这个可以说是textscanner的前导算法,
由来
由于会存在弯曲的文字识别图片,导致ctc这种靠一个一维的序列来识别有些困难了,下面这图,很明显得考虑二维的信息啦。
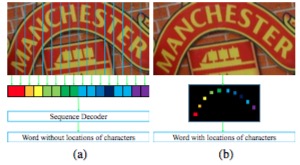
随着语义分割网络,如FCN,香酥鸡,不,是像素级的语义分割,可以对二维的汉字信息进行很好的辨析,这个就是这个算法的发心。
##
这个算法核心就3点:
- 把FCN语义分割方法引入进来,避免ctc那样的一维序列方式,哈哈,升维了(二维了)
- 引入了注意力机制,嫌语义分割还不够狠,再加上注意力,哈哈,想SOTA就要下猛剂啊
- 啥imprecise localization的模糊初始啥的,没搞明白,//TODO???
参考
TextScanner
TextScanner是旷视的姚神、华中科技大的白神坐阵的最新的一个识别力作,第一作者是旷视的万昭祎,第二作者是华中科技大的何明航。我就阅读论文中遇到的一些问题,向何明航进行了请教,得到了他很大帮助,这里特别感谢一下。
这篇是目前效果SOTA的一个识别框架,所以,我也花了最多的时间去学习和理解。它也开启了不同于CTC和Attention之外的第三条识别道路,就是尽量采用卷积,少量的RNN,速度可以做到更快。
其核心思路,在我看来就是三个图:
- G:Character Segmentation:W,H,Class(Class是字符集个数),这个用来分辨是哪个字符
- H:Order Segmentation:W,H,N(N是序列长度),这个是来分辨字符的从左往右的顺序
- Q:Localization Map:W,H,1,这个是用来告诉那些像素是字符像素
“每个字符在什么中心位置上,是哪一个字符,排在第几个顺序上”,一言以蔽之,就是这句话。
接下来,看下网络结构,
网络结构
这里主要参考第3页的第3节:3.Methodology
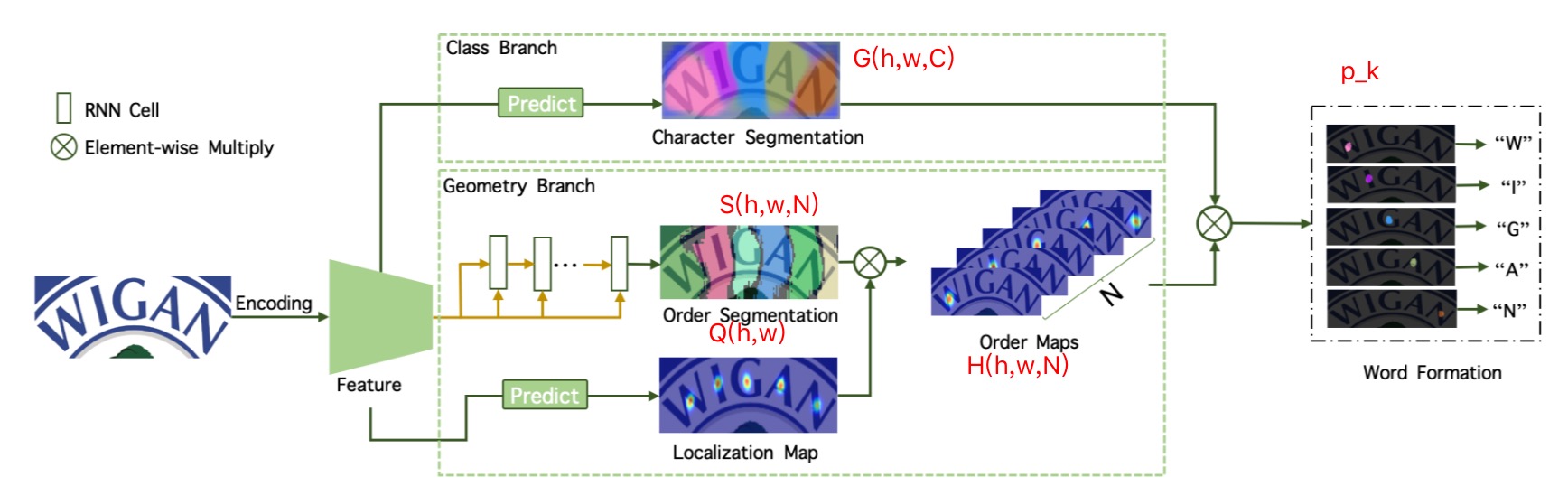
开始是3个子网络的输出(Character Segmentation,Order Segmentation,Localization Map),后2个子网络输出(Order Segmentation,Localization Map)的结果还要合体(element-wise相乘)成一个新的结果(Order Maps),然后在来一次合体,即Character Segmentation和Order Maps合体,得到最后的Word Formation。
细节是,要搞清楚每个输出的维度:
- Character Segmentation:W,H,Class(Class是字符集个数)
- Order Segmentation:W,H,N(N是序列长度)
- Localization Map:W,H,1
- Order Maps:W,H,N
Class Branch - Charachtor Segmenation($G(w,h,class)$)
输入是backbone之后的feature,我没细想,应该是resize之后,但肯定是固定size的。 比如vgg,resenet输出都是224x224x3=>7x7x512,那这图会从32x256=>1x8。
所以,这个块是有问题的?!走不通了。
所以,我看了论文里提到了,是用了CA-FCN的结构来抽取feature,只不过是把VGG替成了Resnet50:
Our model is built on top of the backbone from CA-FCN, in which the character attentions are removed and VGG blocks are replaced with a ResNet-50(He et al. 2016) base model.
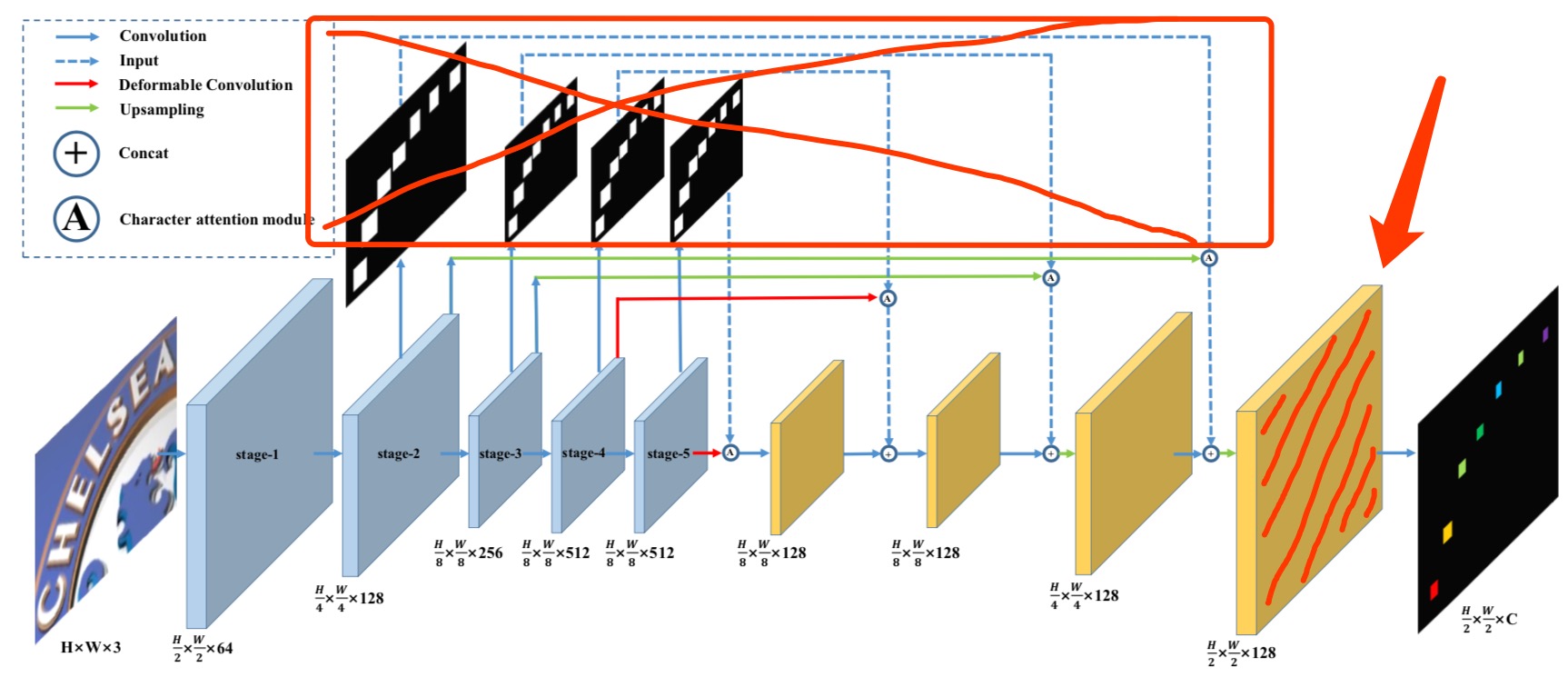
这样理解的话,就应该如上图,去掉了attention,取最后的FCN网络的结果,那和原图一样,是64x256的输出,通道数应该是FCN最后隐层神经元个数。
During training and inference, the input im- ages are resized to 64 × 256.
然后过2个卷积,然后过一个全连接,最后输出(w,h,c),比如(32,256,3370),c是字符分类个数,比如3770的一级字库数。
The prediction module is composed of two stacked convolutional layers with kernel size 3×3 and 1×1.
Geometry Branch - Localization Map($G(w,h,1)$)
输入是backbone之后的feature,文中没有提,只是提到了过一个sigmod,所以我推测,是不需要再像Class Branch再过2个卷积的,而是直接Sigmod了。
但是,有一点,我假定backbone抽取出来的是256的维度的,但是,256维度是没办法过sigmod的,必须要变成一个值,才可以算出单个点的sigmoid值来, 所以至少需要过一个全连接啊,所以,我推测,这里需要一个全链接,参数是256x1,这样(w,h,256)x(256,1)=> (w,h,1),然后再过sigmoid函数, 得到了Localization Map($G(w,h,1)$)。
TODO:这个细节不知道推测的对不对,需要去问一下原论文作者???
这些需要停一下,我们得到的G到底是个什么鬼?
是在每个点上计算了概率,我理解是是不是文字的一个概率,这张图就能确定哪些点是文字,那些点是背景。
Geometry Branch - Order Segmentation($S(w,h,N)$)
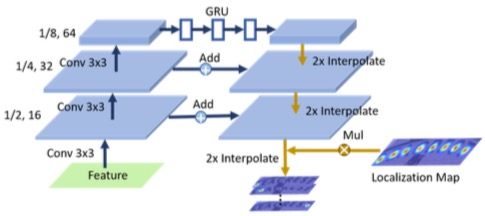
这个是最复杂的一个了。
这个很像一个U-Net,3个上卷积(越卷越小):上卷积变成1/2大小,16应该是卷积核,也就是输出的通道数;然后再来,1/4,32;1/8,64。 为什么会变小?我猜可能是stide是(2,2)的原因吧???
然后过一个RNN,维度不变,这个RNN应该隐层个数应该是64,这样才可以保持输出通道数不变。 RNN这块,需要把[h,w,c]=>[w,h*c],主要是为了让他成一个保持左右顺序的序列。
然后再下卷积(越卷越大),第1、2下卷积的后,要融合一下左面上卷积的结果后。 上采样,融合,上采样,融合,上采样,融合,上采样,最后得到一个feature map,大小应该是原图的大小w,h,但是channel数多少,这个可能得自己设计。 但是,在输出之前,得过两个卷基层,然后输出(w,h,N)的结果。最后这个N,是可以由最后一个卷积核的个数的来控制的。
Following the upsampling path, two convolutional layers are employed to generate the order segmenta- tion maps S。
最后把S(w,h,N)softmax一下。
接下来,要计算Order Map(H)了:
就是把Localitation Map(S - w,h,N)和 Order Segmentation(Q - w,h),两个东西做element-wise乘法,就是对应位置相乘, 成完后,你就得到了N个 w,h的 feature map。也就是H。其中每个w,h形状的图,就是上图中说的$H_k \in (1,N)$。
这里有个细节, Order Segmentation(Q - w,h)是经过sigmoid计算的,Localitation Map(S - w,h,N)是经过softmax计算的, 他们相乘了,得到了的数应该会非常小,比如在某个点上,sigmoid计算的Q的值,softmax计算的S值,相乘,会变成更小的一个数。
然后,就得到了Order Maps的热力图H(h,w,N)
Order Map - H(h,w,N)
这个图表示了啥含义?
还记得前面说过,Order Segmentation(S)代表字符的顺序号,Localization Map(Q)代表一个点是不是文字,那两个“合体”后呢?
每张热力图 Order Map $H_k$就对应一个位置,这张$H_k$里面的像素,就表示这个像素上,是不是一个文字点。
最后大合体 Word Formation了
最后,我们还差是哪个字符的信息,他在 Charactor Segmentation(G)中,所以,要在再做一次element-wise(就是对应像素)的乘,这次相乘的是G和$H_k$,挨个乘,得到N张图。
N就是字符的个数,论文里面是提到了N是设成30,也就是最多支持30个字符。
最最最后,我们对每张(注意!是每张),做一个积分:
$p_k = \int_{(x,y)\in\Omega} G(x,y) * H_k(x,y)$
来,观察这个积分,特别神奇:
$G(x,y)$是一个$(h,w,C)$的东东,是个三维的,而$H_K(x,y)$是一个一维的,你是把要把这个一维的和三维的相乘后,求积分,就是求和啦,得到一个数,是一个概率值。
发挥你的想象力,$H_k$表示的是第k个位置的情况,里面的点上是sigmoid概率值,是不是前景的值,你可以理解成一个蒙版,蒙在$G$上,关键的来,G是啥来着? G是每个点可能是某个字符的概率呀,你$H_k$虽然给我规定了很多前景的点,但是这些点不一定都是一个字符,所以这个你求的时候,是大家相当于一起来投票一样。
最终,你得到的是一个维度为C(字符集个数)的概率向量,是不是归一化,我有点想不清楚了,但是看论文上说的意思,应该是。
然后你挑一个最大的,就是这个位置上,的字符。
2020.6 补充
在我看来,Word Formation,才是这个算法的灵魂。
这个算法,最终就是要的结论是:在对应位置上的那个字符到底是谁?
Word Formation确定的顺序就是字符的顺序。
而那个积分概率$p_k$,就是最终字符的概率,想想,这个$p_k$的维度是多少?答案是,字符集的个数。
再来看看这个公式:$p_k = \int_{(x,y)\in\Omega} G(x,y) * H_k(x,y)$
$G维度是[H,W,C], H_k维度是[H,W,1]$,他们相乘后,得到的是维度是$[H,W,C]$,C就是字符集的个数,然后通过积分,也就是$\sum$,最终消掉了H和W,最终剩下的只有C。 所以,你最终得到的是一个维度为C的概率向量。
关于损失函数
第四页的公式(4)给出了损失函数:
\[L=\lambda_l * L_l + \lambda_o * L_o + \lambda_m * L_m + L_s\]好,我们分解开每个子loss,挨个说:
第一个:$L_l$,对应着localization map(Q)的损失,那么localization map是啥来呢?再回忆一下,是这个点是不是文本的概率。
第二个:$L_o$,对应的是Order Map(H)的损失,order map是啥来着?回忆一下,是每个位置上,对应的每个点是文本的概率。
第三个:$L_m$,是互训练的时候的损失,后面会详细研究
第四个:$L_s$,对应的是Sgementation Map(G)的损失,segmentation map是啥来着?回忆一下,是每个像素,是某个汉字的概率。
好了,我们看到,这些都是概率,还是有的是多分类,所以,损失函数就大多用了交叉熵,如$L_s$和$L_o$,不过$L_l$换成了L1 smooth,这个细节需要注意,不过我觉得其实用交叉熵也没啥问题。
关于训练样本
好,上面说了损失函数,那么就要对应的提供样本GT了。
我们看到,我们有$L_l$、$L_o$、$L_s$要计算,就意味着我们有3种GT样本需要制作,怎么制作呢?我们一个个的说。
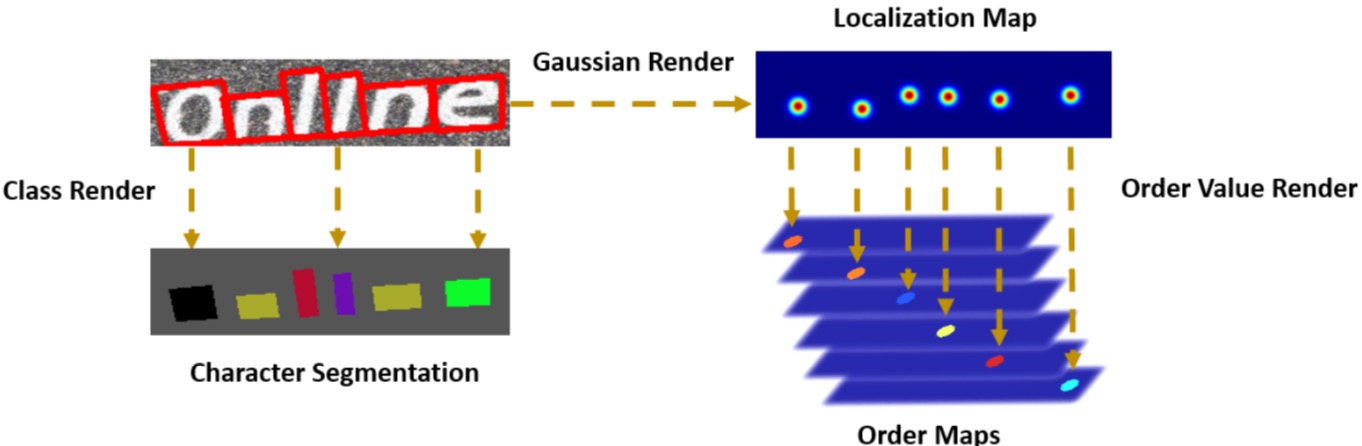
- 先说说$L_s$需要的GT,即Character Sgementation(G)的GT:
Inside P’area,the class of the corresponding character is rendered as ground truth of the character segmentation.
其实就把标注的单字的标注框,shrink一下,然后得到的多边形里面,都填充成对应的字符,就得到了Character Segmentation的GT。当然,真正计算的损失的时候,还需要把这个字符转成one-hot向量。
实际得到的GT是一个(H,W,C+1),C是字库字符数,+1是要算上背景,且第三个C维度是一个one-hot编码的张量。
-
然后说说$L_o$所需要的GT,也就是Order Map(H),准确的是说,是每一个$H_k$的GT。
吐槽一下,这块论文里写的确实太晦涩了,真心看不懂,想了半天也没想清楚,情不得已,不得不向何明航同学请教,在他的帮助下,终于搞清楚了。
先看原文:
To generate the ground truth of order maps with character-level annotations, the center of Gaussian maps is firstly detected by computing the central points of characters bound- ing boxes. As Fig. 4 shown,2D Gaussian maps $\hat{Y}_k \in R^{h×w}$ with σ and expectation at central points are generated for each character. Then the order of characters is rendered for pixels inside $\hat{Y}_k$ area. Finally $\hat{Z}_k$ is normalized to [0, 1], to produce the ground truth $Z_k$ of $H_k$.
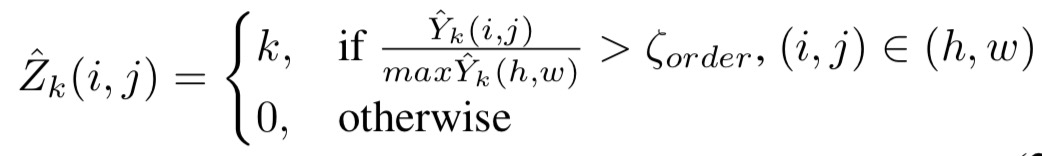
有几处让人糊涂的地方:高斯分布,是用高斯方式采样一些样本点么?如果是一堆点的集合,那文中提到的$\hat{Y}_k$是点集么?那$\hat{Y}_k$的值又指的是什么?像素值么?$\max\hat{Y}_k$是像素值最大的值么?后面还提到要把$\hat{Z}_k$归一化,可是$\hat{Z}_k$的值都是k,怎么归一化?难道变成均匀分布的概率值?
带着这些问题,请教了何明航,终于得到了合理的解释:
最核心的是$\hat{Y}_k$的理解,它其实是一个高斯过滤图:
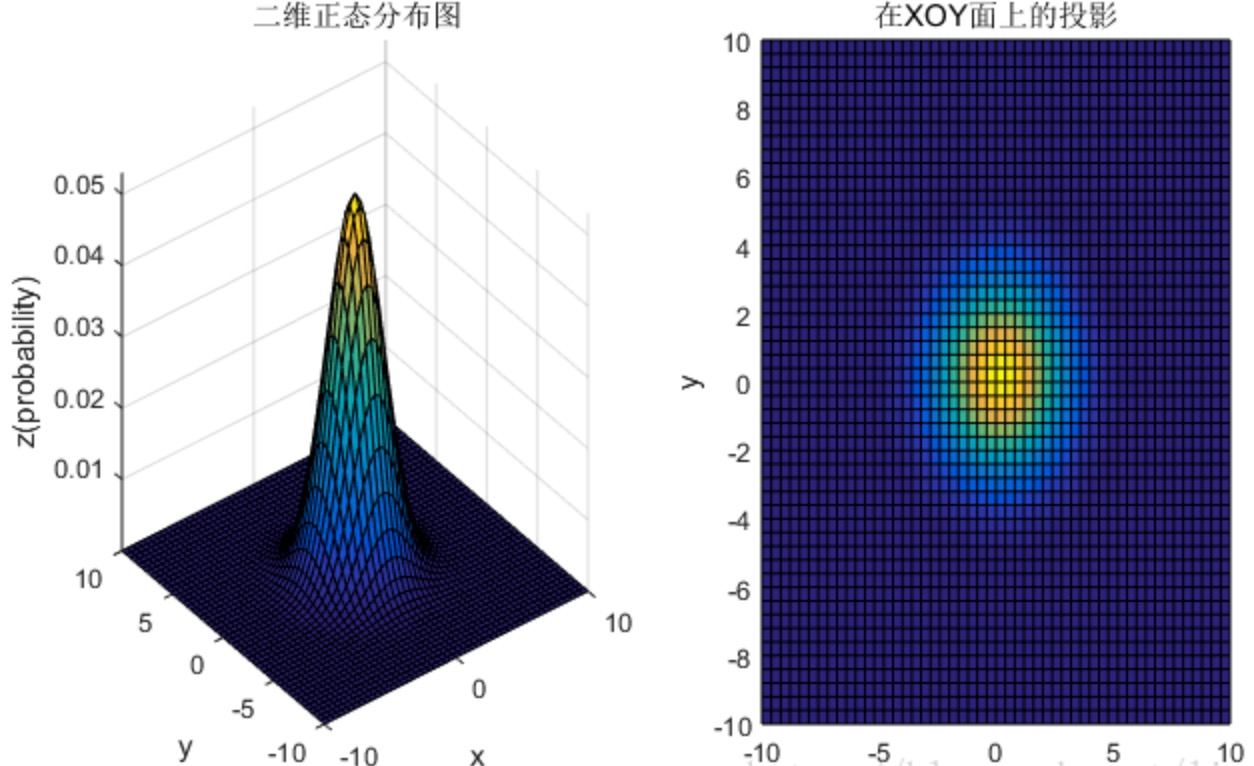
他的值,其实就是概率密度函数的值,是一个概率值,凡是值比最大值小于0.5的点,值都被强制归0(就是上述公式里的处理)。 因为这些概率值都非常小,所以要做一个归一化(上面提到的)的动作,把值变到[0~1]之间,这个归一化动作也是有意为之的,因为,在Order Maps中的某个$H_k$,对应的区域就应该是文字区域,且这个区域表达的是“是前景文字的概率”,所以,归一化正好是为了满足这点。
这里我们需要思考一下,为何要这样做?也就是这个GT的insight:
前面提过,每个$H_k$对应是第几个字符的中心位置,按理说,应该是一个像素的位置值作为GT。但是,这里的设计是,用一个均值在这个字符的中心位置(方差是超参),来表达这个中心位置,这样做,我觉得,可能是因为文字块是一个区域,用一个正态分布来表示这个区域,越靠近中心区域给的权重越高。在网络预测时候,尽量让这个中心点预测为前景(文字)的概率最大,然后越往周边,预测为前景(文字)的概率逐渐decay,这样个设计,来帮助“确定”字符的中心区域。“对!用一种正态分布的方式来表达字的中心位置!”
再回忆一下论文中提到过,$H_k=S_k*Q$,$S_k$是order segement图[H,W,K]在axis=2上的切片,也就是对应的概率值(按照类别K进行softmax归一化的),这个切片图$S_k$然后要和一个$Q$相乘,$Q$是一个[H,W,1],每个点的值是[0~1]的概率值,是经过sigmod计算后的,这样的两个数相乘,得到了$H_k$,所以$H_k$的数都是特别小的数。现在,我们就是要做这个特别小的值的$H_k$的样本来了。
理论上,在每个Order Segmentation的$S_k$对应的图上,第k个字符的那些点的标签的GT,softmax值都应该是1;而Localization Map($Q$)的GT现在被我们把表示成了“正态分布归一化”的图。现在这两者相乘,也就是去模拟论文里$H_k=S_k*Q$的计算的话,那其实就是每个字符的“正态分布归一化”就是了。
这里,我是觉得论文的“《Label Generation》”的式(2)中,将$\hat{Z}_k = k$,这个赋值就很无厘头了,而且,后面论文也说了,要讲这个$\hat{Z}_k$还要归一化,就更说明这个式子是有问题的,其实,在我理解,就应该是归一化后的值,也就是$\frac{\hat{Y}_k}{max\hat{Y}_k}$
-
有了每个Order Map的每个$H_k$的GT,就可以制作Localization Map(Q)的GT了
其实就是把各个$H_k$合成到一起,不过细节上还是有些不太一样。
实现上,是把$\hat{Y}_k$归一化后(注意噢!要归一化),合并到一起,而不是直接$Z_k$合并到了一起。还记得$\hat{Y}_k$和$\hat{Z}_k$的区别么?$\hat{Z}_k$是去掉了一些概率值比较小点而已。
2020.7.3更新
实现过程中,还是有一些问题,必须要再捋一捋:
互训练(Mutual Train)
不是所有的标注都是有字符级别的bounding box的,成本太高,大部分的样本是只有一个字符串。 这种情况下,就可以考虑论文里说的互训练方式。
字符串样本,至少提供了两个信息:字符的顺序,以及字符是什么。能不能利用这些信息来训练网络呢?
答案是可以的。
预测后的点(是某个字的点,是第几个位置的点)
Character Segmentation网络预测出一个$\hat{G}$,这个预测是每个像素是啥字符。如果我的这个字符串里的每个字符都是唯一的话,
而Order Map,吐出来的$\hat{H}$(这里直接略过Localization Map:Q,和Order Segmenation:S),直接把两者结合(就是element-wise乘)的结果H拿出来了,这个预测是每个顺序上都有那些点是文字前景。
好,这个时候,结合这两个$\hat{G}$和$\hat{H}$信息,我们可以通过下面这个式子,得到了一些点:
$\Psi_h^k={(i,j)|\hat{H}(i,j)=k,Q(i,j)>\epsilon}$
$\Psi_g^k={(i,j)|\hat{H}(i,j)=k,G(i,j)>\epsilon}$
$\epsilon$=0.2
这里,用到了Q,Q是啥来着,是图片上的点是前景的概率,只有是前景概率>0.2的点,我才采用。
再通俗一点解释,
$\Psi_h^k$,就是拿着某个位置的汉字,去找这个对应位置的$H_k$图,然后根据Q的阈值,找出来是文字的点。
$\Psi_g^k$,就是拿着某个位置的汉字,去G中去找那些是这个汉字的点,然后再依据Q的阈值,找出这些点。
好,拿到这些点了,我们就可以算出两个损失:
用这些点,相互校验,算损失
我们会算用预测位置的$H_k$点(它可以确定是哪个字),去$G$中找到对应的点,来算这些点的损失。
我们会算用每个字,去找出$G$中这个字对应点,这些点是可以确定顺序的(因为标签字符串中这个字在第几个可以确定),来去找到对应位置为k的$H_K$中的点的损失。
$L_g^k=\frac{1}{| \Psi_h^k |} \sum\limits_{(i,j)\in \Psi_g^k} L_{CE}\Big\lgroup G(i,j),onehot(T(k))\Big\rgroup$
$L_h^k=\frac{1}{| \Psi_g^k |} \sum\limits_{(i,j)\in \Psi_h^k} L_{CE}\Big\lgroup G(i,j),onehot(T(k))\Big\rgroup$
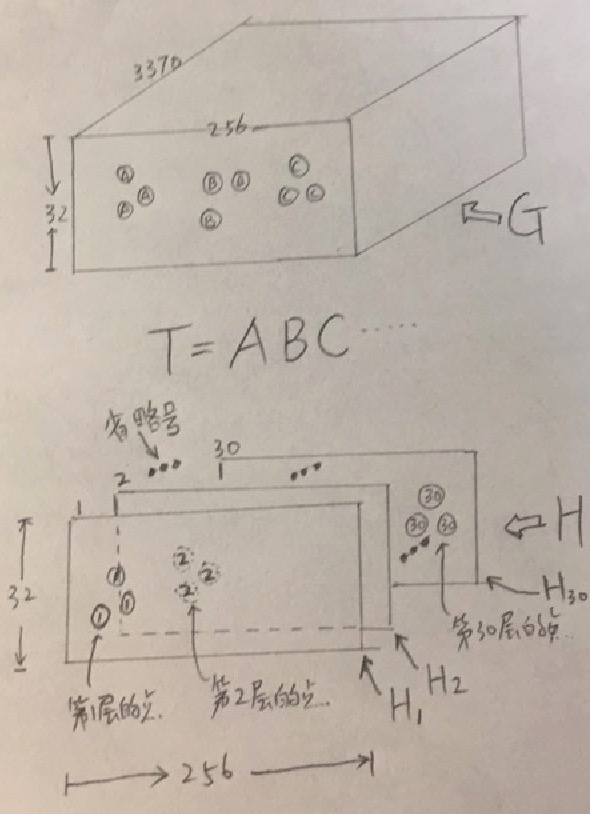
为了更理解清楚讲清楚这事,我手工撸了图,可以更清晰的理解这事。
T是字符序列。
上面的图,是我预测出来G的每个像素点是哪个汉字的softmax概率(是个3370字库概述的巨大的多维概率分布噢)。
下面的图,是我预测出来每个$H_k$,一共有30个,代表最多30个字符,但是每个$H_k$上只有零星的一些点,表示这些像素组成了第k个字符,而且这些点是呈一个正态分布的,其均值位置就是汉字的中心。
看这上图,我们来详细说一下第一个算$L_g^k$式子:
$L_g^k=\frac{1}{| \Psi_h^k|} \sum\limits_{(i,j)\in \Psi_g^k} L_{CE}\Big\lgroup G(i,j),onehot(T(k))\Big\rgroup$
求$L_g^k$,可是,他居然出了一个下标是h的$ | \Psi_h^k | $,为何是拧着的呢? 这个细节很重要。$L_g^k$是啥损失,是识别是哪个字符的损失计算。
他用的是哪些点?他用的是$H_k$,即那些第k位置,是前景的点。
把这些$H_k$上的点,找到其对应的$G$上的点,G上的点是啥来?是哪个字符的softmax概率。 所以,用$T(K)$,即字符的one-hot表示,做一个交叉熵,算出损失。
最后除以$| \Psi_h^k|$做一个均一化,算是平均损失。
我们回顾一下,我们用在$H_k$中点,算了G中的损失,所以这种交叉玩法,就是论文里管他叫“相互训练 - mutual supervision training”的缘故。
再说第二个算$L_h^k$式子:
$L_h^k=\frac{1}{| \Psi_g^k|} \sum\limits_{(i,j)\in \Psi_h^k} L_{CE}\Big\lgroup G(i,j),onehot(T(k))\Big\rgroup$
同上,这个是从G图中,找出样本中是第k位置的汉字,然后用这个汉字,去反向筛出来G中的那些是这个字的点。
然后拿着这些点,回到$H_k$中,与那些对应的点,算交叉熵。这些点的GT值是一个维度为N(30)的one-hot向量。
提高置信度
无论是$\Psi_h^k$,还是$\Psi_g^k$,都是需要被Q(是不是文字前景,而且不会太多,只会是以文字中心为均值的正态分布)的阈值给筛选掉很多。所以,如果剩下的就没几个点了,你的预测估计也不太靠谱了。
所以,要衡量你的置信度,可以用这个筛选下来的点的数量来当做置信度,来调节损失函数中的“贡献”,置信度低,计算损失的时候,权重就给小点。
我们来算算G图上,某个字的置信度$\Phi_g$:
\[n_g^k= \left\{ \begin{array}{l} 1 , \quad if \quad \Psi_g^k \ne \emptyset, \\ 0 , \quad otherwise \end{array} \right.\] \[\Phi_g = \frac{\sum_{k=1}^{\|T\|} n_g^k}{\|T\|}\]我们来算算$H_k$图上,是这个位置的点的置信度$\Phi_g$:
\[n_h^k= \left\{ \begin{array}{l} 1 , \quad if \quad \Psi_h^k \ne \emptyset, \\ 0 , \quad otherwise \end{array} \right.\] \[\Phi_h = \frac{\sum_{k=1}^{\|T\|} n_h^k}{\|T\|}\]最后,终于可以计算$L_m$了
算一下G的损失:
$L_g=\frac{(\Phi_h)^\gamma}{|T|} \sum\limits_{k=1}^{|T|} L_g^k$
$\gamma=2$,$\gamma$是次方,不是简单的相乘啊,别看错了。
算一个H的损失:
$L_h=\frac{(\Phi_g)^\gamma}{|T|} \sum\limits_{k=1}^{|T|} L_h^k$
最后合到一起:
$L_m=L_h + \lambda * L_g$
$\lambda=0.2$
参考
附录:优秀的OCR分享
跟文章主题无关,不过,顺道揉到此贴中吧,都是网上优秀的OCR的分享。
- 腾讯云上的一个OCR培训 ,一位女工程师讲的。
- July七月的OCR识别课程,
- 阿里读光OCR负责人的分享,剔除了低频字识别的方法
- 旷视的姚聪的视频的分享
- 旷视最近的一个分享
- 百度小哥的一个分享
- Valse的学术视频,对应的ppt
- 白翔老师的的一系列文章分享:
- 更早的一个OCR分享,不过有点老2014的,参考用。
- CSIG文档图像分析与识别专委会,这个公众号非常赞
- SFFAI58-文本识别专场,讲了TextScanner,白翔的学生讲的
- 金连文-基于深度学习的文字识别
- 旷视x北大《深度学习实践》之文本识别,姚聪讲的,2节课,很系统