
为什么要使用tensorflow serving
我是很讨厌这种东西的,其实,之前用flask挺好的啊,我自己加载模型,对外服务。可是,我遇到了问题,就是我flask是多进程,多进程,想共享模型的是有问题的。啥问题来着,我忘了,不好意思,反正肯定是有问题的。后来,我不得不每个worker进程就加载一次模型,这样,一个GPU很快就被撑爆了,我试了一下,最多只能起3个worker进程,也就是只能最多塞3份模型进GPU了。否则就OOM了。
后来我去网上谷歌,也没啥好方案,都推荐用tf-serving,去大神群(QQ群:785515057)问,大家的回答也是一致,就是用tf-serving吧,再看看人家官网上,一通吹牛逼,就屈服了。
tensorflow serving是什么
说白了,就是一个帮你管理模型的一个服务。我开始以为他提供web服务呢,发现虽然可以,但是远远不够。他对外主要支持grpc服务和restful服务,但是没地方给你做预处理的地方,就是仅仅封装好模型的入口和出口的一个api。所以,一般大家都要在外面,再跑一个flask web 服务,用来做预处理和后处理。
不过,他也干了不少事:
- 帮你加载一份模型,恩,对,我就是这个问题解决不了,不够,不知道他肚子里面的进程、线程模型,黑盒
- 要提高性能,他提供了一个batch机制,大白话解释,就是他帮你凑一波请求,动态凑成一个batch,交给GPU去处理,这事对你是透明的,你就管一个个的向他请求,他去凑,这事儿挺酷的
- 他给你弄个了docker,你docker pull后直接用,省去了不少麻烦
恩,想想,他也就是干了这些事。
版本的选择和安装
docker pull tensorflow/serving:1.12.3-gpu
目前tensorflow serving的docker最新的版本是1.14,但是1.14/1.13是需要CUDA10和cuDNN7.4的支持,我们的环境是CUDA9和cuDNN7.0,所以我们只能选择1.12.3(支持CUDA9里最新的)
关于tensorflow和CUDA和cuDNN的关系,请参考:tensorflow CUDA cudnn 版本对应关系
未来新机器来了,我就装CUDA10了,用最新的了。
(不过,貌似CUDA9也可以支持tf-serving 1.14,不受影响,tensorflow-gpu 1.14不行而已,好像是哈,懒得去验证了)
模型的导出
tf-serving要用SavedModel格式,我们往往训练出来的是Checkpoint格式,要转。
tensorflow的模型有两种格式:
- Checkpoint格式,是我们一般保存格式的方式,目前的github上代码都是这种格式
- SavedModel格式,是一种独立于语言且可恢复的神秘序列化格式
Tensorflow Serving必须使用SavedModel格式,所以要转一下:
以CTPN的model转化为例子:
session = tf.Session(graph=g)
saver.restore(sess=session, save_path=ckptModPath)
builder = SavedModelBuilder(savedModelDir)
inputs = {
"input_image": build_tensor_info(input_image),
"input_im_info": build_tensor_info(input_im_info)
}
output = {
"output_bbox_pred":build_tensor_info(bbox_pred),
"output_cls_prob": build_tensor_info(cls_prob)
}
prediction_signature = build_signature_def(
inputs=inputs,
outputs=output,
method_name=tf.saved_model.signature_constants.PREDICT_METHOD_NAME)
builder.add_meta_graph_and_variables(
sess=session,
tags=[tf.saved_model.tag_constants.SERVING],
signature_def_map={tf.saved_model.signature_constants.DEFAULT_SERVING_SIGNATURE_DEF_KEY: prediction_signature})
builder.save()
- build_tensor_info方法来构建一个输入入口名字的绑定,需要传入一个张量,这个张量还是要定义的,同样输出也需要这样绑定
- 基本上就是这样的模板代码,没啥好改的,照着写就成了
- add_meta_graph_and_variables的参数tags,好像必须定义成这个SERVING,我尝试改了,报错,后来忙,也没顾上研究了,改回去了
模型的使用
好了,要跑起来了,就是启动谷歌提供的那个封装好tensorflow serving的docker镜像了。
模型使用是一个封装好的谷歌提供的docker image,这个image不允许你修改,只能用。他也提供了可以打开修改的开发版,我没有玩。
# "--runtime=nvidia":启动nvidia-docker,是一种特殊的docker,支持GPU资源管理
docker run \
--runtime=nvidia \
-e NVIDIA_VISIBLE_DEVICES=1 \
-t --rm \
-p 8500:8500 \
--cpus=10 \
--mount type=bind,source=$CRNN_MODEL,target=/model/crnn \
--mount type=bind,source=$CTPN_MODEL,target=/model/ctpn \
--mount type=bind,source=$CONFIG,target=/model/model.cfg \
tensorflow/serving:$TF_VERSION-gpu \
--model_config_file=/model/model.cfg
- runtime=nvidia实际上就是启动了nvidia的docker,当然你可以直接启动nvidia-docker
- cpus=10,用cpu的数量,实际上,这个只是说,你可以使用到1000%的cpu使用率,而不是给你分配10个cpu,比如给你分配20个cpu,每个上面都限额到50%的使用率,当然调度细节还是取决于docker自己
- model_config_file指定了docker内部的配置文件的路径,这个路径是用mount绑定上去的
- e NVIDIA_VISIBLE_DEVICES=1,实际上还是通过制定环境变量的方式,制定使用哪个显卡
- p,指定了对外服务的grpc的端口
上一步骤中,导出后的模型是这个样子:
└── ctpn
├── 100000
│ ├── saved_model.pb
│ └── variables
│ ├── variables.data-00000-of-00001
│ └── variables.index
├── 100001
│ ├── saved_model.pb
│ └── variables
│ ├── variables.data-00000-of-00001
│ └── variables.index
- 100000,100001,这个所谓的版本号完全是自己控制的,你也可以写成100,101之类的
- 但是,tf-serving的docker可当真,他真会按照这个目录中的目录数字编码,找最大的,认为是最新的
- 这个模型的更新和部署后,你不用管,tf-serving会自动加载最新的对外服务,这个是很牛逼的特性,热部署啊
配置文件样例如下:
model_config_list: {
config: {
name: "crnn",
base_path: "/model/crnn",
model_platform: "tensorflow"
},
config: {
name: "ctpn",
base_path: "/model/ctpn",
model_platform: "tensorflow"
}
}
没啥,就是指定好多个模型的目录,很明了。多模型的方式,就没办法通过docker run的时候灌入,只能靠这种配置文件的方式了。
问题
本来,git pull安装好tf-serving docker,转好模型格式,然后docker run之后,就可以对外服务了,可是偏偏老天存心折磨我,让我遇到很多坑和问题:
CTC的SparseTensor的问题
CRNN最后一步是ctc推断,得到的是一个SparseTensor,本来,模型转化的时候,把这个输出,通过build_signature_def绑定好就成,模型转化的时候没问题。但是在跑起来的时候,做预测之后,返回给客户端的时候,报错:
File "/app.fast/projects/ocr_tfs/ocr/module/crnn/crnn.py", line 52, in crnn_predict
response = stub.Predict(request, 60.0)
File "/root/py3/lib/python3.5/site-packages/grpc/_channel.py", line 514, in __call__
return _end_unary_response_blocking(state, call, False, None)
File "/root/py3/lib/python3.5/site-packages/grpc/_channel.py", line 448, in _end_unary_response_blocking
raise _Rendezvous(state, None, None, deadline)
grpc._channel._Rendezvous: <_Rendezvous of RPC that terminated with:
status = StatusCode.INVALID_ARGUMENT
details = "Tensor :0, specified in either feed_devices or fetch_devices was not found in the Graph"
debug_error_string = "{"created":"@1568700637.666090704","description":"Error received from peer","file":"src/core/lib/surface/call.cc","file_line":1095,"grpc_message":"Tensor :0, specified in either feed_devices or fetch_devices was not found in the Graph","grpc_status":3}”
这个问题的原因就是,貌似SparseTensor这个张量不在计算图里,我觉得是tf的bug,不过网上有解决方案,就是把SparseTensorf的3个分量分别拆成3个张量,作为输出,绑定到模型输出上:
SparseTensor的3个分量绑定:
output = {
"output_indices": tf.saved_model.utils.build_tensor_info(decoded.indices),
"output_values": tf.saved_model.utils.build_tensor_info(decoded.values),
"output_shape": tf.saved_model.utils.build_tensor_info(decoded.shape),
}
实际上,原有模型无需重新训练,只要把之前的SparseTensor的3个分量取出来分别绑定,原有代码和模型都是无需调整的。
好吧,就这样忍了,3个输出就3个输出吧,不纠结了。
参考:Assign the name to SaprseTensor when build_tensor_info of it:“The problem can be solved by exporting the three dense tensor of the Sparse Tensor instead of exporting the Sparse Tensor itself”.
CTC的BeamSearchDecoder慢问题
CTC的问题,就是慢,开始以为是beam_width的问题,调试了之后,发现确实为1。后来以为是docker的问题,后来发现,就是ctc的beamSearchDecoder慢,谷歌发现有人也反馈慢,tf.nn.ctc_beam_search_decoder is very slow on tf >=1.4,但是就搜到了这么一篇。
测试了一下之前的tensorflow1.9 vs 1.14版本,都是直接运行模型(不是通过tf-serving)的模型,就是想看看ctc的情况。 写了一个CTC测试代码,
tensorflow1.14版本: batch=128,sequence=50 BeamSearch耗时:18秒 batch=128,sequence=128 BeamSearch耗时:46秒
tensorflow1.9版本: batch=128,sequence=50 BeamSearch耗时:13秒 batch=128,sequence=128 BeamSearch耗时:33秒 batch=128,sequence=64 BeamSearch耗时:33秒
结论对比1.9,1.14性能下降了。大概下降了30%左右。目前没有分析出是什么原因。
另外,我之前理解beam_width=1的beam_search_decoder就是greedy_decoder的想法是错的,原因是:
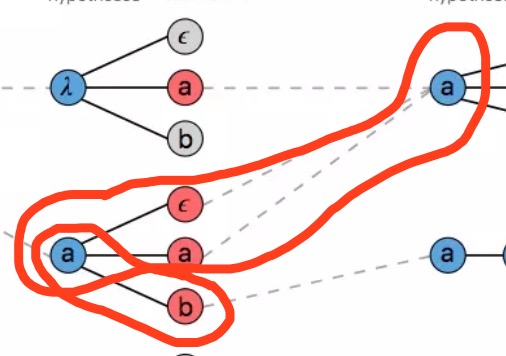
如图,考虑beam_width=1,你不是从红色里面挑一个最大的就成,而是要算$p(a)*p(\epsilon)+p(a)*p(a)$和$p(a)*p(b)$,要比一下谁大,所以,然后保留谁,所以不是简单的就算。
想明白这事后,我本来想自己实现各beam_width=1的beam_search_decoder来着,不过一搜,有开源的,CTCDecoder,于是我下来一个,一测,效果其实比tensorflow的ctc要差很多(我就测的是beam_width=1,sequence=128,batch=128,classes=3862),所以,虽然tensorflow1.14的慢很多,也只有忍了。
版本的问题
之前用的是1.14,直接拉取了最新的,他回到导致 你还必须得pip安装tensorflow-serving-api-gpu版本,因为他会自动关联安装tensorflow-gpu的对应版本,貌似,版本是一一对应的,比如tensorflow-serving-api-gpu:1.14会自动安装tensorflow-gpu:1.14版本,这很恼人,因为会卸载你服务器上的稳定的tensorflow-gpu版本,导致你别的项目的训练出问题。(这里不用吐槽我们为何不用docker隔离训练,你吐槽的对,不过最近不顾不上,回头再搞)。
好吧,最后的方案确定:
tensorflow-serving-api 1.14.0 + tensorflow serving docker 1.14,不考虑tensorflow的低版本了,但是这个环境无法用于训练。