
前言
作为计算机专业的人,最遗憾的就是上编译原理的那学期被老师拉去干活了,没上成。所以,对一个程序怎么就从源代码变成了一个在内存里活灵活现的进程,一直心怀好奇。这种好奇,一直驱使我,要找个机会深入了解一下。所以,就写下此贴,督促自己深入研究一下。不过,这篇帖子没有深入研究编译原理、操作系统原理这些内容,而是主要聚焦在程序的链接和加载这两个主要话题。
研究程序的链接和加载,主要就参考三本书、一个视频、一个音频,这些内容,都在后面参考都列出了。三本书里,最主要还是《程序员的自我修养 - 链接、装载与库》,里面涉及到的代码我放到了我的github上,并且配有shell脚本和说明,运行后可以实操理解到更多内容。另外,南大袁春风老师的计算机原理讲解,对我帮助也很大,你知道,视频还是最直接可以传达知识的方式。另外,为了方便自己的实验,我还制作了一个ubuntu的docker环境,并且内置了代码和环境,方便实验: 阿里docker镜像,也欢迎拉取玩耍。
docker pull registry.cn-hangzhou.aliyuncs.com/piginzoo/learn:1.0
概述
每天,无数的程序,他们被写出来,编译出来,部署上去,不停的跑着,他们干着千奇百怪的事情,可是,就像这个千奇百怪、光怪陆离的世界一样,是由每个人、每个个体组成的,如果我们剖析每个人,发现他们其实都是一样的结构,都是由细胞、组织组成,再深究,便是基因了,DNA里面的那一个个的“核苷酸基”,决定了他们。
同样,通过这个隐喻来认知计算机,我们可以知道,计算机的基因和本质就是冯诺依曼体系,啥是冯诺依曼体系呢,通俗的讲,就是定义了整个硬件体系(CPU、外存、输入输出),以及取指执行的运行流程等等。可是,到底一个程序,如何与硬件亲密无间的运行起来了呢,应该是很多人不了解的,甚至包括许多计算机专业的同学们。
本质上来讲,这个过程其实就是一个“从代码编译成目标文件、然后不同目标文件链接到一起成为可执行文件,最终讲可执行文件加载到内存中,被操作系统管理起来的一个进程,可能还会动态的再去链接其他的一些程序(如动态链接库)”,但是,每个部分都隐藏着很多很多细节,好奇心很强的你,一定想知道,到底计算机怎么做到的。
我们这片帖子不打算讨论硬件、进程、网络的这么庞大的体系,我们就聚焦在程序的$\color{red}{链接和加载}$,这两个主题,当然,这已经很大了。
来吧,我们来一起探索吧。
基础
虽然我们只聚焦在链接和加载,但是,还是需要把一些基础知识交代一下的,否则,是无法理解链接和加载的。
硬件基础
先说说硬件吧,
首先就是CPU:
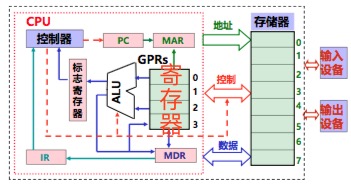
CPU由一大堆寄存器,还有算数逻辑单元(就是做运算的),还有控制器组成,每次,通过PC(程序计数器,存着指令地址)寄存器,去内存里去寻址可执行二进制代码,然后加载到指令寄存器里,然后涉及到地址的话,再去内存里去加载数据,计算完,再写回到内存里。每条指令都会放到指令寄存器(IR)中,等着CPU去取出来运行。指令哪里来的?是从硬盘加载到内存里,又从内存里加载到IR里面的。指令运行过程中,需要一些数据,这又要求从内存里取出一些数据,放到通用寄存器中,然后交给ALU去运算,结果出来,又会放到寄存器或者内存中,周而复始。
每一步都是一个时钟周期,现在的CPU一秒钟可以做1G次,是1000000000,几十亿次/秒,不过,这也就到头了,现在市场上的CPU主频据说到了4GHz就到头了,限于工艺,上不去了,所以就慢慢转多核了,就是把几个CPU封装到一起卖了,并行之。我看看我笔记本上,服务器上,都是2.5-3GHz的,现在卖的多核,其实就是处理器多个,共享一下内部缓存,打包在一起。
然后,是主板了:
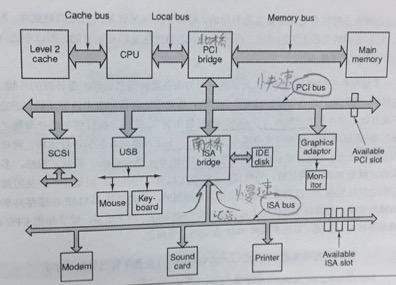
如图,我们看到了,我们经常听说的“北桥、南桥”,他们是啥?
北桥其实就是一个计算机结构,准确说的是一个芯片,它连接的设备都高速设备,通过PCI总线,把cpu、内存、显卡串在一起,他的亲戚都是高速设备;而南桥就要慢很多了,都是鼠标、键盘、硬盘等这些“穷慢”亲戚,他们之间用ISA总线串在一起。
硬盘呢,
硬盘硬件上是盘片、磁道、扇区这样的一个结构,太复杂了,所以,从头到尾,给这些扇区编个号,就是所谓的“LBA(Logical Block Address)”的一个逻辑扇区的概念,方便寻址。
为了隔离,每个进程有一个自己的虚拟地址空间,然后想办法给他映射到物理内存里,但是内存不够怎么办?就想到了再细分,就是分页,分成4k的一个小页,常用的在内存里,不常用的交换到磁盘上。这就要经常用到地址映射计算(从虚拟地址到物理地址),这个工作就是MMU(Memory Management Unit),这玩意为了快都集成到CPU里面了。
最后,说说输入输出设备
还有好多外设,他们负责输入输出,他们一旦被外界输入东西,或者要输出东西,就要得去告诉CPU,告诉他“我有东西了,来取吧”,“我要输出啦,来帮我输出吧”,这事就要靠一个叫“中断”的机制了,你可以理解中断就是一种消息机制,用于通知CPU,来帮我干活。当然,也不是人人都可以直接骚扰CPU的,他们都要通过中断控制器来集中骚扰CPU的。
这些外设,都有自己的buffer,这些buffer也得有地址吧,这个地址叫端口。
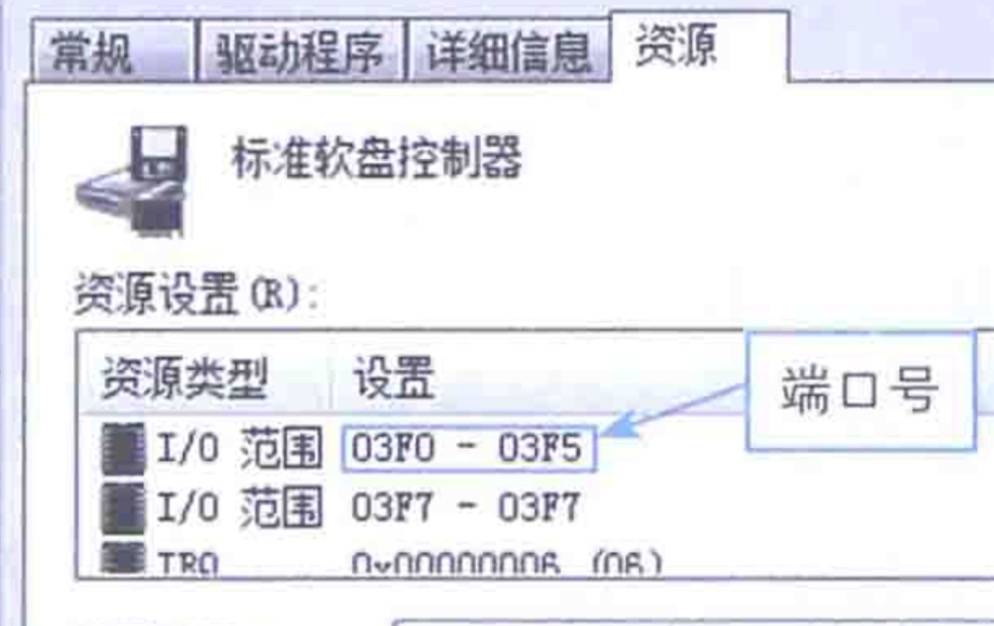
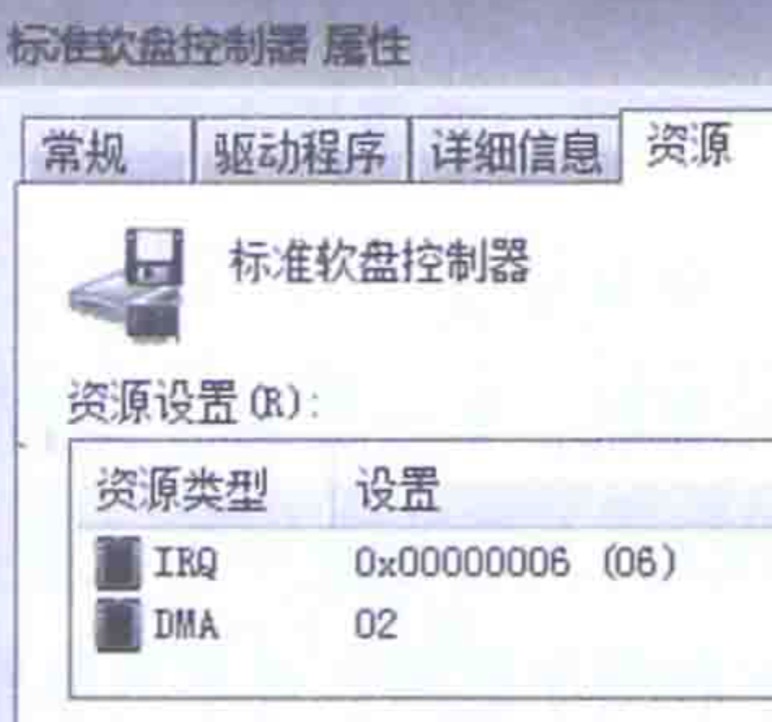
还得给每个设备编个号,这样系统才能识别谁是谁,每次中断,CPU一看,噢,原来是05,05是键盘啊,06!06是鼠标啊。这个号,叫中断编号(IRQ)。
每次都要骚扰CPU,非要这样么?可以直接把数据从外设的buffer(端口)里,直接灌到内存里,不用CPU参与,多好啊。对,这个做法就是DMA。每个DMA设备也得编个号,这个编号就是DMA通道,这些号可不能冲突啊。
汇编基础
对于汇编,我其实也忘光了,所以得补补汇编知识了,起码能读懂一些基础的汇编指令。
汇编语法
汇编分门派呢!”AT&T语法” vs “Intel语法”:GUN GCC使用传统的AT&T语法,它在Unix-like操作系统上使用,而不是dos和windows系统上通常使用的Intel语法。
最常见的AT&T语法的指令:movl %esp, %ebp,movl是一个最常见的汇编指令的名称,百分号表示esp和ebp是寄存器,在AT&T语法中,有两个参数的时候,始终先给出源(source),然后再给出目标(destination)。
AT&T语法:
<指令> [源] [目标]
寄存器
寄存器是干嘛的?就是放着各种给cpu计算用的地址啊、数据用的,可以认为是为CPU计算准备数据用的。一般,分为8类:
| 累加寄存器: | 存储执行运算的数据和运算后的数据。 | 就是放计算用的数,算之前,算完后的 |
| 标志寄存器: | 存储运算处理后的CPU的状态。 | 一般溢出啊,或者JMP的时候看条件用的 |
| 程序计数器: | 存储下一条指令所在内存的地址。 | 存着指令的地址,读他才能找到代码在哪,代码寻址用的 |
| 基址寄存器: | 存储数据内存的起始地址。 | 读内存用的,不过只放起始地址,寻址用的 |
| 变址寄存器: | 存储基址寄存器的相对地址。 | 读内存用的,不过只放偏移地址,寻址用的 |
| 通用寄存器: | 存储任意数据。 | 这个是放任意数据用的,我怎么觉得累加寄存器有点鸡肋了,用它不就得了 |
| 指令寄存器: | 存储指令。CPU内部使用,程序员无法通过程序对该寄存器进行读写操作。 | 存执行指令用的 |
| 栈寄存器: | 存储栈区域的起始地址。 | 寻址用的,永远指着当前栈的栈顶地址(内存的) |
命名
命名上,x86一般都是指32位;x86-64一般都是指64位。32位寄存器,一般都是e开头,如eax,ebx;64位寄存器约定上都是以r开头,如rax,rbx。
32位寄存器
32位CPU一共有8个寄存器
| %eax | %ebx | %ecx | %edx | %esi | %edi | %ebp | %esp |
详细的介绍
| %eax | 累加器(Accumulator),用累加器进行的操作可能需要更少时间。可用于乘、 除、输入/输出等操作,使用频率很高; |
| %ebx | EBX称为基地址寄存器(Base Register)。它可作为存储器指针来使用 |
| %ecx | ECX称为计数寄存器(Count Register)。 在循环和字符串操作时,要用它来控制循环次数;在位操作中,当移多位时,要用CL来指明移位的位数; |
| %edx | EDX称为数据寄存器(Data Register)。在进行乘、除运算时,它可作为默认的操作数参与运算,也可用于存放I/O的端口地址。 |
| %ebp | EBP为基指针(Base Pointer)寄存器,一般作为当前堆栈的最后单元,用它可直接存取堆栈中的数据; |
| %esp | ESP为堆栈指针(Stack Pointer)寄存器,用它只可访问栈顶。 |
| %esi/%edi | ESI、EDI为变址寄存器(Index Register),它们主要用于存放存储单元在段内的偏移量, 它们可作一般的存储器指针使用。 |
64位寄存器有:32个
| %rax | %rbx | %rcx | %rdx | %rsi | %rdi | %rbp | %rsp | %r8 | %r9 | %r10 | %r11 | %r12 | %r13 | %r14 | %r15 |
两者的区别:
1、64位有16个寄存器,32位只有8个。但是32位前8个都有不同的命名,分别是e _ ,而64位前8个使用了r代替e,也就是r 。e开头的寄存器命名依然可以直接运用于相应寄存器的低32位。而剩下的寄存器名则是从r8 - r15,其低位分别用d,w,b指定长度。
2、32位使用栈帧来作为传递的参数的保存位置,而64位使用寄存器,分别用rdi,rsi,rdx,rcx,r8,r9作为第1-6个参数。rax作为返回值
3、64位没有栈帧的指针,32位用ebp作为栈帧指针,64位取消了这个设定,rbp作为通用寄存器使用
4、64位支持一些形式的以PC相关的寻址,而32位只有在jmp的时候才会用到这种寻址方式。
对了,寄存器可不是L1、L2 cache啊!Cache位于CPU与主内存间,分为一级Cache(L1 Cache)和二级Cache(L2 Cache),L1 Cache集成在CPU内部,L2 Cache早期在主板上,现在也都集成在CPU内部了,常见的容量有256KB或512KB。寄存器很少的,拿64位的来说,也就是16个。64x16,算算,也就是1024,1K啊。
总结:大致来说数据是通过内存-Cache-寄存器,Cache缓存则是为了弥补CPU与内存之间运算速度的差异而设置的的部件。
寻址方式
接下来说说寻址,啥叫寻址?就是告诉CPU去哪里去取指令、数据,总得有个地址啥的把,对,这个机制就是寻址。
比如movl %rax %rbx,这个涉及到寻址,寻址会寻“寄存器”、“内存”,会直接暴力的直接寻址,也可以是委婉的间接寻址,下面是各种寻址方式:
| 寻址模式 | 示例 | 说明 |
| 全局符号寻址(Global Symbol) | MOVQ x, %rax | |
| 直接寻址(Immediate) | MOVQ $56, %rax | 直接把56这个数搬到rax寄存器 |
| 寄存器寻址(Register) | MOVQ %rbx, %rax | 把rbx里面的值,搬到rax中 |
| 间接寻址(Indirect) | MOVQ (%rsp), %rax | rbx里是个地址,按照这个地址寻址后的数,搬到rax中 |
| 相对基址寻址(Base-Relative) | MOVQ -8(%rbp), %rax | rbx里是个地址,按照这个地址寻址后,再回退8个位置,那个位置里的数,搬到rax中 |
| 相对基址偏移缩放寻址(Offset-Scaled-Base-Relative) | MOVQ -16(%rbx,%rcx,8), %rax | 妈呀,地址是:指地址-16 +%rbx +%rcx * 8,然后到里面找到值,搬到rax里 |
另外,你可能会看到这种指令movl,movw,mov后面的l、w是什么鬼?
| 前缀 | 全称 | Size |
| B | BYTE | 1 byte (8 bits) |
| W | WORD | 2 bytes (16 bits) |
| L | LONG | 4 bytes (32 bits) |
| Q | QUADWORD | 8 bytes (64 bits) |
就是一次你搬运的数据数量。
常用的指令
好,最后说说指令本身,每个CPU类型,都有自己的指令集,就是告诉CPU干啥,比如是加、减、移动、调用函数啥的。下面是一些非常常用的指令:
| 操作码 | 操作数 | 功能 |
| movl | A,B | 把A赋给B |
| and | A,B | A=A+B |
| push | A | 把A压栈 |
| pop | A | 出栈结果赋值给A |
| call | A | 调用函数A |
| ret | 无 | 将处理结果返回函数的调用源 |
参考:
这篇汇编入门的小文写的很不错,推荐读读x86-64汇编入门,另外,愿意自虐的同学,可以下载Intel官方的指令集手册仔细研读。
一些工具和玩法
这篇文档还会涉及到一些工具,这里列一下,大家可以尽情玩耍一下他们~
- gcc:超级编译工具,可以做预编译、编译成汇编代码、静态链接、动态链接,啥都能干,本质上是各种编译过程工具的一个封装器。
- gdb:太强了,命令行的调试工具,简直是上天入地的利器。
- readelf:过于牛逼,可以把一个可执行文件、目标文件底裤完全拔掉,让你观瞧
- objdump:跟readelf功能差不多,不过貌似他依赖一个叫“bfd库”的玩意,我也没研究,另外,他有个readelf不具备的功能,就是反编译。剩下的两者都差不多了。
- ldd:这个小工具也很酷,可以让你看一个动态链接库文件依赖于哪些其他的动态链接库。
cat /proc/<PID>/maps:这个命令很有趣哈,可以让你看到进程的内存分布。
还有各种利器,自己去探索吧。
其他
地址编码
假如有个整形变量1234,16进制是0x000004d2,占4个字节,比如是起始地址是0x10000,那么终止地址是0x10003,那么在外界看来,是0x10000还是0x10003是他的地址呢?答案是,小地址是,即0x10000是他的地址。
那接着问题来了,这个4个字节里面,怎么放这个数?高地址放高位,还是低地位放高位?答案是,都可以!
大端方式:高位在低地址,如 IBM360/370,MIPS:
| 0x10000 | 0x10001 | 0x10002 | 0x10003 |
| d2 | 04 | 00 | 00 |
小端方式:高位在高地址,如 Intel 80x86
| 0x10000 | 0x10000 | 0x10000 | 0x10000 |
| 00 | 00 | 04 | d2 |
就是这么变态,呵呵。
编译
接下来,说说编译吧,由于我没学过编译,其实我对词法分析、语法分析也不甚了解,找机会再深入吧,这里只是把大致知识梳理一下。
词法分析->语法分析->语义分析->中间代码生成->目标代码生成
-
首先是$\color{red}{词法分析}$,通过FSM(有限状态机)模型,说白了,就是按照语法定义好的样子,挨个扫描源代码,把其中的每个单词和符号,都给他做个归类,比如你是关键字、你是标识符、你是字符串还是数字的值等,然后把大家都分门别类的放到各个表中(符号表、文字表)。如果你不符合语法规则,那么对不起,词法分析过程中,就会给出各类警告,咱们编译过程中看到的很多语法错误,就是它干的。有个开源的lex的程序,可以搞来玩玩,体会一下这个过程。
-
词法分析后,就是$\color{red}{语法分析}$了,由词法分析的符号表,要形成一个抽象语法树,方法是“上下文无关语法(CFG)”。这过程,就是把程序表示成一棵树,叶子节点就是符号和数字,自上而下组合成语句,也就是表达式,层层递归,从而形成整个程序的语法树。同上面的词法分析一样,也有个开源项目,可以帮你做这个树的构建,就是yacc(Yet Another Compiler Compiler)。
-
接下来是$\color{red}{语义分析}$,这个步骤,我理解要比语法分析工作量小一些,主要就是干一些类型匹配、类型转换的工作,然后把这些信息更新到语法树上。
- 再往下是$\color{red}{中间语言生成}$,干嘛呢?就是把抽象语法树,转成成一条条顺序的中间代码,这种中间代码,往往采用一种叫三地址码或者P-Code的格式,形如
x = y op z,长成这个样子:t1 = 2 + 6 array[index] = t1不过这些代码,是和硬件不相关的,还是“抽象”代码。
- 最后终于到了$\color{red}{目标代码生成}$了,就是把中间代码,转换成目标机器代码,这就需要和真正的硬件和操作系统打交道了,要按照目标CPU和操作系统,把中间代码翻译成符合目标硬件和操作系统的汇编指令,而且,还要给变量们分配寄存器、规定长度啥的了,最后得到了一堆汇编指令。 对于整形、浮点、字符串,都可以翻译成,把几个bytes的数据初始化到某某寄存器中,但是对于数组啊,其他的大的数据结构,就要涉及到为它们分配空间了,这样,才可以确定数组中某个index的地址啊,不过,这事儿,编译不做,留给链接去做。
编译不是这篇帖子的重点,这里就不过多讨论了,那也是个一大坨的东西,有机会再开个帖子讨论编译原理吧!感兴趣的同学,可以读读这篇:《自己动手写编译器》。
链接
编译一个c源文件代码,就对对应得到一个目标文件。一个项目中会有一堆的c源代码,编译后会得到一堆的目标文件。这些目标文件是二进制的,就是一堆0、1的集合,到底这一堆0、1是如何排布的呢,接下来,我们得说一说,这些0、1组成的目标文件了。
目标文件
目标文件是没有链接的文件(所谓链接,就是指一个目标文件,可能会依赖其他目标文件,把他们“串”起来的过程,就是链接)。这些目标文件,已经和这台电脑的硬件和操作系统相关了,比如寄存器、数据长度,但是,对应的变量的地址没有确定。目标文件里面有啥呢?有数据、有机器指令代码,还有符号表(符号表就是你源码里面那些函数名、变量名和代码的对应关系,我们后面会细讲)和一些调试信息。
目标代码总得有个结构吧,是的,这结构是依据一个叫COFF(Common File Format)的规范。Windows和Linux的可执行文件(PE和ELF)就是尊崇这种规范。大家用的都是COFF格式,甚至动态链接库也是。linux下的file命令可以让你窥视一个文件的这些信息,可以试试。
通过file命令可以参看目标文件、elf可执行文件,甚至shell文件:
file /lib/x86_64-linux-gnu/libc-2.27.so
/lib/x86_64-linux-gnu/libc-2.27.so: ELF 64-bit LSB shared object, x86-64, version 1 (GNU/Linux), dynamically linked, interpreter /lib64/l, BuildID[sha1]=b417c0ba7cc5cf06d1d1bed6652cedb9253c60d0, for GNU/Linux 3.2.0, stripped
file run.sh
run.sh: Bourne-Again shell script, UTF-8 Unicode text executable
file a.o
a.o: ELF 64-bit LSB relocatable, x86-64, version 1 (SYSV), not stripped
file ab
ab: ELF 32-bit LSB executable, Intel 80386, version 1 (SYSV), statically linked, not stripped
看到了吧,不同的文件的区别。
目标文件的结构
好,我们来说一说,Linux下的目标ELF文件(或可执行ELF文件)的结构吧:
ELF是Executable LinkableFormat的缩写,是Linux的链接、可执行、共享库的格式标准,尊从COFF。
| ELF头部 |
| .text |
| .data |
| .bss |
| 其他段 |
| 段表 |
| 符号表 |
ELF文件的结构,包含ELF的头部说明,然后是各种“段”(section),段是一个逻辑单元,会包含各种各样的信息,比如代码(.text)、数据(.data)、符号等。
文件头(ELF Header)
先说说ELF文件开头部分的ELF头,它是一个总的ELF的说明,里面包含是否可执行、目标硬件、操作系统等信息,还包含一个重要的东东,“段表”,就是用来记录段(section)的信息。
看个例子:
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: REL (Relocatable file)
Machine: Advanced Micro Devices X86-64
Version: 0x1
Entry point address: 0x0
Start of program headers: 0 (bytes into file)
Start of section headers: 816 (bytes into file)
Flags: 0x0
Size of this header: 64 (bytes)
Size of program headers: 0 (bytes)
Number of program headers: 0
Size of section headers: 64 (bytes)
Number of section headers: 12
Section header string table index: 11
说明:
- 其中,”7f 45 4c 46”是ELF魔法数,其实就是DEL字符加上“ELF”3个字母,表明他是一个elf目标或者可执行文件 关于elf文件头格式。
还会说明诸如,可执行代码起始的入口地址;段表的位置;程序表的位置;….多种信息。细节就不赘述了,感兴可以参考下面的参考文档,有很详细的说。
关于更详细的elf文件头的内容,可以参考:
段表(section table)
除了elf文件头,就属段表重要了,各个段的信息都在这里呢,先看个例子:
命令readelf -S ab可以帮助查看ELF文件的段表。
There are 9 section headers, starting at offset 0x1208:
Section Headers:
[Nr] Name Type Addr Off Size ES Flg Lk Inf Al
[ 0] NULL 00000000 000000 000000 00 0 0 0
[ 1] .text PROGBITS 08048094 000094 000091 00 AX 0 0 1
[ 2] .eh_frame PROGBITS 08048128 000128 000080 00 A 0 0 4
[ 3] .got.plt PROGBITS 0804a000 001000 00000c 04 WA 0 0 4
[ 4] .data PROGBITS 0804a00c 00100c 000008 00 WA 0 0 4
[ 5] .comment PROGBITS 00000000 001014 00002b 01 MS 0 0 1
[ 6] .symtab SYMTAB 00000000 001040 000120 10 7 10 4
[ 7] .strtab STRTAB 00000000 001160 000063 00 0 0 1
[ 8] .shstrtab STRTAB 00000000 0011c3 000043 00 0 0 1
Key to Flags:
W (write), A (alloc), X (execute), M (merge), S (strings), I (info),
L (link order), O (extra OS processing required), G (group), T (TLS),
C (compressed), x (unknown), o (OS specific), E (exclude),
p (processor specific)
这个可执行文件里面有9个段。
常见的3个段:代码段、数据段、bss段:
- 代码段:.code或者叫.text
- 数据段:.data,放全局变量和局部静态变量
- BSS段:.bss,为未初始化的全局变量和局部静态变量预留位置,不占空间(???bss的意义?)
还有其他一堆的段:
- .strtab : String Table 字符串表,用于存储 ELF 文件中用到的各种字符串。
- .symtab : Symbol Table 符号表,从这里可以所以文件中的各个符号。
- .shstrtab : 是各个段的名称表,实际上是由各个段的名字组成的一个字符串数组。
- .hash : 符号哈希表。
- .line : 调试时的行号表,即源代码行号与编译后指令的对应表。
- .dynamic : 动态链接信息。
- .debug : 调试信息。
- .comment : 存放编译器版本信息,比如 “GCC:(GNU)4.2.0”。
- .plt 和 .got : 动态链接的跳转表和全局入口表。
- .init 和 .fini : 程序初始化和终结代码段。
- .rodata1 : Read Only Data,只读数据段,存放字符串常量,全局 const 变量,该段和 .rodata 一样。
段表里面,记着每个段的开始的位置和位移(offset)、长度,毕竟这些段,都是紧密的放在二进制文件中,需要段表的描述信息,才能把他们每个段分割开。
有了段,我们其实就对可执行文件,了然于心了,其中.text代码段里面放着我们可以运行的机器指令,而.data数据段里面放着全局变量的初始值,还有.symtab里面放着我们当初源代码中的函数名、变量名的代表的信息。
目标ELF文件和可执行ELF文件虽然规范是一致的,但是还是有很多细微区别:
目标ELF文件的重定位表
在段表中,你会发现这种段:.rel.xxx,包含rel的字样,这样的段是干嘛用的?
这些段就是链接用的!因为你需要把某个目标中出现的函数啊、变量啊,这些东东的地址,要换成其他目标文件中的位置,也就是地址,这样才能正确的引用到这些变量,调用到这些函数啊。至于链接细节,后面讲链接的时候再说。
一般有text、data两种重定位表:
- .rel.text:代码段重定位表,就是描述代码段中出现的函数、变量的引用地址信息的描述的
- .rel.data: 数据段重定位表
字符串表
.strtab、.shstrtab
ELF中很多字符串呢,比如函数名字啊,变量名字啊,都需要有个地方放吧,恩,他们都放到一个叫“字符串”表的段中。
符号表
注意哈,字符串表只是字符串,符号表跟他不一样,符号表更重要,是表示了各个函数、变量的名字对应的代码或者内存地址啦。这玩意,在链接的时候,非常有用。因为链接,就是要找个各个变量和函数的位置啊,这样才可以更新编译阶段空出来的函数、变量的引用地址啊。
每个目标文件里面都有这么一个符号表,用nm和readelf都可以查看:
a.o目标文件的符号表
nm a.o
U _GLOBAL_OFFSET_TABLE_
U __stack_chk_fail
0000000000000000 T main
U shared
U swap
readelf -s a.o , 来,看看目标文件的符号表长啥样:
Symbol table '.symtab' contains 12 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 00000000 0 NOTYPE LOCAL DEFAULT UND
1: 00000000 0 FILE LOCAL DEFAULT ABS a.c
2: 00000000 0 SECTION LOCAL DEFAULT 1
3: 00000000 0 SECTION LOCAL DEFAULT 3
4: 00000000 0 SECTION LOCAL DEFAULT 4
5: 00000000 0 SECTION LOCAL DEFAULT 6
6: 00000000 0 SECTION LOCAL DEFAULT 7
7: 00000000 0 SECTION LOCAL DEFAULT 5
8: 00000000 85 FUNC GLOBAL DEFAULT 1 main
9: 00000000 0 NOTYPE GLOBAL DEFAULT UND shared
10: 00000000 0 NOTYPE GLOBAL DEFAULT UND swap
11: 00000000 0 NOTYPE GLOBAL DEFAULT UND __stack_chk_fail
看这个目标ELF文件的符号表:可以看到swap函数,Ndx是UND,就是Undefined的缩写,表明不知道它到底在哪个段,因为他需要被重定位的,负责就是写个1啊3啊之类的数字,表明段中的index;同样,对于全局变量shared也是同样的定义。这些内容,都会在后面的静态链接的时候,被链接器修改。
为了对比,我们可以看一下可执行文件ab的符号表的样子,看看静态链接后,这些符号的Ndx的变换:
** 可执行文件ab的符号表 **
nm ab
0804a000 d _GLOBAL_OFFSET_TABLE_
0804a014 D __bss_start
080480d7 T __x86.get_pc_thunk.ax
0804a014 D _edata
0804a014 D _end
080480db T main
0804a00c D shared
08048094 T swap
0804a010 D test
readelf -s ab
Symbol table '.symtab' contains 18 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 00000000 0 NOTYPE LOCAL DEFAULT UND
1: 08048094 0 SECTION LOCAL DEFAULT 1
2: 08048128 0 SECTION LOCAL DEFAULT 2
3: 0804a000 0 SECTION LOCAL DEFAULT 3
4: 0804a00c 0 SECTION LOCAL DEFAULT 4
5: 00000000 0 SECTION LOCAL DEFAULT 5
6: 00000000 0 FILE LOCAL DEFAULT ABS b.c
7: 00000000 0 FILE LOCAL DEFAULT ABS a.c
8: 00000000 0 FILE LOCAL DEFAULT ABS
9: 0804a000 0 OBJECT LOCAL DEFAULT 3 _GLOBAL_OFFSET_TABLE_
10: 08048094 67 FUNC GLOBAL DEFAULT 1 swap
11: 080480d7 0 FUNC GLOBAL HIDDEN 1 __x86.get_pc_thunk.ax
12: 0804a010 4 OBJECT GLOBAL DEFAULT 4 test
13: 0804a00c 4 OBJECT GLOBAL DEFAULT 4 shared
14: 0804a014 0 NOTYPE GLOBAL DEFAULT 4 __bss_start
15: 080480db 74 FUNC GLOBAL DEFAULT 1 main
16: 0804a014 0 NOTYPE GLOBAL DEFAULT 4 _edata
17: 0804a014 0 NOTYPE GLOBAL DEFAULT 4 _end
可以看到,shared的Ndx现在是4了,而swap的Ndx是1了,对应的就是4:数据段、1:代码段:
上面曾经显示过的段的编号
。。。。
[ 1] .text PROGBITS 08048094 000094 000091 00 AX 0 0 1
[ 2] .eh_frame PROGBITS 08048128 000128 000080 00 A 0 0 4
[ 3] .got.plt PROGBITS 0804a000 001000 00000c 04 WA 0 0 4
[ 4] .data PROGBITS 0804a00c 00100c 000008 00 WA 0 0 4
[ 5] .comment PROGBITS 00000000 001014 00002b 01 MS 0 0 1
。。。
看到了把,对应的第一列的序号,就标明了代码段是1,数据段是4。
另外,第二列Type也挺有用的:Object就表示是数据的符号;而Func就是函数符号;
静态链接
好了,前面讲目标文件差不多了,我们得到了一大堆零散的目标ELF文件,是时候把他们“合体”了,这需要链接过程了,就是要把这些目标文件“凑”到一起,也就是把各个段合并到一起,
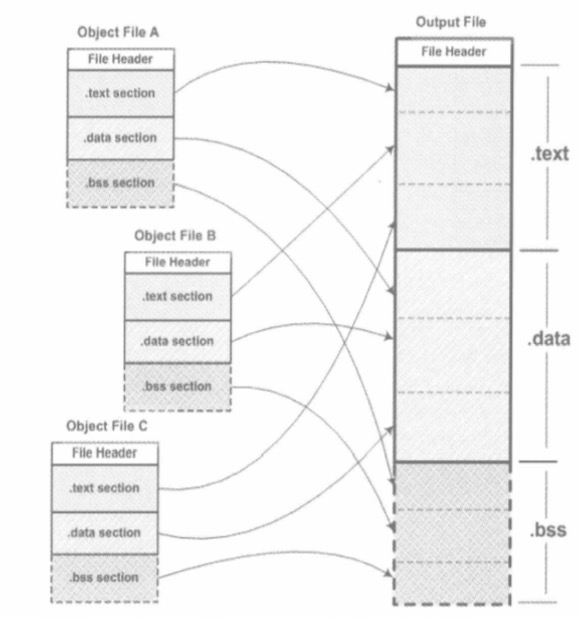
合并开始!读每个目标文件的文件头,获得各个段的信息,然后做符号重定位:
-
读每个目标文件,收集各个段的信息,然后合并到一起,其实我理解就是压缩到一起,你的代码段挨着我的代码段,我们合并成一个新的,因为每个ELF目标文件都是有文件头的,这些信息都有,所以,是可以很严格合并到一起的
-
符号重定位,说白了,就是把之前调用某个函数的地址,给重新调整一下,或者某个变量的在data段中的地址重新调整一下,为毛?因为合并的时候,各个代码段都合并了,对应代码中的地址都变了啊,所以要调整呀。这步是链接最核心的东东!
ld a.o b.o ab
我们来细看一下a.o+b.o=> ab的变化,特别是虚拟地址的变化:
先看看链接前的目标ELF文件:a.o,b.o
a.o的段属性(objdump -h a.o)
------------------------------------------------------------------------
Idx Name Size VMA LMA File off Algn
0 .text 00000051 0000000000000000 0000000000000000 00000040 2**0
CONTENTS, ALLOC, LOAD, RELOC, READONLY, CODE
1 .data 00000000 0000000000000000 0000000000000000 00000091 2**0
CONTENTS, ALLOC, LOAD, DATA
2 .bss 00000000 0000000000000000 0000000000000000 00000091 2**0
ALLOC
b.o的段属性(objdump -h b.o)
------------------------------------------------------------------------
Idx Name Size VMA LMA File off Algn
0 .text 0000004b 0000000000000000 0000000000000000 00000040 2**0
CONTENTS, ALLOC, LOAD, READONLY, CODE
1 .data 00000008 0000000000000000 0000000000000000 0000008c 2**2
CONTENTS, ALLOC, LOAD, DATA
2 .bss 00000000 0000000000000000 0000000000000000 00000094 2**0
ALLOC
接下来是a.o + b.o,链接合体后的可执行ELF文件:ab
ab的段属性(objdump -h ab)
------------------------------------------------------------------------
Idx Name Size VMA LMA File off Algn
0 .text 00000091 08048094 08048094 00000094 2**0
CONTENTS, ALLOC, LOAD, READONLY, CODE
1 .eh_frame 00000080 08048128 08048128 00000128 2**2
CONTENTS, ALLOC, LOAD, READONLY, DATA
2 .got.plt 0000000c 0804a000 0804a000 00001000 2**2
CONTENTS, ALLOC, LOAD, DATA
3 .data 00000008 0804a00c 0804a00c 0000100c 2**2
CONTENTS, ALLOC, LOAD, DATA
来,我们来玩一玩,“找不同”!
可执行ELF文件ab的VMA填充了。VMA是啥?为何需要调整?看来,是时候说一说可执行ELF文件了。
目标ELF文件和可执行ELF文件
我们上面一直刻意不区分的目标ELF文件和可执行ELF文件,原因是想先介绍他们共同的ELF规范部分,但是,其实两者是有区别的,这一小节忍不住想说一下,希望不打断看官的思路。
目标ELF文件和可执行ELF文件,其实是两个目的,两个视角:
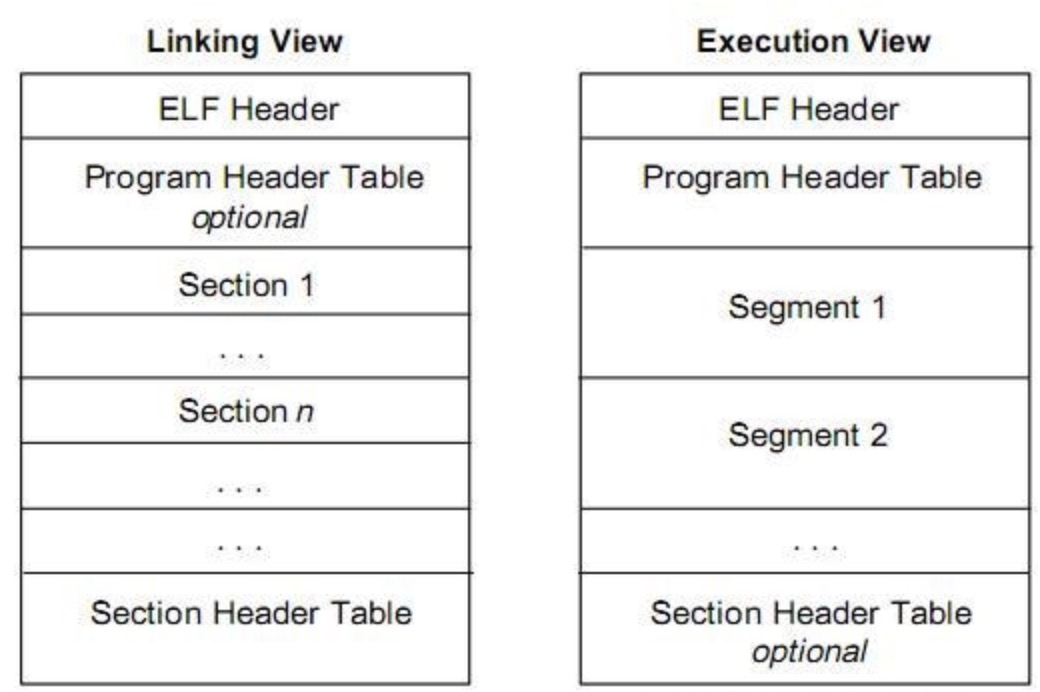
目标文件是为了进一步链接用的,所以,我们可以用“链接视角”来看待他,他有各个sections,用段表section head table(SHT)来记录,归档不同的内容,还有重要的重定位表,用于链接;
而可执行文件是为了“进程视角”存在的,他根本不需要啥重定位表,但是,他多了一个叫 “program header table(PHT)”,用来告诉操作系统,你如何把各个section加到到进程空间的segment中。进程里面专门有个“segment”的概念,定义出“虚拟内存区域”(VMA,Virtual Memory Area),每个VMA就是一个segement。这些segment,是操作系统为了装载需要,专门又对sections们做了一次合并,定义出不同用途的VMA(如代码VMA、数据VMA、堆VMA、栈VMA)。在目标文件中,你会看到地址都是从0开始的,但是在可执行文件中,是0x8048000开始的;为何是这么个数?这个是因为操作系统进程虚拟地址的开始地址就是这个傻数。关于虚拟地址空间,我们在这里不展开了,后面讲装载的部分,会再详细讨论了。
虽然两者有区别,但是大体的规范是一样的,都有ELF头、段表(section table)、节(section)等基本的组成部分。
可以参考这篇文章《ELF可执行文件的理解》,加深理解。
合体的ELF可执行文件
好吧,我们回来看合体(链接)后的可执行ELF文件ab吧。
ab的段属性(objdump -h ab):
Idx Name Size VMA LMA File off Algn
0 .text 00000091 08048094 08048094 00000094 2**0
CONTENTS, ALLOC, LOAD, READONLY, CODE
1 .eh_frame 00000080 08048128 08048128 00000128 2**2
CONTENTS, ALLOC, LOAD, READONLY, DATA
2 .got.plt 0000000c 0804a000 0804a000 00001000 2**2
CONTENTS, ALLOC, LOAD, DATA
3 .data 00000008 0804a00c 0804a00c 0000100c 2**2
CONTENTS, ALLOC, LOAD, DATA
你可以看到,ab的代码段.text,就是从0x8048094开始的,长度是0x91,也就是145个字节长度的代码段。
好!段的开头地址确定了,接下来就好找,段里面的符号对应的地址了(也就是.text段中的函数,和.data段中的变量)
我们回过头来,去看几个符号:swap函数、main函数、test变量、shared变量:
Num: Value Size Type Bind Vis Ndx Name
10: 08048094 67 FUNC GLOBAL DEFAULT 1 swap
12: 0804a010 4 OBJECT GLOBAL DEFAULT 4 test
13: 0804a00c 4 OBJECT GLOBAL DEFAULT 4 shared
15: 080480db 74 FUNC GLOBAL DEFAULT 1 main
- main函数:地址是080480db,Ndx=1,Type=FUNC,也就是说,main这个符号,对应的是一个函数,在代码段.text,起始地址是080480db。
- test变量:地址是0804a010,Ndx=4,Type=OBJECT,也就是说,test这个符号,对应的是一个变量,在数据段,起始地址是0804a010。
那问题来了,这些地址,都是如何确定的呢?要知道目标ELF文件a.o、b.o里面的地址还都是0作为基地址的,到了他俩合体后的可执行文件ab,怎么就填充了这些东西呢?这就要引出“符号重定位”了。
符号重定位
既然链接是把大家的代码段、数据段,都合并到一起,那么就需要修改对应的调用的地址,比如a.o要调用b.o中的函数,那合并到一起成为ab的时候,就需要修改之前a.o中的调用的地址为一个新的ab中的地址,也就是之前b.o中的那个函数swap的地址。
那链接器是怎么做的呢?是通过“重定位 + 符号解析”完成的。
最开始啊,编译完的目标文件,其实里面的变量地址、函数地址,基准地址,都是0,也就是啥都是0地址开始的。
可是,一旦你链接,你就不能从0开始了,你要从操作系统规定的应用进程的规定虚拟起始地址开始作为基准地址了,这个规定是多少?0x08048094。别问我为何是这么个怪地址,真心不知。
另外,你还合并了好几个目标文件的各个段,他们肚子里的函数呀、变量呀,地址都是基于0的啊,现在合体了、合并了,都要开始逐一调整一通了吧!
之前每个函数、变量的地址,都是相对于0的,也就是,你是知道他们每个人的偏移offset的,这样的话,你只需要告诉他们新的基地址的调整值,他们就可以加上之前的offset,算出新的地址啦。把所有涉及到他们被调用的地方,都改一下,就完成了这个重定位的过程啊。
具体怎么干呢?
是通过重定位表来完成:
重定位表
就是一个表,记着之前每个object目标文件中,哪些函数呀、变量呀,需要被重定位,恩,这个是一个单独的段,命名还有规律呢!就是.rel.xxx,比如.rel.data、.rel.text。
看个栗子:
RELOCATION RECORDS FOR [.text]:
OFFSET TYPE VALUE
0000000000000025 R_X86_64_PC32 shared-0x0000000000000004
0000000000000032 R_X86_64_PLT32 swap-0x0000000000000004
看到了吧,shared变量,和swap函数,都在a.o的重定位表中被记录下来,说明,他们的地址后期会被调整。
而其中的offset中的25,就是shared变量对于数据段的起始位置的位移offset是25个字节;同样,swap函数相对于代码段开始的offset是32个字节。
另外,VALUE这列的“shared、swap”,会对应到符号表里面的饿shared、swap符号。重定位表只记录那些符号需要重定位,而关于这个函数啊、变量啊,更详细的信息,都在符号表中。
接下来,精彩的事情发生了,也就是链接中最关键的一步,也就是要修改链接完成的文件中,调用函数和变量引用的地址了:
指令修改
要修改函数和数据的应用地址,有很多修改方法,修改有很多种方法,这涉及到各个平台的寻址指令差异,比如R_X86_64_PC32。但是本质来讲,就是需要一种计算方法,计算出链接后的代码中对函数的调用地址、变量的应用地址,进行链接后的修改地址。
对于32位的程序来说,一共有10种重定位的类型,想尽情了解,可以阅读这篇博客,获得更多信息,这里,我觉得举个例子,可能更容易理解:
好!那就让我们来个糖炒栗子,俩文件a.c,b.c,然后链接成ab,我们看看链接过程中,是如何做指令地址修改的:
** 先看看源代码 **
a.c
extern int shared;
int main()
{
int a = 0;
swap(&a, &shared);
}
b.c
int shared = 1;
int test = 3;
void swap(int* a, int* b) {
*a ^= *b ^= *a ^= *b;
}
a.c的汇编文件
00000000 <main>:
....
31: 89 c3 mov %eax,%ebx
33: e8 fc ff ff ff call 34 <main+0x34> <------------- 调用swap函数
38: 83 c4 10 add $0x10,%esp
....
Relocation section '.rel.text' at offset 0x24c contains 4 entries:
Offset Info Type Sym.Value Sym. Name
....
00000034 00000e04 R_386_PLT32 00000000 swap
可以看到,目标文件a.o中的汇编指令,和重定位表中为R_386_PLT32的重定位方式。
然后,链接后得到ab的代码
链接后的 ab ELF可执行文件
08048094 <swap>:
8048094: 55 push %ebp
8048095: 89 e5 mov %esp,%ebp
....
080480db <main>:
....
804810c: 89 c3 mov %eax,%ebx
804810e: e8 81 ff ff ff call 8048094 <swap>
8048113: 83 c4 10 add $0x10,%esp
....
我们来分析一下:
1、修正后的swap地址是:0x08048094
2、修正后的代码地址是: 0x804810e
3、原来的调用代码: 33: e8 fc ff ff ff call 34 <main+0x34>,其实是0xfffffffc,补码表示的-4
4、先看看修改完成的:ab中,804810e: e8 81 ff ff ff call 8048094 <swap>
看到了吧,e8 fc ff ff ff 修改成了=> e8 81 ff ff ff,补码表示是-127
5、这个值怎么算的?
看看a.o的重定位表中的信息是:00000034 00000e04 R_386_PLT32 00000000 swap
所谓R_386_PLT32,是:L+A-P
- L:重定项中VALUE成员所指符号@plt的内存地址 => 8048094,就是修正后的swap函数地址
- A:被重定位处原值,表示”被重定位处”相对于”下一条指令”的偏移 => fcffffff,就是源代码上的地址,固定的,补码表示的,实际值是-4
- P:被重定位处的内存地址 => 804810e,就是修正后的main中调用swap的代码地址
我们按照这个公式,计算一下修正后的调用地址:
L+A-P:8048094 + (-4) - (804810e) = - 127 = -0x7f,补码表示就是 ffffff81,由于是小端表示,所以最终替换完的指令为:
804810e: e8 81 ff ff ff call 8048094 <swap>
代码在执行的时候,会用当前的地址的下一条指令的地址,加上这个偏移(-127),正好就是swap修正后的地址0x08048094,不信,可以自己计算一下。
静态链接库
我们自己写的程序,可以编译成目标代码,然后等着链接,但是,我们可能会用到别的库,他们也是一个个的xxx.o文件么?然后,我们链接的时候,需要挨个都把他们指定链接进来么?
我们可能会用到c语言的核心库、操作系统提供的各种api的库、以及很多第三方的库。比如c的核心库,比较有名的是glibc,原始的glibc源代码很多,可以完成各种功能,如输入输出、日期、文件等等,他们其实就是一个个的xxx.o,如fread.o,time.o,printf.o,恩,就是你想象的样子的。
可是,他们被压缩到来一个大的zip文件里,叫libc.a:./usr/lib/x86_64-linux-gnu/libc.a,就是个大zip包,把各种*.o都压缩进去了,据说libc.a包含了1400多个目标文件呢:
objdump -t ./usr/lib/x86_64-linux-gnu/libc.a|more
In archive ./usr/lib/x86_64-linux-gnu/libc.a:
init-first.o: file format elf64-x86-64
SYMBOL TABLE:
0000000000000000 l d .text 0000000000000000 .text
0000000000000000 l d .data 0000000000000000 .data
0000000000000000 l d .bss 0000000000000000 .bss
.......
我好奇的统计了一下,其实,不止1400,我的这台ubuntu18.04上,有1690个呢:
objdump -t ./usr/lib/x86_64-linux-gnu/libc.a|grep 'file format'|wc -l
1690
如果你以–verbose方式运行编译命令,你能看到整个细节过程:
gcc -static --verbose -fno-builtin a.c b.c -o ab
....
/usr/lib/gcc/x86_64-linux-gnu/7/cc1 -quiet -v -imultiarch x86_64-linux-gnu b.c -quiet -dumpbase b.c -mtune=generic -march=x86-64 -auxbase b -version -fno-builtin -fstack-protector-strong -Wformat -Wformat-security -o /tmp/cciXoNcB.s
....
as -v --64 -o /tmp/ccMLSHnt.o /tmp/cciXoNcB.s
.....
/usr/lib/gcc/x86_64-linux-gnu/7/collect2 -o ab /usr/lib/gcc/x86_64-linux-gnu/7/../../../x86_64-linux-gnu/crt1.o /usr/lib/gcc/x86_64-linux-gnu/7/../../../x86_64-linux-gnu/crti.o /usr/lib/gcc/x86_64-linux-gnu/7/crtbeginT.o ...
可以看到整个过程就是3步:
- cc1做编译:编译成临时的汇编程序
/tmp/cciXoNcB.s - as汇编器:生成目标二进制代码
- collect2:实际上是一个ld的包装器,完成最后的链接
还可以看到,会链接各类的静态库,其实他们都在libc.a这类静态库中。
装载
好啦,上面,终于把一个程序编译、链接完了,变成了一个可执行文件啦,接下来,就要聊聊如何把他加载到内存了,这个就是“装载”过程了。
虚拟地址空间
在谈加载到内存里之前,我们得先谈谈进程虚拟地址空间的概念。
进程虚拟地址空间,在我看来是一个非常重要的概念,他的意义在于,让每个程序,甚至后面的进程概念,都变得独立起来,每个人玩自己的,不考虑啥物理内存啊,硬盘啊,在文件中的绝对位置啊。他关心的,就是只是自己在一个虚拟空间的地址位置了。这样链接器就好安排每个代码、数据的位置了,将来,装载器,也好安排指令和数据,甚至栈啊、堆啊她们的位置了,恩,与硬件无关了。
这个地址编码也很简单,就是你总线多大,我就能编码多大,比如8位总线,地址也就256个;到了32位,地址就可以是4G大小了;到了64位,妈呀!我已经算不清楚了,太大了。这个大的一个地址空间,都给一个程序和进程用啦,哈哈,好大好大啊,可是,真实内存可能也就16G、32G,还有那么多进程兄弟们,怎么办?怎么装载进来,映射进来,恩,别急,后面我们会讲,不过,你已经自己给出了答案,就是要映射。
如何载入内存
前面说了,你一个可执行文件,地址空间硕大无比,那你怎么把自己这头大象,装入只有16G空间大小的“冰箱”—-内存?!
答案是映射。
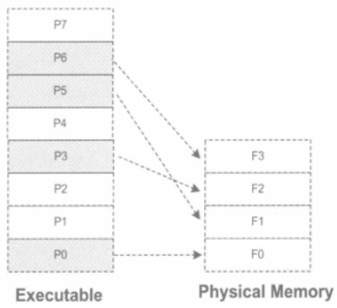
这样,你就把可执行文件中的一块一块的装进内存里面了,前提是进程需要的块,比如正在或者马上要执行的代码,数据啥的,但是剩下的怎么办?还有如果内存满了怎么办?这些不用担心,操作系统负责调度,会判断你是否用到了,就给他加载;如果满了,就按照LRU算法替换旧的,诸如此类的做法。
进程视角
我们切换到进程的视角,进程也是要有一个虚拟空间的,叫做“进程虚拟空间(Process Virtual Space)”注意,我们又提到了虚拟空间,前面曾经聊起过这个话题,那时候就谈过,链接器需要、进程加载也需要。链接的时候,给每段代码呀、数据呀,编个地址。现在,进程,也需要地址啊,这个地址又是一个虚拟地址,我的学习认知,觉得,她们俩不是一回事,但是差不多了多少,都应该是总线位数的编码出来的空间大小,各个内容存放的位置也不会有太大变换。
但是,毕竟是不一样的呀,所以啊,她们俩之间,也需要映射。有了这个映射,进程发现自己所需要的可执行代码缺了,才能知道到可执行文件中的第几行到第几行加载啊。对!这个映射关系就存在可执行ELF的PHT(程序映射表 - Program Header Table)中,前面介绍过,就是个映射表。
我们在把这个PHT映射表的细化一下。
你说,你直接把可执行文件原封不动的映射到进程空间,多好啊啊,这样映射多简单啊。
不是这样的。
为了空间布局上的效率,链接器,会把很多段(section)合并,规整成可执行的段(segment)、可读写的段、只读段等,合并了后,空间利用率就高了,否则,很小的很小的一段,未来物理内存页浪费太大(物理内存页分配一般都是整数倍一块给你,比如4k),所以,链接器,趁着链接,就把小块们都合并了,这个合并信息就在VMA信息里,这个VMA信息就在可执行文件头里,通过:
这里有2个段:section和segment,中文都叫段,但是有很大区别的,section是目标文件中的单元,而segement是可执行文件中的概念,是一个section的组合或者说集合,是为了将来加载到进程空间里面用的。在我理解,segement和VMA是一个意思。
readelf -l ab 可以查看程序映射表 - Program Header Table:
Elf file type is EXEC (Executable file)
Entry point 0x80480db
There are 3 program headers, starting at offset 52
Program Headers:
Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align
LOAD 0x000000 0x08048000 0x08048000 0x001a8 0x001a8 R E 0x1000
LOAD 0x001000 0x0804a000 0x0804a000 0x00014 0x00014 RW 0x1000
GNU_STACK 0x000000 0x00000000 0x00000000 0x00000 0x00000 RW 0x10
Section to Segment mapping:
Segment Sections...
00 .text .eh_frame
01 .got.plt .data
你看,“Segment Sections”,就告诉你了,如何合并这些sections。
你看上面的例子,他有3个段(Segment),其中2个type是LOAD的Segment,一个是可执行的Segment,一个是只读的Segment;那第一个Segment,可执行那个,到底合并哪些Section呢? 答案是:00 .text .eh_frame。
这个信息,是存在可执行文件的一个叫“程序头表(Program Header Table - PHT)”里面的,就是你用readelf -f看到的内容。告诉你sections如何合并成segments。
好吧,再总结一下!
- 目标文件是有自己的sections的,so,可执行文件也一样
- 只不过,可执行文件又创造了一个概念,segment,就是把sections做了一个合并
- 但是,这事没完,真正装载的时候,放到内存里面的时候,还要
段(Segment)地址对齐
内存啊,都是一个一个4k的小页,便于分配,这个就不多说了,涉及到内存管理。
所以呢,操作系统一个给你,就给你一摞4k小页,那问题了了,即使你压缩了sections们成了segment,你也不正好就4k大小啊,又多又少,就算你多一丢丢4k的整数倍,操作系统都得额外再给你分配一页,多浪费啊。
办法来了,就是段地址对齐。
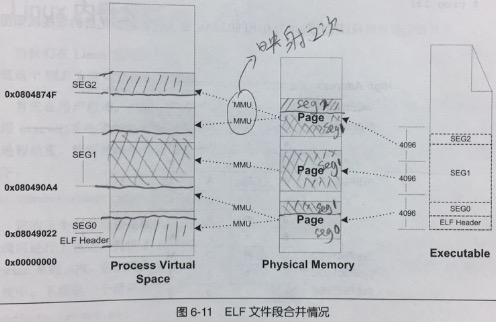
看,一个物理页(4k)上,不再是放一个segment,而是还放着别的,然后物理页和进程中的页,是1:2的映射关系,浪费就浪费了,没事,反正也是虚拟的。物理上就被“压缩”到了一起,过去需要5个才能放下的内容,现在只需要3个物理页了。
堆和栈
可执行文件加载到进程空间里面之后,进程空间还有两个特殊的VMA区域,分别是堆和栈。

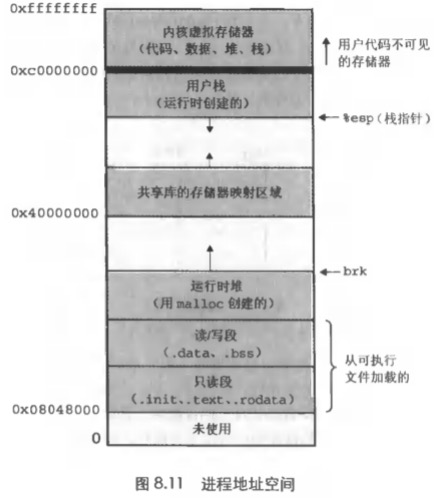
你通过查看linux中的进程内存映射,也可以看到这个信息:cat /proc/555/maps
55bddb42d000-55bddb4f5000 rw-p 00000000 00:00 0 [heap]
...
7ffeb1c1a000-7ffeb1c3b000 rw-p 00000000 00:00 0 [stack]
参考
Anatomy of a Program in Memory Gcc 编译的背后
动态链接
静态链接我们大致搞清楚,接下来,我们要说说动态链接。
动态链接的好处很多:
- 代码段可以不用重复静态连接到需要他的可执行文件里面去了,省了磁盘空间。
- 运行期,还可以共享动态链接库的代码段啊,运行期也省内存了
一个栗子
先举个例子,看看动态链接库怎么写:
lib.c:就是动态链接库代码:
#include <stdio.h>
void foobar(int i) {
printf("Printing from lib.so --> %d\n", i);
sleep(-1);
}
为了让他其他程序引用他,需要为他编写一个头文件:lib.h
#ifndef LIB_H_
#define LIB_H_
void foobar(int i);
#endif // LIB_H_
最后是调用代码:program1.c
#include "lib.h"
int main() {
foobar(1);
return 0;
}
好,让我们来编译这个动态链接库:gcc -fPIC -shared -o lib.so lib.c,然后我可以得到lib.so
然后,编译引用他的程序的program1.c: gcc -o program1 program1.c ./lib.so,这个时候需要引用这个动态链接库。这样就可以顺利的引用这个动态链接库了。
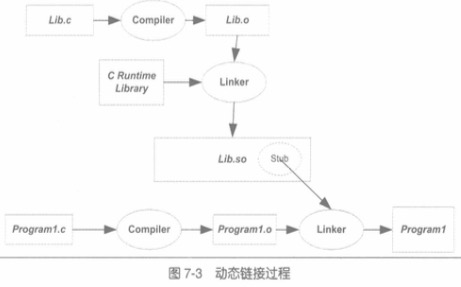
这背后,到底发生了什么?
编译program1.c的时候,他引用了函数foobar,可是这个函数在哪里呢?所以,要在编译的时候,也就是链接的时候,告诉这个program1程序,你需要的那个foobar在lib.so里面,也就是在编译参数中,需要加入./lib.so这个文件的路径。据说,链接器要拷贝so的符号表信息到可执行文件中。
可是,在过去静态链接的时候,我们要对program1中对函数foobar的引用进行重定位,也就是修改program1中对函数foobar引用的地址,可是,现在是动态链接了,就不需要做这件事了,因为链接的时候,根本就没有foobar这个函数的代码在代码段中。
那什么时候,再告诉program1,foobar的调用地址到底是多少呢?答案是运行的时候,也就是运行期,加载lib.so的时候,再告诉program1,你该去调用哪个地址上的lib.so中的函数。
我们可以通过查看/proc/$id/maps,可以查看运行期的program1的样子:
cat /proc/690/maps
55d35c6f0000-55d35c6f1000 r-xp 00000000 08:01 3539248 /root/link/chapter7/program1
55d35c8f0000-55d35c8f1000 r--p 00000000 08:01 3539248 /root/link/chapter7/program1
55d35c8f1000-55d35c8f2000 rw-p 00001000 08:01 3539248 /root/link/chapter7/program1
55d35dc53000-55d35dc74000 rw-p 00000000 00:00 0 [heap]
7ff68e48e000-7ff68e675000 r-xp 00000000 08:01 3671326 /lib/x86_64-linux-gnu/libc-2.27.so
7ff68e675000-7ff68e875000 ---p 001e7000 08:01 3671326 /lib/x86_64-linux-gnu/libc-2.27.so
7ff68e875000-7ff68e879000 r--p 001e7000 08:01 3671326 /lib/x86_64-linux-gnu/libc-2.27.so
7ff68e879000-7ff68e87b000 rw-p 001eb000 08:01 3671326 /lib/x86_64-linux-gnu/libc-2.27.so
7ff68e87f000-7ff68e880000 r-xp 00000000 08:01 3539246 /root/link/chapter7/lib.so
7ff68ea81000-7ff68eaa8000 r-xp 00000000 08:01 3671308 /lib/x86_64-linux-gnu/ld-2.27.so
7ffc2a646000-7ffc2a667000 rw-p 00000000 00:00 0 [stack]
7ffc2a66c000-7ffc2a66e000 r--p 00000000 00:00 0 [vvar]
7ffc2a66e000-7ffc2a670000 r-xp 00000000 00:00 0 [vdso]
ffffffffff600000-ffffffffff601000 r-xp 00000000 00:00 0 [vsyscall]
可以看到一个叫ld-2.27.so,这个玩意,其实就是动态连接器,系统开始的时候,他先接管控制权,加载完lib.so后,再把控制权返还给program1。凡是有动态链接库的程序,都会把他动态链接到程序的进程中的,由他首先加载动态链接库的。
GOT和PLT
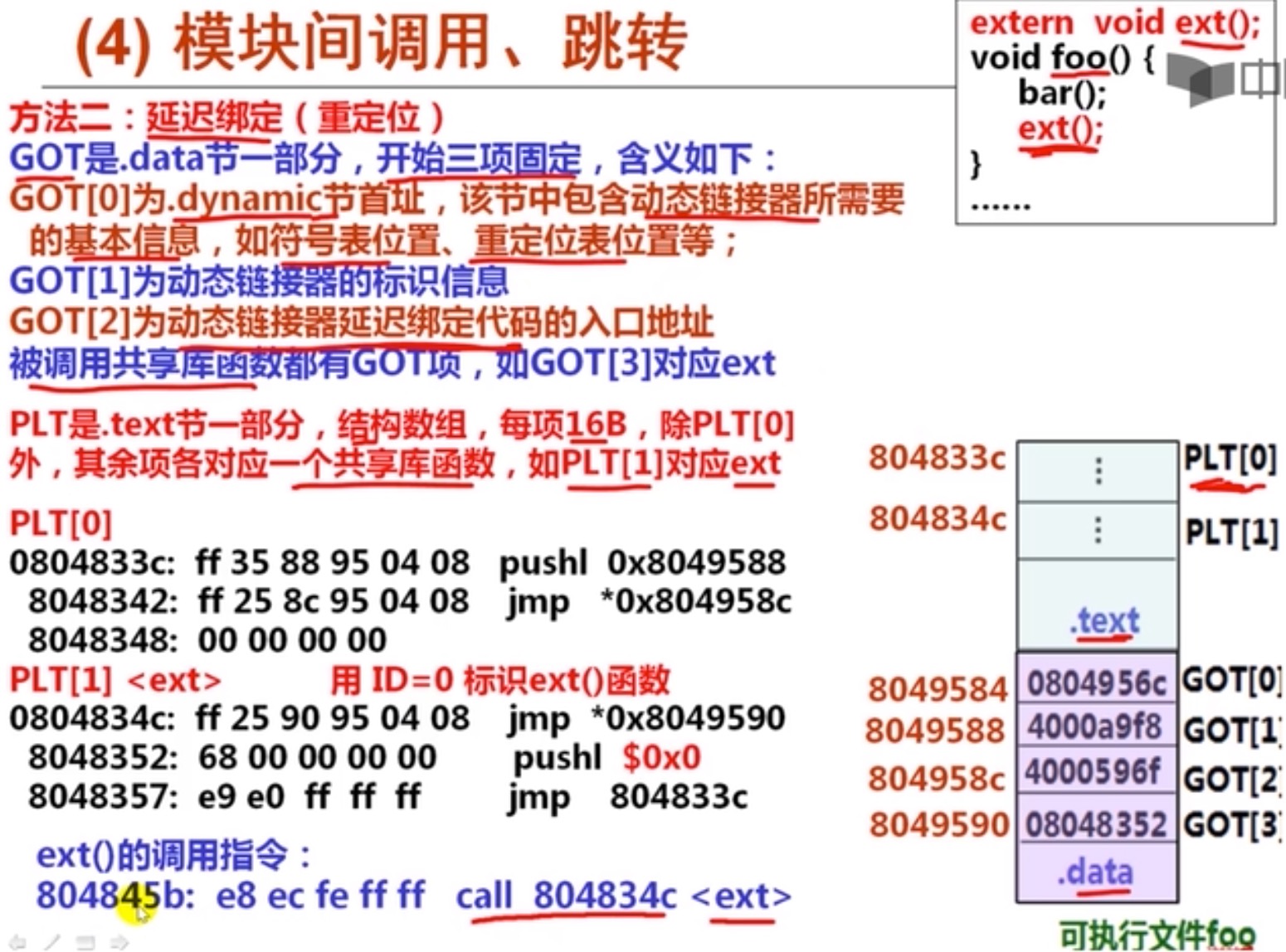
GOT和PLT很复杂,细节很多,不太好理解,我其实细节也不是很清楚,只是把大致的过程搞明白了,所以,这里只是说一说我的一些理解,如果感兴趣可以去看南大袁春风老师的关于PLT的讲解,我也是借鉴拉她老人家的PPT:
GOT是放在数据段里的,而PLT是在代码段里面的,所以,GOT是可以改的,放的跳转用的函数地址;而PLT里面放的是代码,是告诉怎么调用动态链接库里面的函数的代码(不是函数的代码,是怎么调用的代码)。
假如主程序需要调用动态链接库lib.so里的1个函数:ext();
那么在GOT表里和PLT表里,都有1个条目,GOT表里是未来这个函数加载后的地址;而PLT里放的是如何调用这个函数的代码,这些代码是在链接期,链接器生成的。
GOT里面还有3个特殊的条目,PLT里面还有1个特殊的条目。
GOT里的3个特殊条目:
- GOT[0]: .dynamic section的首地址,里面放着动态链接库的符号表啥的信息。
- GOT[1]: 动态链接器的标识信息,link_map的数据结构,这个不是很明白是什么意思,我理解就是链接库的so文件的信息,用于加载?
- GOT[2]: 这个是调用动态库延迟绑定的代码的入口地址,延迟绑定的代码是一个特殊程序的入口,实际是一个叫“_dl_runtime_resolve”的函数的地址。
PLT里的特殊条目:
- PLT[0]: 其实就是去调动“_dl_runtime_resolve”函数的代码,是链接器自动生成的。
好,我们说一下整个过程开始了:
因为是延迟绑定,所以,动态重定位这个过程,就需要在你第一次调用函数的时候触发。 啥叫动态重定位啊?就是要告诉进程加载程序,修改新载入的动态链接库被调用处的地址,谁知道你把so文件加载到进程空间啥犄角旮旯了啊?你得把加载后的地址告诉我,我才能调用啊,这个过程就是动态重定位。
好,看我们.text的主程序开始调用ext函数了,ext函数的调用指令:
804845b: e8 ec fe ff ff call 804834c<ext>
咦? 804834c是谁?噢!原来是PLT[1]的地址,就是ext函数对应的PLT表里的代理函数,记得不?每个函数都会在PLT、GOT里面的对应一个条目。
好,现在就跳转到这个函数(PLT[1])去啦。
PLT[1]
804834c: ff 25 90 95 04 08 jmp *0x8049590
8048352: 68 00 00 00 00 pushl $0x0
8048357: e9 e0 ff ff ff jmp 804833c
这个函数干啥了?首先是跳到0x8049590里面写的那个地址去了(jmp *xxx,不是跳到xxx,而是跳到xxx里面写的地址上去)。
这里有2个细节:
1、0x8049590这个地址就是GOT[3],GOT[3]就是ext函数对应的GOT条目啊。
2、0x8049590里面写的那个地址其实就是PLT[1](ext对应的plt条目)的下一条
我靠,你看到这,肯定乐了。PLT[1]代码是不是有病啊?绕这么个圈子(用GOT[3]里的地址跳)jmp,其实就是跳到了自己的下一条。是,这次是可笑,但未来这个值会改的,改成真正的动态库的函数地址,就不可笑了,就直接去执行函数了,赞不?
接着来,
跳回来之后(PLT[1]),接下来是压栈了一个0,为何是0?0 就表示是第一个函数,也就是ext的索引。
然后继续跳0x804833c,这个是谁?这个是PLT[0],PLT[0]是谁?PLT[0]是去调用“_dl_runtime_resolve”函数呀。我靠,看来是要调用这个函数干点啥坏事了!
对!就是要调用他了,不过之前还要干一件是,就是push 0x8049588,0x8049588是谁?0x8049588是GOT[2]。GOT[2]里面放着so的信息啊(我理解的,不一定完全正确)
好了,至此,我们看到,终于要去召唤神龙,调用“_dl_runtime_resolve”函数,去加载整个so了,那参数呢?2个:一个是你压栈的那个0,就是ext函数的索引,后续通过这个索引,可以找到GOT表的位置,把真正的函数的地址回填回去;第二个参数就是你压栈的GOT[1],就是动态链接器的标识信息,我理解,就是告诉加载器,so名字叫啥,他好去加载啊。
加载完成,立刻回调你安放到位置的so里面,索引为0的ext函数的地址,到GOT[3]中,也就是索引0。
下一次你再调用这个函数的时候,还是先调用PLT[1](ext的代理代码),但是里面的jmp \*0x8049590 (jmp *GOT[3]),就可以直接跳转到真正的ext里面去啦。
我的天哪!终于捋完了,必须总结一下。
动态链接库,你动态把so加载到虚拟地址空间,地址是不定的,所以跟静态链接的思路一样,你需要做重定位,也即是要修改调用的代码地址。可是,因为是动态链接,都已经是运行期了,就不能修改内存代码段(.text)啦,因为它是只读的了。那怎么办?有办法,加载完之后,把加载的函数地址写到一个叫GOT表里就不得了。对,这个就是加载时刻,修改GOT表的方法,我这里没讲,但是是可行的。可是,现在想整一件更牛逼的事情。就是,我在主程序启动的,不加载so,我等你第一次调用某个动态链接库的函数的时候,再加载整个so,在更新GOT表。我靠!服了服了,这事要懒加载到最后一刻啊。没事,也有办法,就是通过上面的一通神操作,思路就是,你主程序调用某个动态链接库函数的时候,其实是先调用了一个代理代码(PLT[x]),他呢,其实是会记录一下,自己的序号(确定是调哪个函数),还有动态联机库的文件名,这2个参数,然后转去调用一个叫“_dl_runtime_resolve”的函数,这个函数负责把so加载到进程虚拟空间去,并且回填一下加载后的函数地址,到GOT表。以后在调用,就可以直接去调用那个函数了。
恩,就这个样子,希望过段时间,我自己还能看懂,如果看不懂,就再去看一遍南大袁春风老师的讲解!
参考
这个是一篇很赞的文章讲的PLT的内容,引用过来:
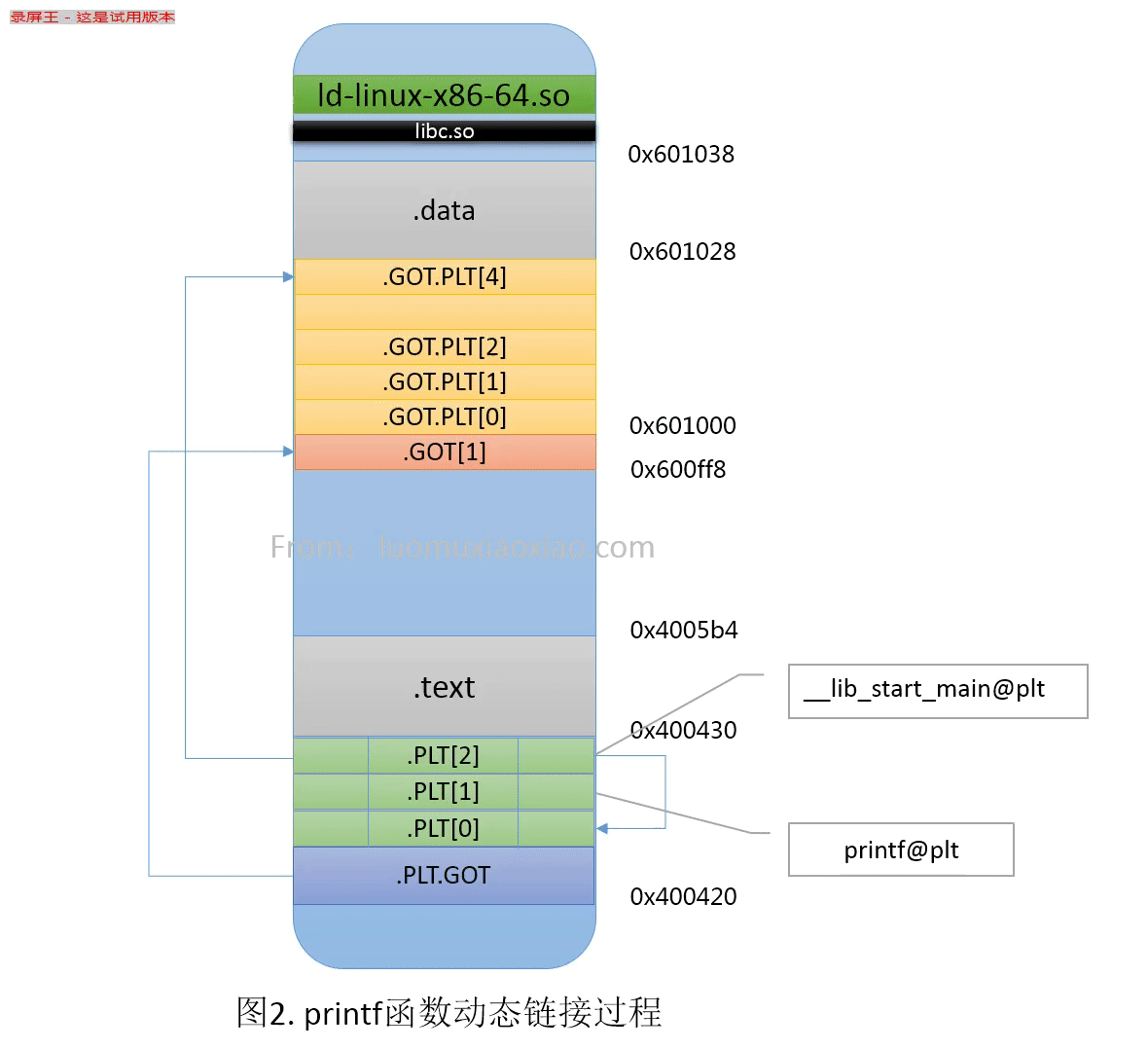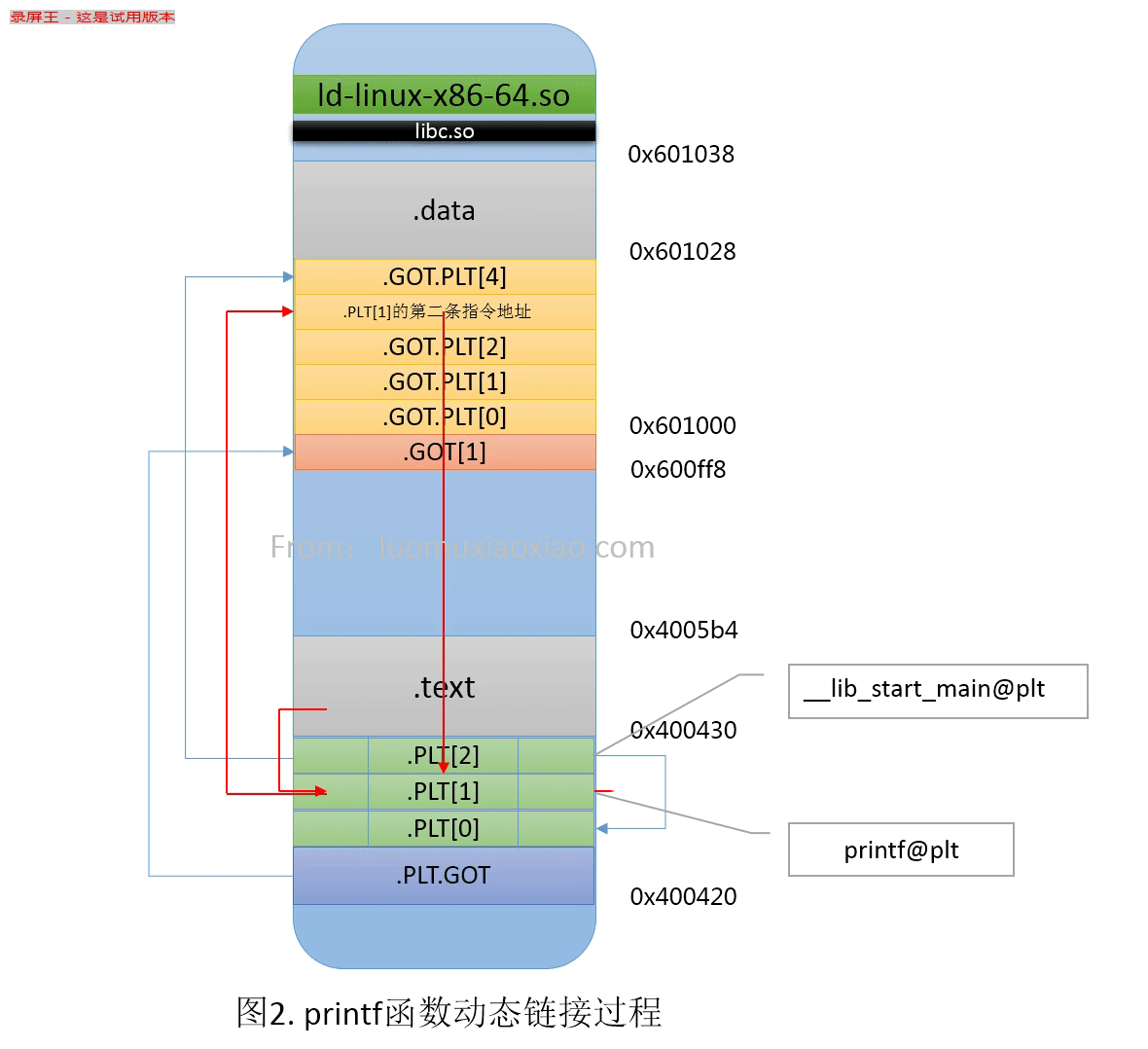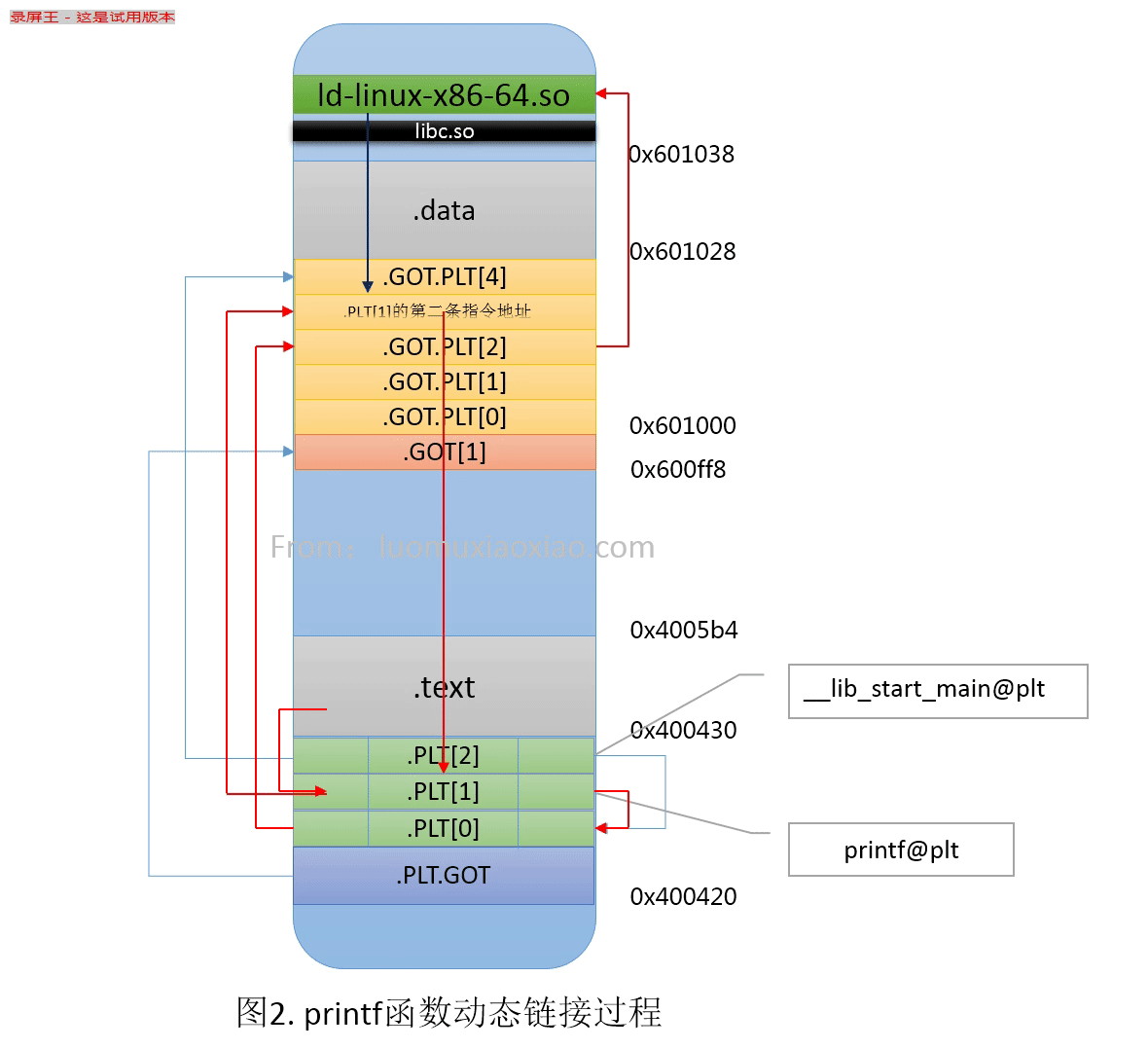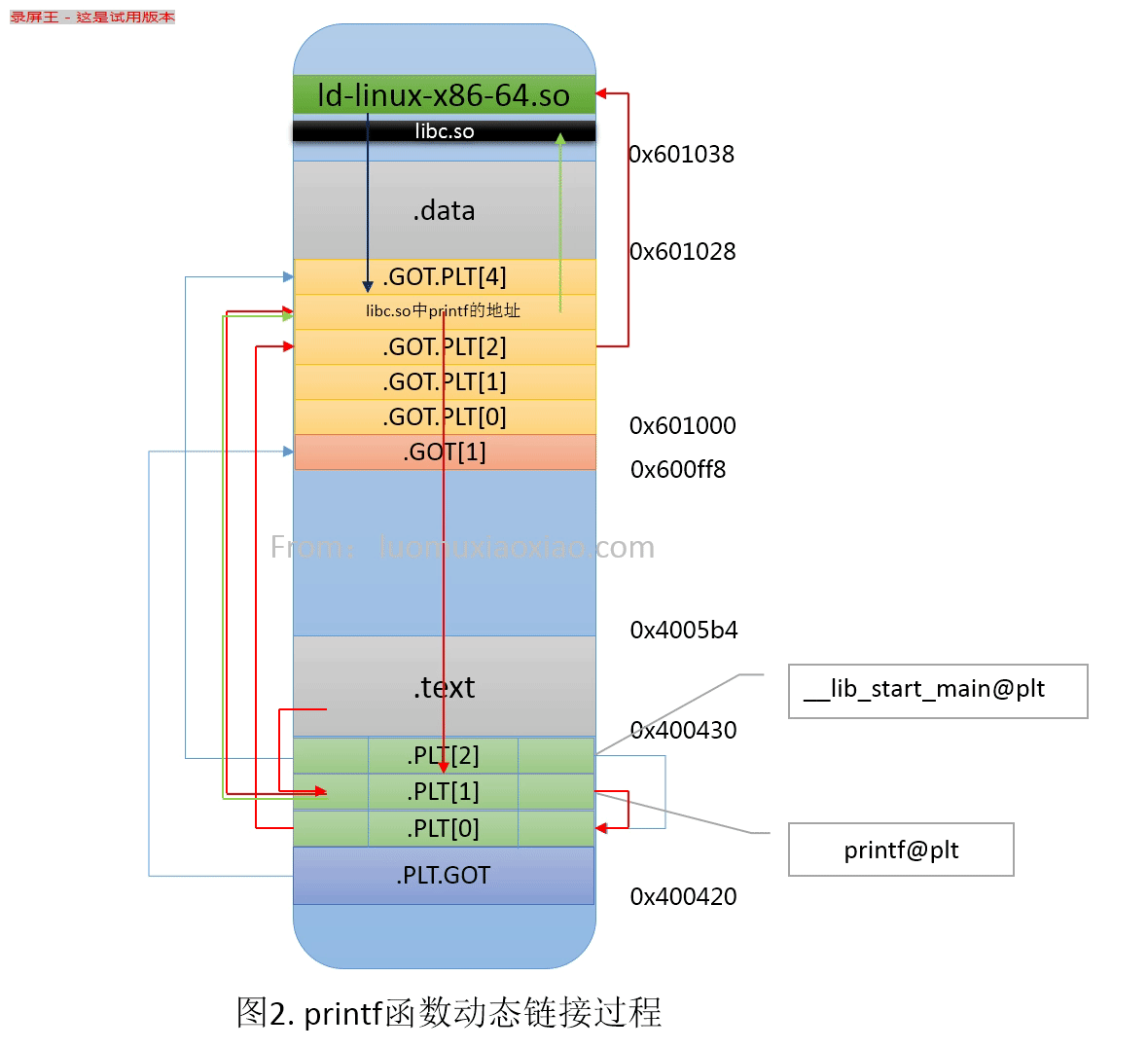
对动态链接库中的函数动态解析过程如下:
- 从调用该函数的指令跳转到该函数对应的PLT处;
- 该函数对应的PLT第一条指令执行它对应的.GOT.PLT里的指令。第一次调用时,该函数的.GOT.PLT里保存的是它对应的PLT里第二条指令的地址;
- 继续执行PLT第二条、第三条指令,其中第三条指令作用是跳转到公共的PLT(.PLT[0]);
- 公共的PLT(.PLT[0])执行.GOT.PLT[2]指向的代码,也就是执行动态链接器的代码;
- 动态链接器里的_dl_runtime_resolve_avx函数修改被调函数对应的.GOT.PLT里保存的地址,使之指向链接后的动态链接库里该函数的实际地址;
- 再次调用该函数对应的PLT第一条指令,跳转到它对应的.GOT.PLT里的指令(此时已经是该函数在动态链接库中的真正地址),从而实现该函数的调用。
- Linux动态链接库之GOT,PLT
- 深入了解GOT,PLT和动态链接
- 可执行文件的PLT和GOT
- Linux中的GOT和PLT到底是个啥?
- 聊聊Linux动态链接中的PLT和GOT
- 链接、静态链接、动态链接
Linux的共享库组织
Linux为了管理动态链接库的各种版本管理,定义了一个so的版本共享方案:
libname.so.x.y.z
- x是主版本号:重大升级才会变,不向前兼容,之前的引用的程序都要重新编译
- y是次版本号:原有的东东不变,增加了一些东西而已,向前兼容
- z是发布版本号:任何接口都没变,只是修复了bug,改进了性能而已
SO-NAME
Linux有个命名机制,用来管理so们之间的关系,这个机制叫SO-NAME。
任何一个so,都对应一个SO-NAME,其实就是libname.so.x,对,去掉了y和z。
一般系统的so,不管他的次版本号和发布版本号是多少,都会给他建立一个SO-NAME的软连接,例如 libfoo.so.2.6.1,系统就会给他建立一个叫libfoo.so.2的软链。
为什么要这么干呢?
这个软连接会指向这个so的最新版本,比如我有2个libfoo,一个是libfoo.so.2.6.1,一个是libfoo.so.2.5.5,那么软连接默认就会指向版本最新的libfoo.so.2.6.1。
在编译的时候,我们往往需要引入依赖的链接库,这个时候,依赖的so,使用软链接的SO-NAME,而不使用详细的细版本号。
在编译的ELF可执行文件中,会存在.dynamic段,用来保存自己所依赖的so的SO-NAME。
在编译的时候,有个更简洁指定lib的方式,就是gcc -lxxx,xxx就是libname中的name,比如gcc -lfoo就是告诉,链接的时候,去链接一个叫libfoo.so的最新的库,当然,这个是动态链接。如果加上-static:gcc -static -lfoo就会去默认静态链接libfoo.a的静态链接库,规则是一样的,顺道提一句。
ldconfig
Linux提供了一个工具“ldconfig”,运行它,linux就会遍历所有的共享库目录,然后更新所有的so的软链,指向她们的最新版,所以一般安装了新的so,都会运行一遍ldconfig。
系统的共享库路径
在Linux下,是尊崇一个叫FHS(File Hierarchy Standard)的一个标准,来规定系统文件是如何存放的。
- /lib:存放最关键的基础共享库,比如动态链接器、C语言运行库、数学库,她们都是/bin,/sbin里面的系统程序用到的库
- /usr/lib: 一般都是一些开发用到的 devel库啥的
- /usr/local/lib:一般都是一些第三方库,GNU标准推荐第三方的库安装到这个目录下
另外说一句/usr目录不是user的意思,而是“unix system resources”的缩写,哈哈。
/usr 是系统核心所在,包含了所有的共享文件。它是 unix 系统中最重要的目录之一,涵盖了二进制文件,各种文档,各种头文件,还有各种库文件;还有诸多程序,例如 ftp,telnet 等等。
后记
研究这个话题,前前后后经历了快一个月,文章就是流水账,把自己的过程中的体会记录下来,并且还写了一个PPT,在单位给同事们做了一次分享。虽然也只是浮光掠影,但是终究是了结了多年的心愿,对可执行文件的格式,加载这些基础知识做了一次梳理,还是收获满满的。你说,这些知识,对实际的工作有什么帮助?可能会有帮助,但是也非常有限。但是,了结了这些内容,极大的满足了自己的好奇心,“行无用之事,做时间的朋友”,做一些有意思的事情,过程本身就充满了乐趣。
文章可能会有纰漏和错误,没关系,能看到这里的同学,也请给指出来,留言给我,或者邮件给我,也可以一起讨论学习,共同进步!
参考
- 南京大学-袁春风老师-计算机系统基础
- 深入浅出计算机组成原理-极客时间
- 程序是怎样跑起来的
- 程序员的自我修养
- 深入理解计算机系统
- readlf、nm、ld、objdump、ldconfig、gcc命令
- 三本小书:


