
背景
最近的项目,涉及到tensorflow的生产环境的部署,还得上docker,所以,我就开始了项目部署的折腾之旅。
这里涉及到到很多基础的概念,比如docker镜像、docker容器、docker服务编排、tensorflow的GPU支持、python的本地安装setuptools等诸多基本概念和知识,就不给科普了,假设你都已经有了大致的了解,这里主要讲一下我的探坑之旅。
基本base镜像
先得有个能跑tensorflow的环境把,好,就得先搞个基础的能认出GPU的tensorflow的环境吧,这个可是基础啊。
nvidia驱动,CUDA,CUDNN,docker,nvidia-docker
这事儿挺纠结的,而且也走了一些弯路,开始啊,我其实没太搞清楚,nvidia驱动,CUDA,CUDNN,docker,nvidia-docker的关系。我们都知道,如果是直接在操作系统里面装tensorflow-gpu,就得先装nvidia驱动,然后装CUDA,然后再装CuDNN,然后最后才能装tensorflow-gpu的pip包,还不能装tensorflow,必须装-gpu版本,才可以真正跑起来tensorflow的gpu训练。可是,到了docker的世界,改怎么办呢?
这里有张图,可耻的😈盗用一下:
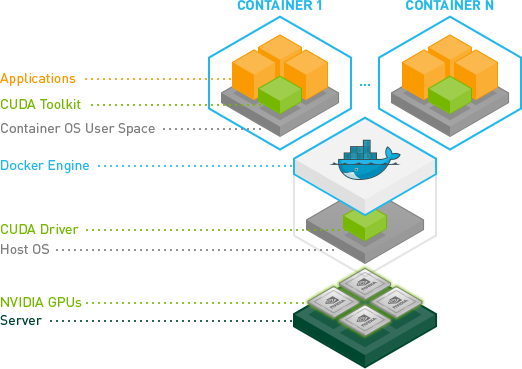
一图胜千言啊,很明白,就是你在宿主机里,也就是跑docker服务的那个宿主操作系统里面,只需要装个nvidia驱动就完了,啊!这么简单啊?!对,就酱紫,完事。
那CUDA、CuDNN那些呢?答案是,在镜像image里面。也就是说,你要是想让一个docker容器未来跑起来可以支持tensorflow去使用显卡,你得搞一个包含了CUDA和CuDNN的images镜像,然后再在这里面装个tensorflow-gpu就可以了。
哦!
不过,你以为就完了么?并没有。🤡
你如果去用docker run 去跑他,还是不行,还是认不出显卡来。这个时候,你还需要安装nvidia公司的docker的一个辅助包,叫nvidia-docker,这个是个yum/apt包,装完后,就可以让docker支持显卡啦。
nvidia-docker v1的时候,你得用一个新命令去跑docker:nvidia-docker run myimg,到了 nvidia-docker v2的时候,就舒服多了:docker run --runtime=nvidia myimg就可以了,爽了吧。
总结一下,就是,为了跑一个支持GPU显卡的docker,真TMD费劲!
- 得在docker服务的宿主机上装nvidia驱动
- 在宿主机上,还得装 nvidia-docker
- 得搞个装了CUDA和CuDNN的image镜像
- 最后,在镜像里面,别忘了得装tensorflow-gpu版本
- 最最后,跑起来docker容器的时候,别忘了加上 –runtime=nvidia参数
不过,这个都是我意淫的,我并没有这么做,我只是docker pull tensorflow/tensorflow:1.14.0-gpu-py3了一下,就把这个过程都省略了,哈哈,我就是这么无耻!
好吧,我说说我的web服务镜像制作了
有了一个好的基准image,还没完。生产环境,可是不能联网的,所以我要把能装的pip啥的需要联网的东东,都要塞进这个基准base镜像里。
所以,我需要解决几个问题:
- 要把apt源换成阿里的,这样后续就可以
apt-get install爽爽的装了 - 还要把语言环境改成中文
- 要把项目中依赖的pip包都全家桶装好,并且安装过程中使用豆瓣的pip源,这样才可以爽
好吧,看最后的Dockerfile.
docker build,完成!
制作Web服务镜像
好,有了基准镜像image,要开始在其基础上,制作我们的Web服务镜像了。
不过,我们首先要调整一下我们的代码结构:
先改造代码结构
之前,是3个项目分开的,一个CTPN,一个CRNN,一个Web。太散了。我只好用很蹩脚的脚本,在路径中添加了他俩的路径,好让解释器可以找到他们。
conf.py
CTPN_HOME=['ctpn']
CRNN_HOME=['crnn']
# 为了集成项目,把CTPN和CRNN项目的绝对路径加到python类路径里面
for path in conf.CRNN_HOME+conf.CTPN_HOME:
sys.path.insert(0, os.path.join(os.path.abspath(os.pardir), path))
sys.path.append(".")
# 完事了,才可以import ctpn,否则报错
import main.pred as ctpn
import tools.pred as crnn
我一直有个心愿🙏,就是用python的setuptools,把ctpn、crnn这两个项目搞成一个本地安装的library的概念,这样就可以心安理得的import了。终于,借这个部署docker的契机,搞一把。
于是,我果断的开始书写crnn的setup.py和ctpn的setup.py,过程中很多问题,也有很多收获:
- 我以为生成egg包,就是我的包的名字,比如生成的叫ctpn.egg的包,那么我就可以
import ctpn,引入到我所需要的位置了。其实是不行的,你必须还要在ctpn这个包里面,增加一个ctpn的文件夹,然后把所有的py源码放到到这个目录中。也就是说,这个ctpn文件夹,才是真正担当了import ctpn.xxx的包名的作用 - find_packages很爽,一句
packages=find_packages(where='.', exclude=(), include=('*',)),就把所有的代码都找到了,放到了egg包中 - ctpn中有2个c++的程序,需要单独编译并安装成一个单独的包,对,单独的包,本来,我还幻想,我的ctpn的python代码的egg包,可以和这个c++程序们在一个包中,后来发现,生成的egg文件(其实丫就是一个zip包),死活统一不到一起。我的python代码生成egg包叫
ctpn-1.0-py3.6.egg,可以,c++程序生成的包叫ctpn-1.0-py3.6-macosx-10.6-intel.egg,为毛,非要有个macosx-10.6-intel这个鬼呢?!死活消除不掉,而且,他还必须是目录结构,而不是一个zip包,恩,纠结后,我终于放弃了。踏踏实实为他们各自做一个包,而且,更拧巴的是,你还得为里面的nms.py单独生成一个ctpn_bbox的包,不能用统一成ctpn包,否则,这个包会强占了ctpn这个包的名字,导致你找不到其他python文件啦。真心纠结😭。 来看看,最后的C++动态库相关的egg目录结构:ctpn_bbox-1.0-py3.6-macosx-10.6-intel.egg/ctpn_bbox ├── __pycache__ │ └── nms.cpython-36.pyc ├── bbox.cpython-36m-darwin.so ├── nms.cpython-36m-darwin.so └── nms.py - 恩,c++的代码是靠cythonize搞定的,我开始因为是人家先写了一个c++程序,然后编译成so库,然后再生成一个python代码,被我们调用的,其实我错了,cythonize的玩法是,你先写python代码,然后他把你的python代码翻译成c++代码,然后你编译c++程序生成so文件就可以啦。
Cython库正好符合这种场景需求,将已有的Python代码转化为C语言的代码,并作为Python的built-in模块扩展。其最重要的功能是: write Python code that calls back and forth from and to C or C++ code natively at any point. 即 将Python代码翻译为C代码。之后就可以像前面文章介绍的C语言扩展Python模块使用这些C代码了。 我的理解:这个是python代码=>c代码,然后编译,然后再用python调用so,不是我理解的用c代码写功能,而是用python写,转成c。
- crnn虽然没有c++代码,但是依然生成一个*.egg结尾的文件夹,而不是一个zip文件,为何呢?原因是,他需要包含资源文件,所以使用package_data:
package_data={'crnn.config':['charset.3770.txt','charset.5987.txt','charset.6883.txt']},我们把资源文件放到了egg里,也就导致了,安装完的egg是一个文件了,而不是zip文件了。
好吧,终于折腾好了,然后一个python setup.py就把ctpn、crnn都装到了本地的库里面了,世界清静了💀….
终于可以开始构建Web镜像了
有了那个可以跑tensorflow-gpu、还填满了各种需要的pip包的基准base镜像,在加上我搞好的捋顺的代码结构,终于可以制作我的镜像了。
我要搞2个版本:
1、可以调用tensorflow-serving的docker的docker,绕口哈,就是他只是个web程序,模型是由tensorflow-serving docker加载的。
2、可以自己加载模型,并且可以对外服务,本质就是tensorflow模型预测+web程序的合体
你问我,我为什么要这么搞?
我就是觉得这样爽,我要各种情况都要支持啊:既支持tensorflow单独跑的方式,也支持和tensorflow-serving集成的方式跑。对了,关于tensorflow-serving的趟坑之旅,可以参考我的这篇。我甚至,还可以让代码支持不用docker的方式跑,方便调试嘛。
好啦,奇怪的废话不说了,继续。
其实,制作Web镜像,并没有太多需要说的地方,就只注意以下几点:
- git pull代码这事,我是不管的,不在容器里git pull,不好,交给外面去,交给运维的同志们去搞
- 所以,我要做的就是把代码ADD到镜像里即可
- 然后要运行了c++的库的编译安装过程,我搞了个install.sh,运行一下即可
依然,docker build,运行,既可以,生成我们需要的ocr.web镜像啦。
好吧,看最后的Dockerfile.
基准Image的dockerfile
# 基于tensorflow/tensorflow:1.14.0-gpu-py3生成一个基础镜像
# 他满足了:nvidia支持、pytnon3支持、ubuntu支持
From tensorflow/tensorflow:1.14.0-gpu-py3
MAINTAINER piginzoo
ADD config/sources.list /etc/apt/sources.list
RUN apt-get update
RUN apt-get install -y libsm6
RUN apt-get install -y libxrender1
RUN apt-get install -y libxext-dev
RUN apt-get install -y language-pack-zh-hans
ENV LANG zh_CN.UTF-8
ENV LANGUAGE zh_CN:zh
ENV LC_ALL zh_CN.UTF-8
# 安装所需要的第三方包
ADD ocr/requirements.txt /home/requirements.txt
RUN pip install -r /home/requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
容器启动
终于终于,可以把程序跑起来啦,好开森啊。🤪
全靠环境变量传入参数
记得不?我说过,我的程序要能单独跑,也能和tensorflow-serving配合跑;可以在容器里面跑,还要可以不用容器也可以跑(调试用)。为了满足上述各种方式,我也拧巴了一阵。
开始我是在Web的启动脚本里,加了一堆的启动参数。使用linux本身自带的getopt。对了,linux还带一个getopts,虽然多了个s,但是不如getopt好用,主要是不支持长参数(例如–mode=xxxx)。另外,mac的getopt和linux的,还不太一样,会导致你开发过程有问题,解决之道是装一个gnu-getopt:brew install gnu-getopt。然后,我想在容器启动的时候,传给容器不同的参数,来动态决定是单独跑还是和tensorflow-serving集成,多好啊。
但是,现实是残酷的。要往runtime的容器里面传入参数,只能通过环境变量,靠!苦恼死了。只好调整我的启动shell脚本,都改成了传入环境变量,而且,还得改python脚本,从环境变量里面读取各种参数,其中折腾和滋味就不说了。
现在的Web服务启动脚本变成了这个样子:server.sh。
最终我们定义了2个重要参数:
- 模式:single;tfserving,来决定是单独启动,还是配合tensorflow-serving方式启动
- 端口:对外服务的端口
容器启动脚本
然后,我们就可以针对我们不同的模式,传入不同的环境变量,来启动容器了。
由于这种方式,需要mount不同的文件和文件夹,导致,docker启动的脚本也有不同,主要是挂载不同的docker容器的目录:
- 对于单独启动的方式,要挂载模型文件目录、日志目录、以及web服务的配置文件目录
- 对于配合tensorflow-serving方式的容器启动方式,需要挂载SavedModel模型的目录到tensorflow-serving的容器上
好,可以参考docker.sh。
容器编排
到这里,貌似一起要结束了,可是,并没有。
我们需要放到生产环境,是需要服务编排的:
Docker Compose定义和运行多个Docker容器的应用,多个容器相互配合来完成某项任务的情况。例如要实现一个 Web 项目,除了 Web服务容器本身,往往还需要再加上后端的数据库服务容器,甚至还包括负载均衡容器等。Compose 恰好满足了这样的需求。它允许用户通过一个单独的 docker-compose.yml 模板文件(YAML 格式)来定义一组相关联的应用容器为一个项目(project)。 概念:
- 服务 (service):一个应用的容器,实际上可以包括若干运行相同镜像的容器实例。
- 项目 (project):由一组关联的应用容器组成的一个完整业务单元,在 docker-compose.yml 文件中定义。 一个项目可以由多个服务(容器)关联而成,Compose 面向项目进行管理。 “项目是关键,包含多个服务!”
好,那就开始写docker-compose文件吧。
我分成了2个文件:docker-compse-single.yml和docker-compse-tfserving.yml。分为2个的原因,是因为两种方式的容器启动方式是不一样的,“single方式”启动一个容器就可以,就是web服务容器;而“tfserving方式”,要启动Web服务容器、tensorflow-serving容器,2个容器。而且两种方式还要一些不同的环境变量需要传入,所以写成2个编排文件。未来在生产环境下,会主要使用“tfserving方式”的编排方式。
实操安装步骤
这里,把整个的安装步骤,列出来,为后续部署提供手册:Tensorflow官网提供的参考
我们上面讨论过了,只需要在宿主机上安装GPU显卡驱动即可,其他的CUDA tookit、cuDNN都不需要了。另外就是安装一下nivdia-docker:
- 显卡驱动
- nivdia-docker
安装显卡驱动
1.下载显卡驱动:nvidia官网驱动下载,选择:Tesla/P/P40/P/P40/RHEL7/CUDA10.0。
这里有个快捷下载通道:下载地址;或者wget直接获得:
wget https://developer.download.nvidia.com/compute/cuda/repos/rhel7/x86_64/cuda-10-0-10.0.130-1.x86_64.rpm
为何要选择CUDA10.0? 原因是,我们的Docker采用的是tensorflow1.14,这个版本需要匹配CUDA10.0. Tensorflow版本和CUDA版本的对应关系:对应关系详细信息
2.安装显卡驱动: 在Linux(我们是CentOS7)中安装:参考nvidia官网安装驱动
详细步骤(大自然搬运工,详细还是去参考官网安装步骤链接):
lspci | grep -i nvidia,看看您的是什么显卡uname -m && cat /etc/*release,去看看操作系统信息gcc --version,确定GCC版本sudo yum install kernel-devel-$(uname -r) kernel-headers-$(uname -r),需要安装开发devel-libs
安装:
- rpm --install cuda-10-0-10.0.130-1.x86_64.rpm
- yum clean expire-cache
- yum install nvidia-driver-latest-dkms
- yum install cuda
如果一切顺利,就可以敲nvidia-smi,看到显卡信息了。
可悲的是,我们并不顺利,好吧,请看我们的悲惨遭遇。
安装Nvidia Docker
不同于普通docker,我们需要安装由nvidia公司提供的特殊版本的docker服务:
运行以下命令:
$ distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
$ curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.repo | sudo tee /etc/yum.repos.d/nvidia-docker.repo
$ sudo yum install -y nvidia-container-toolkit
$ sudo systemctl restart docker
悲惨趟坑和正确姿势
悲惨的趟坑之旅
前面讲过正常的流程,我们却十分坎坷的遇到了各种问题,从下午3点一直忙到10点,才搞定,好吧,我们来说说:
我们在安装kernel-devel的时候,就发现,uname -r显示的kernel版本,和我们默认安装yum install kernel-devel的版本不一致,我们的 uname -r显示的是kernel 3.10.0-957.el7.x86_64,而我们装上的kernel-devel版本是3.10.0-1062。这个我们其实到最最后也不知道是不是这个问题导致我们后续的显卡问题,后来,我们把kernel都升级到了1062个build版本,这个问题,其实是个插曲。
我们照着上面流程安装完gcc、kernel-devel、nvidia-driver-latest-dkms、cuda后,敲入 nvdia-smi,我们得到了:
NVIDIA-SMI has failed because it couldn't communicate with the NVIDIA driver. Make sure that the latest NVIDIA driver is installed and running.
悲桑~
于是,我们就开始各种的自我怀疑和乱投医,我们尝试了多种后来看来完全没有作用的尝试,都是始终面对上面这个错误的桑心:
- 开始装错了cuda.repo版本,居然装成了7,但是改成10,依然桑心
- 我们去https://developer.nvidia.com/cuda-downloads,去下载runfile(cuda_10.2.89_440.33.01_linux.run,乖乖2G呢),运行了,报一个莫名的错
- 我们也推荐同样这页推荐的rpm(network)方式,依然桑心
sudo yum-config-manager --add-repo http://developer.download.nvidia.com/compute/cuda/repos/rhel7/x86_64/cuda-rhel7.repo sudo yum clean all sudo yum -y install nvidia-driver-latest-dkms cuda sudo yum -y install cuda-drivers - 我们还尝试多种错误姿势,都无果
后来,我们发现根本不能按照nvidia官网的文档来装,因为他的那个流程里,根本没有让我选择究竟是哪一款显卡的过程,这怎生靠谱呢?
我们后来按照显卡型号寻过去,下载驱动,然后再装各类东西,才搞定的,后面会提及。
装好,驱动后,运行nvidia-smi,可以显示正常了。可是和docker的集成还是有问题的。我们安装的nvidia-docker,然后下载了nvidia家的测试容器:nvidia/cuda,然后运行测试命令docker run --gpus all nvidia/cuda nvidia-smi,ok了。
于是,我们去尝试启动我们的compose文件:docker-compose up …..,结果报错,说compose不认识runtime=nvidia参数。哦,我意识到了,是需要修改compose文件中的runtime参数为gpus,于是修改之,结果继续报错,2.3的compose是不支持–gpus参数的,我谷歌后,看到大家都抱怨这个问题,貌似nvidia还没有给出一个官方的支持,怎么办?
那必须得装老版本的nvidia-docker2,才可以重新支持runtime这个参数,至于gpus参数嘛,彻底放弃了。
于是安装nvidia-docker2,安装完,重启docker(这点很重要),立刻就好了。
期间还装了nvidia-docker-compose,pip方式装的,其实没啥用。
正确姿势
好吧,我们来说一下,我们在CentOS 6.7.1810/Kernel 3.10.0-957.el7.x86_64上正确安装Nvidia Tesla P40的正确的姿势:
- 正确的升级kernel,此举是否是必须,其实我们也不是特别自信,但是至少我们是做了,让kernel的版本和kernel-devel的版本一致了(这个问题前面谈过了):
yum install kernel-3.10.0-1062.4.3.el7.x86_64 - 去https://www.nvidia.com/Download/index.aspx?lang=en-us,选择Tesla/P40/64bit-REHL7/10.0,选择正确的驱动。
- 然后,你应该得到这个http://us.download.nvidia.com/tesla/410.129/nvidia-diag-driver-local-repo-rhel7-410.129-1.0-1.x86_64.rpm,对!是一个rpm。
- 安装他:
rpm -i nvidia-diag-driver-local-repo-rhel7-410.129-1.0-1.x86_64.rpm - 没完,还要安装一个
yum install cuda-drivers - 重启!就ok啦!
全套:
# 升级内核,需要3.0,这个不知道是否是必须,好像是要和安装的kenerl-dev的版本匹配
yum install kernel-3.10.0-1062.4.3.el7.x86_64
# 下载P40对应的显卡驱动,这个是通过官网的下载网页按型号查找到的
wget http://us.download.nvidia.com/tesla/410.129/nvidia-diag-driver-local-repo-rhel7-410.129-1.0-1.x86_64.rpm
# 安装驱动
rpm -i nvidia-diag-driver-local-repo-rhel7-410.129-1.0-1.x86_64.rpm
yum clean all
# 安装CUDA
yum install cuda-drivers
reboot
# 安装nvidia-docker2,一定要是版本2,这个版本虽然旧,但是支持runtime选项
yum install nividia-docker2
systemctl restart docker
#最后测试:
docker run --runtime nvidia nvidia/cuda nvidia-smi,可以看到GPU的细节,OK!
血泪史:
- 去https://developer.download.nvidia.com/compute/cuda/repos/rhel7/x86_64/直接去下驱动,不靠谱!
- 按照官网去安装https://docs.nvidia.com/cuda/cuda-installation-guide-linux/#abstract,不靠谱!
- 官网的都是让你去下载一个allinone包,根本没地方让你选择p40的卡的型号,我们还奇怪呢?怎么这么智能?其实,实践告诉我们,不靠谱!
总结
终于,这事差不多了,最后总结一下,为了让部署一个完整的支持GPUTensorflow程序上线,你需要做:
- 构建一个基础镜像,让其支持GPU,支持tensorflow-gpu,并安装好各种包
- 构建你的web容器,编译好ctpn中的c++动态库,使用本地安装包方式部署好代码
- 容器启动采用环境变量的方式传入需要的动态参数,并且,mount好各自的目录
- 最后使用docker编排服务,绑定好各自需要的内容