
最近开始着手单据扫描的事情,这篇博客主要记录自己的学习笔记。
1.综述
单据识别,其实就俩事,一个是识别字块,也就是文本检测,就是找到字所在的区域;一个是OCR,也就是把字块中的字一个个地识别出来。
A.字块识别(文本检测),比较流行的算法就3个,CTPN、EAST、Seglink,这仨都是咱们国人搞出来的,小自豪一下。这篇小文写的不错,可以参考读一下。
字块识别(文本检测)是发展于目标检测,目标检测本质就是找到包含物体的框,典型的算法有YOLO,SSD,以及Faster-RCNN,而CTPN可就是从Faster-RCNN发展而来的。而Faster-RCNN,又是从RCNN,Fast-RCNN,Faster-RCNN一脉相承地发展而来。
B.再说说OCR的方法,我看到的也就是CRNN了,别的我也没看到有啥更牛逼的方法了。
不得不提一下,我对传统图像处理方法,一窍不通,所以这篇文章,讲的都是深度学习的方法。之前图像方法的巅峰之作,就是谷歌开源出来的tesseract了吧。
另外,不得不说一下,要不是之前各类VGG,CNN,ResNet等深度图像识别网络的大发展,哪有现在这些文本检测呀,这脉络是图像识别->目标识别->文本识别,文本识别里面最基层干活的还是这些基础网络,俗称backbone啊,一般都用VGG16,虽然不是最好的,但是简单易用,transfer迁移学习过来,妥妥的了。
我理解大致就这些,干活也是指望这点水儿,不断地挖掘理解,可能有片面之处,看官们还多海涵我的粗浅,希望探讨的可以点击关于,速速与我联络,共同探讨。顺道说,这文章没探讨太多细节,细节都在给的那些大神们写的各种参考文档里面,我就不太多班门弄斧了,这里我写的都是我觉得我的一些理解和补充的东西。其实….,其实这篇文档主要是写给自己,怕自己过段时间就把这些玩意忘光了,回头一看迅速可以回忆起来,哈哈。
欢迎转载,但是必须给我一个外链哈。
2.前戏,先说说目标检测
字块识别、文本检测、文字块检测,叫啥都成,就要得到包含文字的一个框。
说起这玩意,不得不提提,目标检测,也就是Faster-RCNN等那一坨模型。都有啥?主要是RCNN、Fast-RCNN、Faster-RCNN、SSD、YOLO、YOLO-v3。恩,我知道的有点名气的就这些。
其实牛逼点的就3:
- RCNN家族:RBGRoss B. Girshick大神搞的,RCNN -> Fast-RCNN -> Faster-RCNN
- YOLO:大神RBG又搞了,果然是大神啊,速度更快,V3是现在的主流
- SSD:没啥人用了,中科院大神搞的
一张脑图,可耻的盗过来,一目了然:引自
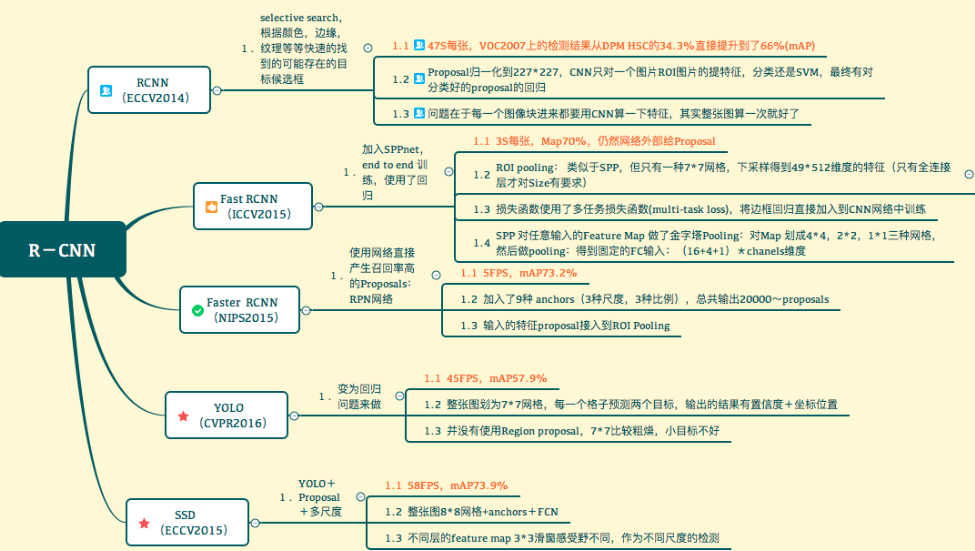
RCNN
RCNN就是文本检测最早的一个特别糙的一个模型,就是大神Ross B. Girshick搞的,一口气完成这3个,开启了深度学习目标检测的大门。我等必须崇拜一下。
RCNN本质是啥,讲人话就是,用EdgeBoxs、SelectiveSearch,聚类之类的方法,得到一堆(大约2000个左右)的候选框,就是可能包含对象的框(也叫proposal),然后把这些子图归一化,然后交给一个VGG16抽取特征。最后,灌给一个分类器和一个回归器:Bbox回归器确定边界,SVM分类器确定是不是物体。速速点击参考一探究竟。(七月老师这篇写的很详细了)
细节:
SVM训练的图是提前切出来给你丫训练的,上面说SVM只是应用你训练好的模型应用而已;说白了,就是切无数的图,有的包含物体,有的不包含,然后喂给SVM分类器去训练这个SVM分类器。
那个BBox回归也是,回归的是(x,y,w,h),告诉你坐标在哪里,宽高调整多少。
RCNN算法分为4个步骤
1) 一张图像生成1K~2K个候选区域 (图像分割算法例如 selective search)
2)对每个候选区域缩放到固定尺寸,使用深度网络提取特征 (CNN模型训练有两步组成:在 ImageNet上的预训练,在检测数据上的微调)
3) 特征送入每一类的SVM 分类器,判别是否属于该类
4) 使用回归器精细修正候选框位置
Fast-RCNN
RCNN忒慢,识别一张需要40多秒,所以,RBG大神继续努力,搞了一个Faster-RCNN。
RCNN慢在2000多个候选图片都要经过VGG16算一遍,SSPNet改进这点,咋改进?因为VGG16,也就是CNN之后,得到的feature map(顺道说,feature map就是指你卷积过N次后,得到的那张图,其实丫已经不是张图了,你还可以当图来理解)。之前的某个proposal(备选框),就会对应feature map中的一个区域,(怎么对应,我其实也想特别想清楚,反正池化后,确实是缩小了,肯定是一块比较小的区域了),这样的话,你做一次卷积前向运算就得了,不用2000块都分别做了,快了吧。
但是有个问题,就是大小不一啊,怎么办?他搞了一个下采样池化,说白了,就是把他采样成一样大(50 x 50)的模样了。
Fast RCNN 的算法流程:
1)用selective search在一张图片中生成约2000个object proposal,即RoI。
2)把整幅图像输入到全卷积的网络中(这里也可以缩放图片的scale,得到图像金字塔,将多尺度图像送入卷积网络提取卷积特征)
3)在最后一个卷积层上对每个ROI求映射关系, 并用一个RoI pooling layer提取一个固定维度的特征向量。
(这里是借鉴了SPPNet中的 SPP网络层,比SPP网络层简单,只用一个尺度)
4)继续经过两个全连接层(FC)得到特征向量,RoI feature vector。
5)特征向量兵分两路,经由各自的全连接层(FC),得到两个输出向量:
第一个是分类,使用softmax,第二个是每一类的bounding box回归。
丫确实快多了,才0.4秒。
Faster-RCNN
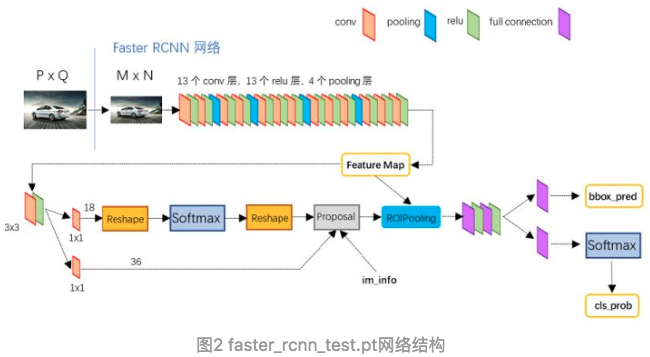
这次改进的是proposal,也就是候选框的备选的改进。把region proposal的步骤换成一个CNN网络(RPN)。
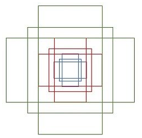
里面有个anchor的概念,就是一个可能的框,9个。大小套着,干嘛用的?就是可能是备选框。
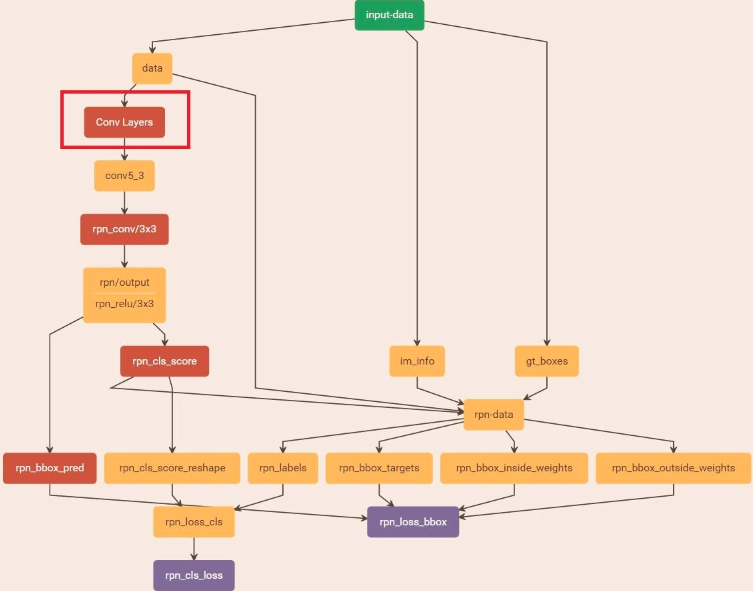
RPN(region proposal network)
2步,VGG16的第五层conv5的featuremap一个区域一定对应原图,feature map中的一个点,给丫套一个9个anchor,anchor是啥?就是个不同形状的框,这些anchor都是未来可能的包含被检测对象的proposal呀。
因为是经过了CNN池化缩小了,所以这些anchor区域,对应原图的更大的区域。
另外,这个点怎么选?就是画格,然后选中心。这个格子怎么画,画多少个?这是个超参数。
anchor长这个样子:
Faster R-CNN
1.对整张图片输进CNN,得到feature map
2.卷积特征输入到RPN,得到候选框的特征信息
3.对候选框中提取出的特征,使用分类器判别是否属于一个特定类
4.对于属于某一类别的候选框,用回归器进一步调整其位置
Tensorflow里面的model zoo里面的object detective就是用的faster-rcnn模型。
Faster-RCNN很重要,但是我在这里不讨论太多,都放到了CTPN里面讨论,CTPN中使用了很多Faster-RCNN的算法,在那里面讲清楚,毕竟,我们这篇博客是为了研究CTPN,CTPN才是猪脚。
最赞的代码是Facebook的大神Chen Xin Lei完成的,Github代码,讲代码的文章中,这篇讲的最好,传送门,其中的大图,太过赞叹,不得不贴出来:
YOLO
好吧,怎么都得提一句YOLO,毕竟也是大神RBG之作,而且现在是目标检测主流,只不过咱们搞单据识别不用而已。
Faster-RCNN都NM faster了,还是比YOLO慢。SSD是中科院搞的,很快也,但是准确率差些,不过用的人不多。YOLO好,不过YOLO的问题是作者都是基于自己的duck啥的框架写的。现在V3很赞了。
参考
-
对了,我是看july七月寒小阳的深度学习《物体识别》那节课迅速入门的。别问我视频哪里搞来的,我买的,你信不?
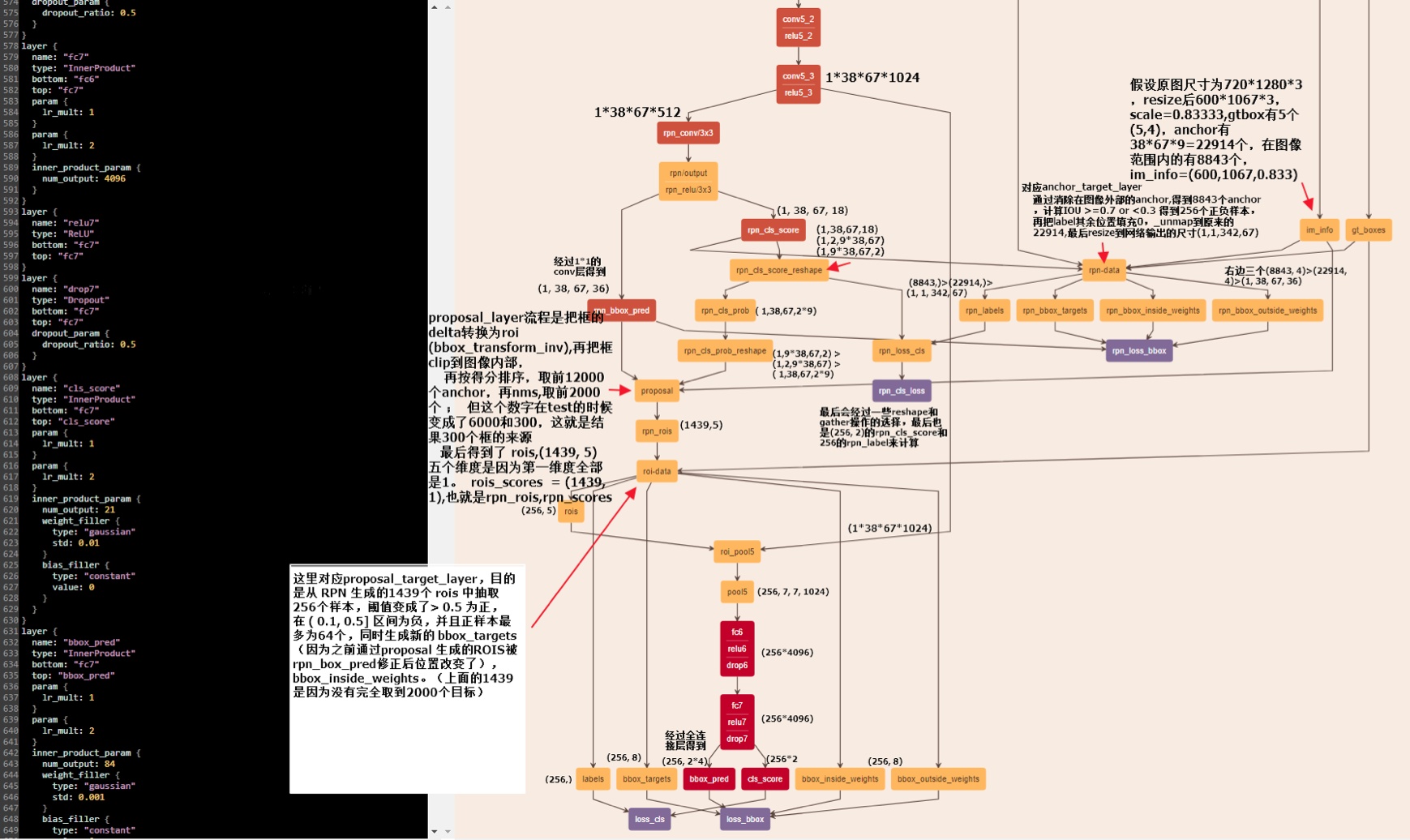
3.CTPN
前面讲啥呢?讲的都是目标检测,我们得用这些技术,来干嘛?找文字啊,文字就是我们要检测的目标啊。
我去!前戏太长了吧,好吧,猪脚终于登场。废话少说,直奔娘家:论文
这小图,浓缩了CTPN:
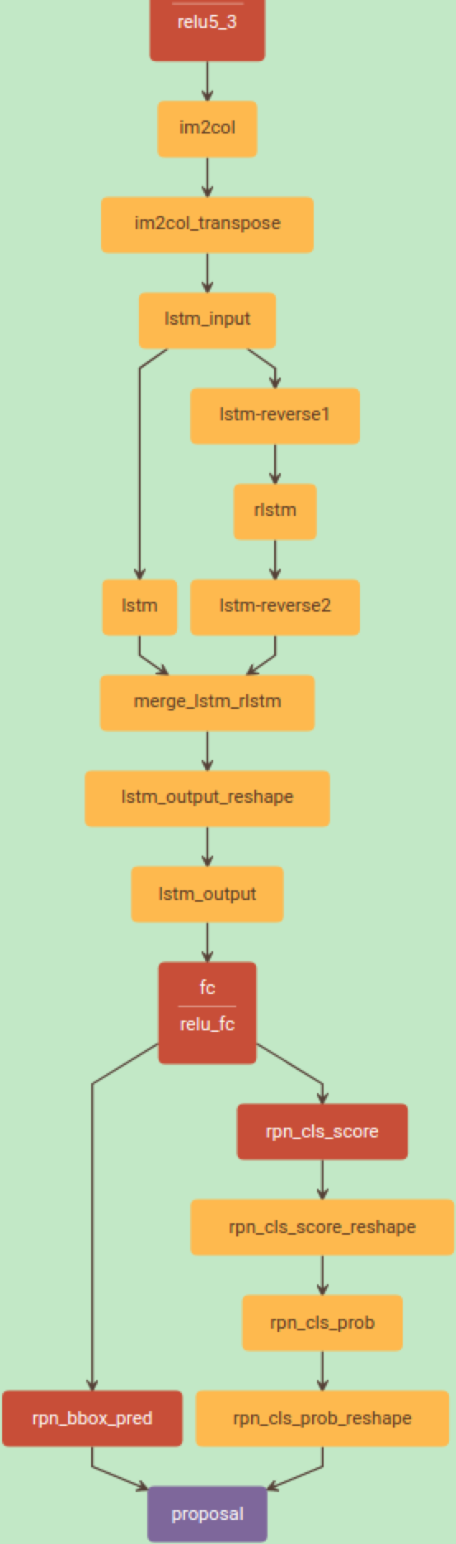
整个检测分六步:
第一,首先,使用VGG16作为base net提取特征,得到conv5_3的特征作为feature map,大小是W×H×C;
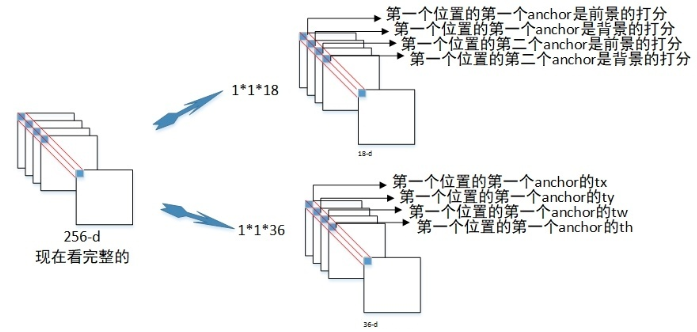
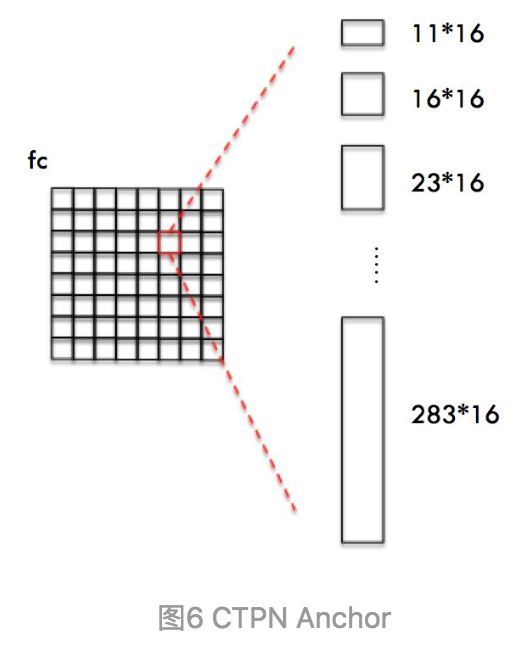
第二,然后在这个feature map上做滑窗,窗口大小是3×3。也就是每个窗口都能得到一个长度为3×3×C的特征向量。这个特征向量将用来预测和10个anchor之间的偏移距离,也就是说每一个窗口中心都会预测出10个text propsoal。
第三,将每一行的所有窗口对应的3*3*C的特征(W*3*3*C)输入到RNN(BLSTM)中,得到W*256的输出;
第四,将RNN的W*256输入到512维的fc层;
第五,fc层特征输入到三个分类或者回归层中。
第二个2k scores 表示的是k个anchor的类别信息(是字符或不是字符)。第一个2k vertical coordinate和第三个k side-refinement是用来回归k个anchor的位置信息。2k vertical coordinate因为一个anchor用的是中心位置的高(y坐标)和矩形框的高度两个值表示的,所以一个用2k个输出。(注意这里输出的是相对anchor的偏移),k个side-refinement这部分主要是用来精修文本行的两个端点的,表示的是每个proposal的水平平移量。这边注意,只用了3个参数表示回归的bounding box,因为这里默认了每个anchor的width是16,且不再变化(VGG16的conv5的stride是16)。回归出来的box如Fig.1中那些红色的细长矩形,它们的宽度是一定的。
第六,这是会得到密集预测的text proposal,所以会使用一个标准的非极大值抑制算法来滤除多余的box。
第七,用简单的文本线构造算法,把分类得到的文字的proposal(图Fig.1(b)中的细长的矩形)合并成文本线。
1.输入为3*600(h)*900(w),首先vgg-16提取特征,到conv5-3时(VGG第5个block的第三个卷积层),大小为512*38*57。
2.im2col层 512*38*57 ->4608 * 38 * 57 其中4608为(512*9 (3*3卷积展开))
3.而后的lstm层,每个lstm层是128个隐层 57*38*4608 ->57*38*128 reverse-lstm同样得到的是57*38*128。(双向lstm没有去研 究,但我个人理解应该是左边的结果对右边会产生影响,同样右边也会对左边产生影响,有空再去看) merge后得到了最终lstm_output的结果 256* 38 * 57
4.fc层 就是一个256*512的矩阵参数 得到512*38*57 fc不再展开;
5.rpn_cls_score层得到置信度 512*38*57 ->20*38*57 其中20 = 10 * 2 其中10为10个尺度 同样为512*20的参数,kernel_size为1的卷积层;
6.rpn_bbox_pre层 得到偏移 512*38*57 ->20*38*57。同样是十个尺度 2 * 10 * 38 * 57
因为38*57每个点每个scale的固定位置我们是知道的。而它与真实位置的偏移只需两个值便可以得到。
假设固定位置中点( Cx,Cy) 。 高度Ch。实际位置中点(x,y) 高度h
则log(h/Ch)作为一个值
(y-Cy) / Ch作为一个值
20 * 38 * 57 便是10个尺度下得到的这两个值。有了这两个值,我们便能知道真实的文本框位置了。
而这张图则是整个CTPN的全貌,不过,之前的VGG16省了
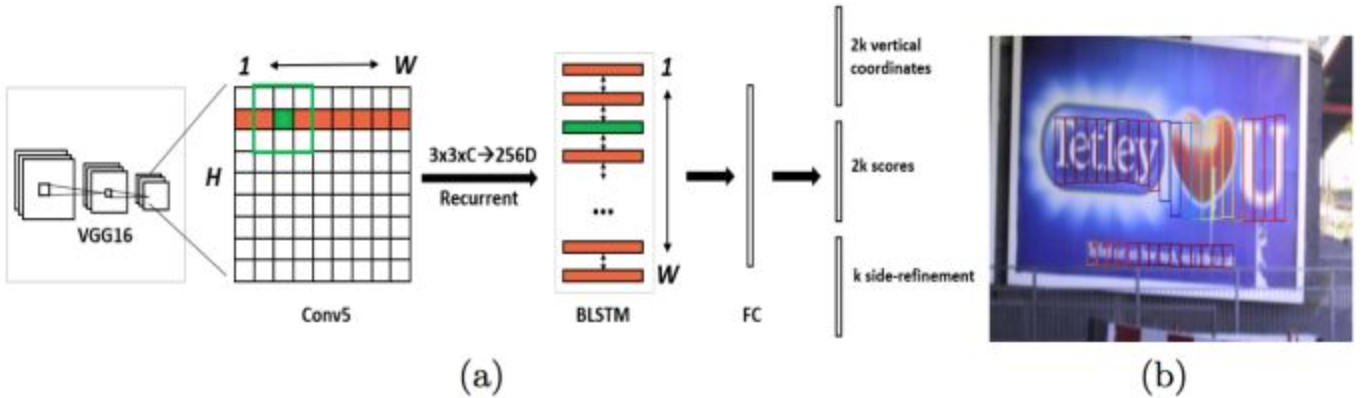
好,想搞清楚细节的,速速去看这篇,传输门,我这里只是看图说话,粗粗说一下我理解的核心思路:
- 还是老规矩,上VGG16,抽取图像特征,VGG抽取,其实图像的布局没变,CNN就是这个好处
- 出来的feature map,灌给双向Bi-LSTM,输出的最后的向量灌给全连接网络FC。您上面都VGG抽取了一圈了,干嘛又用LSTM又搞一圈,我理解是,要再一次抽取图像中的时序信息,毕竟我们的文字是一个序列啊。
- 学人家Faster-RCNN的RPN方法,学人家的anchor,不过我的anchor宽度固定,x位置固定,你丫9个,我10个。
- 然后对每个备选的anchor,左边分支用于bounding box regression做回归,右边分支用于Softmax做分类(二分类,你丫包含文字否)
- 完事了,把那些从anchor回归+分类后得到的text proposal串糖葫芦,成一个区域
我说说我的理解(好!讲人话):
CTPN,就是,
用VGG做了5层的CNN后,感受野(感受野概念就是说你池化后的区域对应的之前的大区域,具体的,您自己个儿谷歌一下吧)的抽象,其实就是把图像的特征给抽取出来了,但是,注意!这个时候,图像的布局没变,还是按照原有的布局,一行行的。只不过由于感受野的缘故,其实更有内涵[段子:]。
这个时候,把Conv5=>B-LSTM后的一行行的特征体现,也就是FeatureMap的每一行,的每一个点,这个点上扩展出10个anchor,然后你问我:这每个anchor是不是包含文字呀,介是个分类问题(2分类呀);需要大小(只有高)位置(只有y)咋个调整啊,介就是个回归问题。
你丫得到了啥,得到了每一个anchor的是否有字,高度和y,对吧?一串哈,每个点扩展的10个anchor都是被这回归和分类搞了一把。搞成啥了?留下那些包含文字的,这些框框,就是我要的text proposal啊。
最后,我用文本线构造算法连接在一起,串成一串,就得到文本位置啦。
总结一下,CTPN的核心就在于,借鉴了faster-rcnn的anchor做法,做了一个剪裁,只回归y和高度。用VGG+B-LSTM抽象出来的feature map,产生这些anchor,相当于一行一行地扫描图像,找出最终包含文字的小框框来。
所以,
训练数据就是每一个小框框呀,

对,就是每一个小红框。那,这标注可够变态的,是啊,所以,主要的样本,还是得靠生成,我看大部分小神们都是自己造样本的,好像还没好有看到有谁是花钱,去找人去标注的,这标注确实也太变态了吧。
CTPN思路是先检测小文本框,检测完合并,“分治法”
F-CRNN的RPN中anchor机制是回归预测四个参数(x,y,w,h),但是CTPN回归两个参数(y,h),即anchor的纵向偏移以及该anchor的文本框的高度,因为每个候选框的宽度规定为16个像素。
CTPN也有一个很明显的缺点:对于非水平的文本的检测效果并不好。
损失函数
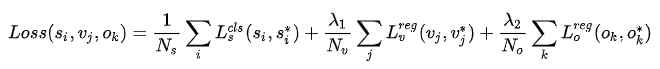
是三个损失函数合起来的:
- $L_s^{cls}(s_i,s_i^*)$
- $L_v^{reg}(v_i,v_i^*)$
- $L_o^{reg}(o_i,o_i^*)$
边框回归(Bounding Box Regression)
这个就是沿袭RCNN的概念,网上一堆的文章,感觉都没清清楚楚,拽了一堆公式,核心都没触及啊。
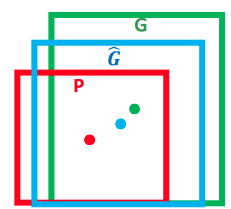
这图引用一下,他说的也没啥问题,就是要算P(P在这里就是Anchor框$\color{red}{红色}$),G($\color{green}{绿色}$)是GroundTrue,就是标注真实的物体所在的地方,$\hat{G}$ ($\color{blue}{蓝色}$),我们就是要让我们的P经过变化后,得到的$\hat{G}$尽量接近G。
那怎么得到呢?
方法就是寻找一种映射f, 使得 $f(P_x, P_y, P_w, P_h) = (\hat{G_x}, \hat{G_y}, \hat{G_w}, \hat{G_h})$,使得:$(\hat{G_x}, \hat{G_y}, \hat{G_w}, \hat{G_h}) \approx (G_x, G_y, G_w, G_h)$
这个映射就是这样:
(映射公式)
$\hat G_x = P_w d_x(P) + P_x , \text(1)$
$\hat G_y= P_h d_y(P) + P_y , \text(2)$
$\hat G_w= P_w exp(d_w(P) ), \text(3)$
$\hat G_h= P_h exp(d_h(P) ) , \text(4)$
(反向映射公式)
$t_x = \frac{(G_x-P_x)}{P_w}$
$t_y = \frac{(G_y-P_y)}{P_h}$
$t_w =log\frac{G_w}{P_w}$
$t_h = log\frac{G_h}{P_h}$
为什么是这样呢?我们回头再说,先留个包袱。
网上流传最多的一篇讲边框回归 Bounding Box Regression:
$P=(P_x, P_y, P_w, P_h)$,这个P是这个窗口对应的 CNN 特征,也就是 R-CNN 中的 Pool5 feature(特征向量)。
其实给人狠多误导,特别是你结合到Faster-RCNN和CTPN中就更对不上了。
其实,在Faster-RCNN中,这个$f(x)$其实就是一个卷积层(神经网络),也就是36个3x3的卷积核,与VGG的输出的Feature Map卷积后,得到一个[W*H*36]的张量,也就是他们那些文章中常说的“4k coordinates”,k其实就是9/10(Faster-RCNN中是9,CTPN中是10)。
那这36个都是啥,其实是对应9个Anchor框的回归值,参考下图:
第一个anchor的$t_x,t_y,t_w,t_h$,是的,其实就是得到了前面公式中提到的$d_x(P),d_y(P),d_w(P),d_h(P)$,然后你带入公式,就可以得到对应的$\hat G_x,\hat G_y,\hat G_h,\hat G_w$,就得到了对应的真正的包含物体的框。
那么,如何进行训练呢?
你不是提供了标签(Ground Truth)了么?那么就用这个框的坐标,算一下$t_x,t_y,t_w,t_h$呗,怎么算?带入 反向映射公式 中,就可以算出来了。而$t^*$则是通过卷积的神经网络算出来的。这不,就有偏差了么?然后带入损失函数,反向梯度传导,就可以计算参数了呗。
里面有一些细节,
我在训练的时候,我算GT对应的$t$的时候,用的是那个$P_w,P_h$呢?$P_x,P_y$不用担心,因为9个Anchor都是一样的,但是他们的$P_w,P_h$是不一样的,我用哪一个呢?这个不用担心,可以通过计算和GT的IoU,大于0.7的,才用来做计算:
通过对所有的anchor与所有的GT计算IOU,由此得到 rpn_labels, rpn_bbox_targets, rpn_bbox_inside_weights, rpn_bbox_outside_weights这4个比较重要的第一次目标label,通过消除在图像外部的 anchor,计算IOU >=0.7 为正样本,IOU <0.3为负样本,得到在理想情况下应该各自一半的256个正负样本(实际上正样本大多只有10-100个之间,相对负样本偏少)
所以,只有正样本才会用来计算损失函数。
说俩术语:
机器学习里经常出现ground truth这个词,在有监督学习中,数据是有标注的,以(x, t)的形式出现,其中x是输入数据,t是标注.正确的t标注是ground truth, 错误的标记则不是。
两个矩形交集的面积/两个矩形的并集面积
NMS(非极大值抑制算法 Non-maximum suppression)
【参考】
- https://www.jianshu.com/p/d2c7f6d9708f
- https://zhuanlan.zhihu.com/p/37489043
- https://www.cnblogs.com/makefile/p/nms.html
在干嘛?

就是从这些框里面挑一个靠谱的,这些框都带着置信度,是不是前景的置信度(或者是某一类的置信度)。
非极大值抑制的流程如下:
- 根据置信度得分进行排序
- 选择置信度最高的比边界框添加到最终输出列表中,将其从边界框列表中删除
- 计算所有边界框的面积
- 计算置信度最高的边界框与其它候选框的IoU。
- 删除IoU大于阈值的边界框
- 重复上述过程,直至边界框列表为空。
听着挺复杂,其实,大白话就是,你先找个置信度最高的框,剩下的和他相交面积比较大(我已经是最像的了,你们跟我类似的统统抛弃)的都删掉。
代码
还有一个讲代码的帖子,写的很不错,mark一下也。
$\color{blue}{如何训练?}$
训练数据如下:
208,162,223,229
224,162,239,229
240,162,255,229
256,162,271,229
272,162,287,229
288,162,303,229
就是每一个小块(宽度为16)的小块,组成一个图像,所以是一堆的小块坐标,如图:

那你想了,我靠,我做标注不得标死。
参考文档
-
这篇写好好详细,好详细,最好的一篇:场景文字检测—CTPN原理与实现,里面有CRNN的链接,荐
“关于最后一部分的RPN网络: 1.左边分支用于bounding box regression。由于fc feature map每个点配备了10个Anchor,同时只回归中心y坐标与高度2个值,所以rpn_bboxp_red有20个channels。 2.右边分支用于Softmax分类Anchor” 解释: 10个Anchor就是10个备选框,那么就得看这10个点对应的备选框是不是准确,这个就是我们要回归预测的,但是宽度不用了,另外x不用了,所以参数就变成了高度调整和y的坐标,2个参数了。训练呢?训练是你之前会切成各个的小框 "多说一句,我看还有人不停的问Anchor大小为什么对应原图尺度,而不是conv5/fc特征尺度。这是因为Anchor是目标的候选框,经过后续分类+位置修正获得目标在原图尺度的检测框。那么这就要求Anchor必须是对应原图尺度!除此之外,如果Anchor大小对应conv5/fc尺度,那就要求Bounding box regression把很小的框回归到很大,这已经超出Regression小范围修正框的设计目的。" 解释: 这块要注意,回顾的是原始图片中的框坐标和高度,标签数据也是这么给出的。 “获得Anchor后,与Faster R-CNN类似,CTPN会做如下处理: 1.Softmax判断Anchor中是否包含文本,即选出Softmax score大的正Anchor 2.Bounding box regression修正包含文本的Anchor的中心y坐标与高度。” 解释: 可以想象,每一行的anchor,还原回去就是一个框,他上下,包含的文本高度在哪里?标签中是有这些信息的,对吧?然后你就可以对应做出调整了。另外,输入的其实以工行一行输入的,是原有1/16了,而是有“感受野”,所以最后的feature map中其实还包含了一些周边的信息的,不仅仅是原始图片框那个子区域图像。 -
小哥演示手撸代码:【OCR技术系列之六】文本检测CTPN的代码实现,代码解释的很详细,很棒,适合深入代码的同学研读。他的同性交友网站Github链接,另外此小哥还写了一篇CTPN原理的帖子,写的也很好:【OCR技术系列之五】自然场景文本检测技术综述(CTPN, SegLink, EAST)
Faster-RCNN效果对文本检测不好:1.长宽比例不一致 2.边缘不闭合 3.文字间有间隔 CTPN思路是先检测小文本框,检测完合并,“分治法” F-CRNN的RPN中anchor机制是回归预测四个参数(x,y,w,h),但是CTPN回归两个参数(y,h),即anchor的纵向偏移以及该anchor的文本框的高度,因为每个候选框的宽度规定为16个像素闪光点: 1.分治法,探测小,然后拼 2.B-LSTM捕捉连续特性 3.Side-refinement(边界优化) CTPN也有一个很明显的缺点:对于非水平的文本的检测效果并不好 SegLink,CTPN小尺度候选框+SSD,文本检测state-of-art 回归,还提出了Segment和Linking两个重要概念 segment理解为文本行的一部分,可以是一个字符或文本行的任意一部分 Segment文本检测的跟CTPN很像,检测文本行的一部分,再把他们连接 跟ssd一样,他抽取了各个VGG层的feature map是为了,大小通吃“大的feature map擅长做小物体的检测,而小的feature map则擅长检测大物体” 把完整文本行先分割检测再合并的思路,有人提出质疑,觉得这种做法比较麻烦,把文本检测切割成多个阶段来进行,这无疑增大了文本检测精度的损失和时间的消耗,对于文本检测任务上中间处理越多可能效果越差。所以有篇CVPR2017的文章提出,我们有一种方法能优雅且简洁地完成多角度文本检测,这个算法叫做EAST. 一个文本检测算法被拆分成多个阶段没用,端到端才是正确之举,EAST的pipeline相当优雅,只分为FCN生成文本行参数阶段和局部感知NMS阶段. 总结,Seg-link稍微了看了一下,east没怎么看,只是大概知道干嘛的就成,主要是,我不需要大小检测,角度检测,CTPN对我来说就足够了。
4.CRNN
上面讲啥了?讲的是怎么找到字块,也就是把包含字的块从图像里面找出来。然后,你就得到一堆堆包含字的小块,然后呢?然后您就想个办法,把块里面的字识别出来吧。对!这就是OCR了。
好吧,男2号:CRNN上场。顺道吐槽一下,CRNN,RCNN,靠,真像啊,还都偏偏出现在文字识别领域,开始的时候,真让人崩溃。
奇怪的废话少说,学霸控先回娘家,论文,当然e文不好的又想充学霸的,可以看这个论文中文版。
CRNN结构
CRNN的网络架构由三部分组成,包括卷积层,循环层和转录层:
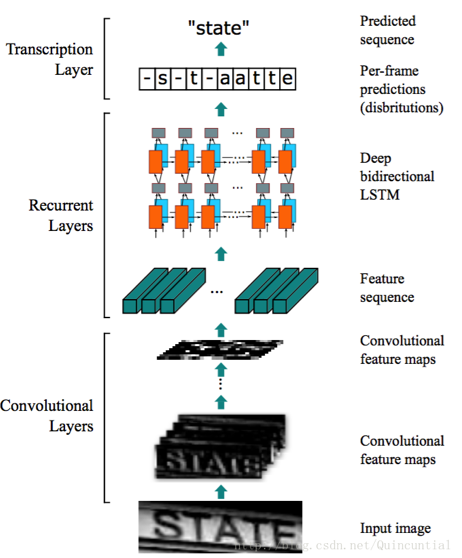
一图胜千言,CRNN就是三层:
-
1) 卷积层CNN,从输入图像中提取特征序列;
在进入网络之前,所有的图像需要缩放到相同的高度。特征图的每列对应于原始图像的一个矩形区域(称为感受野),这些矩形区域与特征图上从左到右的相应列具有相同的顺序。特征序列中的每个向量关联一个感受野,并且可以被认为是该区域的图像描述符。
-
2) 循环层RNN,预测每一帧的标签分布;(一帧是一个字符么?)
RNN可以将误差差值反向传播到其输入,即卷积层,从而允许我们在统一的网络中共同训练循环层和卷积层。(原来是两个网络一起训练的呀!)两个LSTM,一个向前和一个向后组合到一个双向LSTM中。我们创建一个称为“Map-to-Sequence”的自定义网络层,作为卷积层和循环层之间的桥梁。
-
3) 转录层,将每一帧的预测变为最终的标签序列。
转录是根据每帧预测找到具有最高概率的标签序列。 存在两种转录模式,即无词典转录和基于词典的转录。 我们采用Graves等人[15]提出的联接时间分类(CTC)层中定义的条件概率。按照每帧预测y=y1,…,yTy=y1,…,yT对标签序列ll定义概率,并忽略ll中每个标签所在的位置。因此,当我们使用这种概率的负对数似然作为训练网络的目标函数时,我们只需要图像及其相应的标签序列,避免了标注单个字符位置的劳动。(讲人话:1是似然 2是不需要单个字符,一堆字符的似然概率作为目标函数)
上面是摘录的,下面是自己讲人话
先说CNN,输入图像,都给丫拍成32像素高,统一就是好,就是好,就是好(石国鹏的包袱),长度不限,3通道(RGB啊)。那输出呢?都统一成(1,25,512),1您就忽略吧,25是什么鬼?是给后续RNN作为输入序列的长度的(就是RNN有25个时间片输入),就是25,规定(乌龟的腚)甭管您输入图像多长,都25。然后512呢?是RNN输入的一个时间片的X的维度,512维?!yes,对!
然后,你丫就用512维度的X,输入25次(就是25个时间片)给LSTM了。那输出呢?我们都知道,RNN输出先是h,然后h做一个softmax,变成概率分布。恩,就是这样,每一个1/25输出一个字母的概率分布,如果是英文就是26个字母+空格,27个。如果是中文,那就是汉字分布喽,4000来个嘛,卧槽,好大的一个概率分布。
对于Recurrent Layers,如果使用常见的Softmax Loss,则每一列输出都需要对应一个字符元素。那么训练时候每张样本图片都需要标记出每个字符在图片中的位置,再通过CNN感受野对齐到Feature map的每一列获取该列输出对应的Label才能进行训练。在实际情况中,标记这种对齐样本非常困难,工作量非常大。另外,由于每张样本的字符数量不同,字体样式不同,字体大小不同,导致每列输出并不一定能与每个字符一一对应。当然这种问题同样存在于语音识别领域。例如有人说话快,有人说话慢,那么如何进行语音帧对齐,是一直以来困扰语音识别的巨大难题。
讲人话:一般RNN都是输出是某个汉字的概率,可是从图像到汉字的对齐不好对齐啊,标注也不好标注啊,有的宽有的窄啊,那咋办?有个叫CTC的方法,丫直接预测一嘟噜串。就用它!
对于Recurrent Layers,如果使用常见的Softmax Loss,则每一列输出都需要对应一个字符元素。那么训练时候每张样本图片都需要标记出每个字符在图片中的位置,再通过CNN感受野对齐到Featuremap的每一列获取该列输出对应的Label才能进行训练。
在实际情况中,标记这种对齐样本非常困难,工作量非常大。另外,由于每张样本的字符数量不同,字体样式不同,字体大小不同,导致每列输出并不一定能与每个字符一一对应。
当然这种问题同样存在于语音识别领域。例如有人说话快,有人说话慢,那么如何进行语音帧对齐,是一直以来困扰语音识别的巨大难题。
解决办法就是CTC,这玩意本来是语音识别里面用来解决对齐的一个算法,被舶来用在了这里。
CTC
我以为,CTC才是CRNN的核心,飞机里的战斗机,也是最不好理解的一部分,来,咱们好好说说:
先上论文,其实我英文读起来也不顺畅,但是,硬着头皮读论文的好处就是不会有歧义,前因后果交代的很清楚,毕竟是严格审稿过的,特别是经典论文。看中文的一些资料,常直接粗暴告诉结论,断片儿的感觉,而且,一个无意的错误,可能还会让你迷惑半天。
两篇讲CTC的:号称吴恩达学生,写的很细,很多细节帮助理解CTC: 上,下
在CRNN里面使用CTC,还是这篇讲的最好,还有一篇纯讲CTC的,还有CSDN这篇,讲的很好。
说说我的理解:
就是LSTM算出来的字(words)的分布后,你要想寻找那些似然概率最大的组合,你的序列是30个,但是字母可能就5个,那么需要B变换,找到所有的可能的排列组合,使得他们出现的概率的和最大,通过这个最大化,可以学习出来LSTM的参数来。学习过程太复杂,所以借助前向和后向算法。得到这个LSTM模型后,在推测的时候,还要使用bean search方法来减少推断的计算量。
先说个B变换,
B变换
就是,一个字符串state5个字符,如果是由一个12长度的序列组成,所有可能的排列组合:
$B(\pi_1)=B(–stta-t—e)=state$
$B(\pi_2)=B(sst-aaa-tee-)=state$
$B(\pi_3)=B(–sttaa-tee-)=state$
$B(\pi_4)=B(stt-aa-t—e)=state$
…..
算似然概率
然后,说说$l$,也就是”state”,这个串出现的概率为:
$p(l|x)=\sum_{\pi}p(\pi|x)$ , 其中$\pi\in B^{-1}(l)$
- $x$就是我们输入的图像的LSTM变换后的向量
- $B^{-1}(l)$就是上面提到的所有的$\pi$的集合。
对某一个$\pi$,类似于”–sttaa-tee-“,他的概率咋算?
$p(\pi|x)=\prod_{t=1}^T y_{\pi_t}^t$ , 其中$\forall \pi \in L’^{T}$
- T是序列的长度,也就是LSTM输出的序列长度,就如同上面例子中的12.
- $y_{\pi_t}^t$,条件独立,把每个字母输出的概率相乘,比如”–sttaa-tee-“中的p(“-“),p(“-“),p(“s”),….
我呀,想要干嘛?
我想要$p(l|x)$最大啊,他是各个$p(\pi|x)$的和,对吧。然后,x可是由LSTM的参数$w$计算得到的,所以,我就可以计算梯度,梯度上升,从而可以得到LSTM的参数啦。对吧?
可是当T很大的时候,$\pi$的排列组合就可能非常多了,这个计算量可就大了去了。
咋办?
前向算法
用前向算法,对,就是HMM中的前向算法。回忆一下,前向算法,就是用来算一个给定转移矩阵、初始概率前提下,出现可观察序列的概率,即$P(O|\lambda)$。我们用它来算概率,定义一个前向概率,一个后向概率。
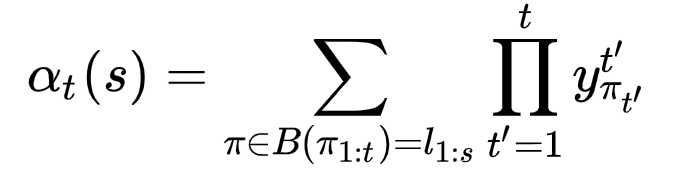
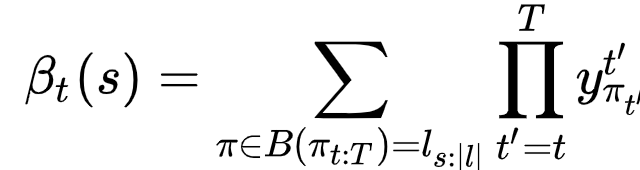
然后,整个$p(l|x)$就可以写成:
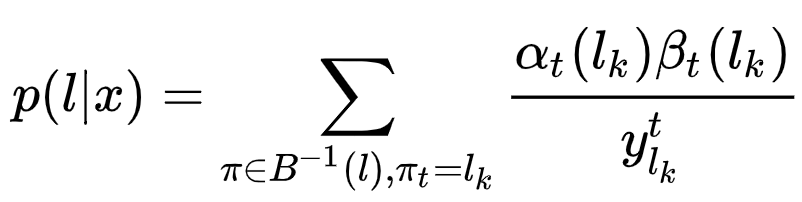
中间推导,确实没搞太清楚,太过烧脑,放弃,感兴趣自己的自己去憋:参考。
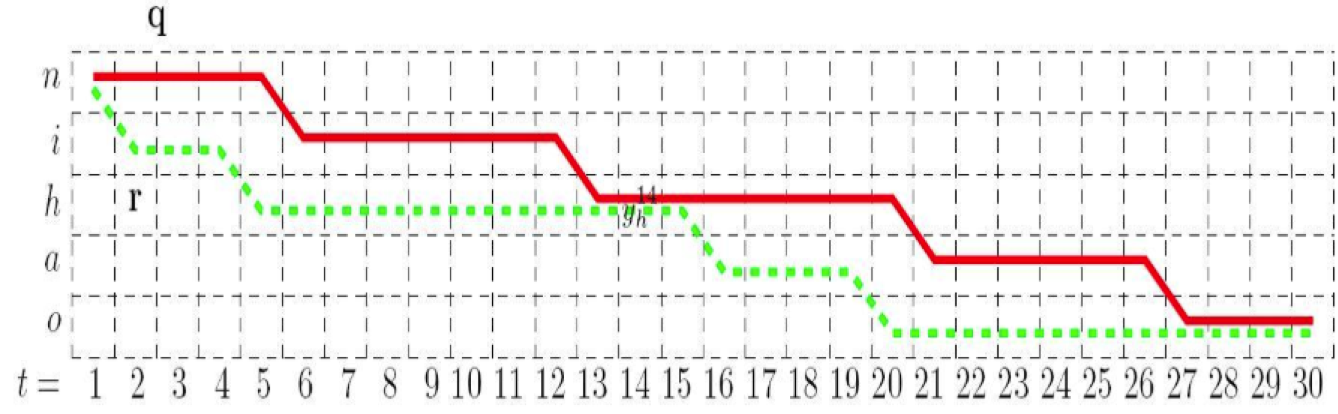
这图啥意思,列是时间,30个音节把,可以理解成;行是对应的要识别的字符,其实还有字表的其他的字符,只不过,和这个标签”nihao”,都不相关,所以都给删掉了。 你想啊,你识别,肯定是按照这个顺序走的,先识别n,可能这个n还拉长,你就持续5个(红色那个t=1..5),或者直接就切换到i去了,t=2的时候(绿色那个,t=2),对吧。
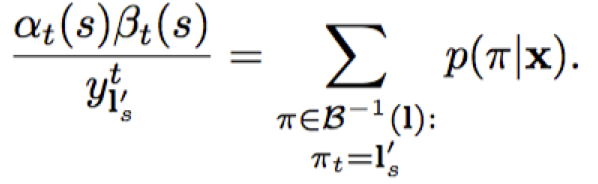
这个是说,在某个时刻t,对应到某个$l_s^{‘}$,就代表穿过$l_s^{‘}$的对应的$\pi$的概率。都加到一起,也就是$\sum$一下,所有的这样的在t时刻穿过$l_s^{‘}$的$\pi$的概率,你可能要是说了,t时刻,还有穿过别的字母的$\pi$呢呀,你怎么只谈这个$l_s^{‘}$?别急,下面就是谈:
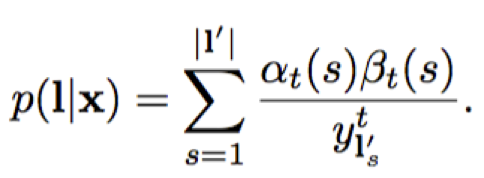
接着上面的,t时刻,对,你没看错,用t时刻的$\alpha_t(s) \beta_t(s)$,怎么就得到了整个概率$p(l|x)$了呢??! 别忘了,$\alpha_t(s)$,是$y_1*y_2*y_3…y_t$,而是$y_{t+1},y_{t+2},…y_T$,所以人家凑到一起,就是对穿过s的一个整个的的概率嘛。
这个最重要,我就是要这个玩意,我要这玩意最大化啊,似然概率最大化呀!
然后,我才可以反向求导,对$p(l|x)$进行求导,找出那一堆的LSTM的w参数中,使我$p(l|x)$最大的参数呀。到此,你才恍然大悟吧,LSTM做Seq2Seq是靠分类的结果和你标签的差异,从而得到交叉熵,然后让这个交叉熵最小。我们可不是这么玩的!我们是求你算呀算,算出一个每个时间片的对词的概率分布,然后这个概率分布下,你得到最后的“helo”的概率最大。恩,似然概率最大的!
对,这个就是CTC最核心的本质。
那你问了又?干嘛要扯一个前向算法出来呀?
问得好!
因为,这个似然感觉不好算啊,你可以想想: 在T=30,音素为[n,i,h,a,o]的情况下,共有C529≈120000条路径可以被压缩为[n,i,h,a,o]。 路径数目的计算公式为C音素个数T−1,量级大约为(T−1)音素个数。一段30秒包含50个汉字的语音,其可能的路径数目可以高达108,显然这么大的路径数目是无法直接计算的。因此CTC方法中借用了HMM中的向前向后算法来计算。
所以,就想办法用前向和后向来搞。
我们搞前向和后向的目的是啥,就是为了凑出上面那个式子,恩,为了你理解,我再拷贝一遍:
然后,你对这个式子进行求导,求导对象是谁呢?是$y_k^t$。
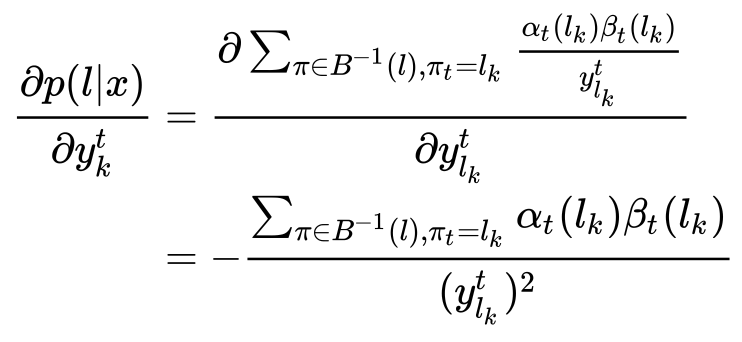
你眼尖,可能看出来,这个里面有个上标t,$y_{l_k}^t$!对吧,总是觉得别扭,因为t表示在某个时间片,可是你要算的是整个$p(l|x)$,有个t算几个意思?
其实你多虑了,因为每一个时刻t,LSTM会算出来一个概率分布,是所有的字母的,LSTM跑完一遍后,1..T时刻的所有的概率出来后(LSTM算的),然后利用推算出所有的$\alpha$和$\beta$,然后每个时间t,都可以算出一个$p(l|x)$,我理解,都可以做一个反向梯度下降,使得当前t的似然概率最大化。我理解,一个LSTM结束后,可以做T个反向传播,来更新T次对参数的更新。
这图就是告诉我们咋个根据LSTM算出来的概率,把各个时间片中的$\alpha$给算出来,行是涉及到的几个字母,就是$l$,就是目标字符串。列是时间片,也就是时间T。
好,这个是训练,训练完了,我怎么用在这个模型呢?这就是Inference问题了:
Inference
这个是inference问题,推测哪个序列可能性最高: 这个网上最清楚的是吴恩达徒弟,2014年突破性语音识别成果“Deep Speech”的作者,他的解释: https://mp.weixin.qq.com/s/KaAQczEoESQ__nBaagKg7w 实际上是通过bean search方法来完成的。
“鉴于有限的计算,集束搜索并不能真正找到Y,但它至少能通过更多计算帮助我们更好地权衡路径性质,从而最大限度地接近最好的解。”他说了,这种方法也不一定是最优,只能说可以接近最优。
这种方法真心没理解,感兴趣的同学可以细细研究一下,我大致的理解就是,如果是连续的或者有空的那些序列,也要留着往下算,因为存在未来合并的可能性,然后最终合计一遍合并后一样的概率,大排序后,最大的一个就是我们要的序列$\pi$,最最后,$B(\pi)$得到最终合并序列。最终结果。
代码
很蛋疼的把能找到的代码都搜了一遍:
-
721个star,老外,2年前更,pytorch的,预训练模型:https://pan.baidu.com/s/1pLbeCND,没啥用,忽略
-
国人,很热心,star 162个,pyTorch的,4个月前更,https://blog.csdn.net/Sierkinhane/article/details/82857572博客,360万中文数据集:https://pan.baidu.com/s/1ufYbnZAZ1q0AlK7yZ08cvQ。
-
203个star,TF的,1年前更,“在VGG16模型的基础上,迁移训练0、90、180、270度的文字方向分类模型 ,训练图片100000张”模型可下载:https://pan.baidu.com/s/1nwEyxDZ
-
789个star,包含了文本检测CTPN和文本识:DenseNet + CTC,注意不是CRNN,8月前更,数据集:https://pan.baidu.com/s/1QkI7kjah8SPHwOQ40rS1Pw (密码:lu7m),364万张图片,生成自己的样本可参考SynthText_Chinese_version,TextRecognitionDataGenerator和text_renderer
结论:最后还是选择参考CRNN_Tensorflow,需要研读论文,并把其代码完全理解后,训练自己的模型,训练集使用360万那个,以及150万那个(不知道是不是同一个人写的),然后再看准确率。估计需要1周左右。
参考文档
https://blog.csdn.net/Sierkinhane/article/details/82857572
https://blog.csdn.net/u012135425/article/details/83375143
趟雷过程
忠实记录一下自己趟雷过程,过于真实,不忍直视
首先,搜到了一个哥们的帖子:https://blog.csdn.net/u013293750/article/details/73188934,他还搞了一个github项目(https://github.com/bear63/sceneReco),他的modelctpn文字检测模型,下载不了郁闷。然后,搜到有个哥们什么写了一个攻略:https://blog.csdn.net/u011956004/article/details/79073282,
不过,我都不太感冒,因为都是caffi的,我想搞个tensorflow的,毕竟这个才是主流:然后我就去谷歌了一把,突然搜到一个帖子说有tensorflow版本,
https://blog.csdn.net/weixin_41579863/article/details/79816830
“调研过文本定位的大多看过caffe版的https://github.com/tianzhi0549/CTPN,一直觉得这个效果比较好,偶然发现TensorFlow版本的ctpn,欣喜同时打算跑一跑,可以在这个基础上做迁移学习了。
https://github.com/eragonruan/text-detection-ctpn”
下来,跑,用的人家的model,
最关键的工资水单不行啊。
暂时,心里有点数了,好吧,现在开始搞CRNN。
看到了这篇:https://shimo.im/docs/oDFzLoOXmYsAypwR,讲的不错,也有代码,不过犹豫了一下,
谷歌了一下“crnn tensorflow”,发现了4个github,其中第一个最高,380 star,就他把。
CRNN也是很多版本,选中了这个:
https://github.com/MaybeShewill-CV/CRNN_Tensorflow.git
run.sh 测试一张图片:
python -m tools.demo_shadownet --image_path data/test_images/test_01.jpg --weights_path model/shadownet/shadownet_2017-10-17-11-47-46.ckpt-199999
报错:
NotFoundError (see above for traceback): Restoring from checkpoint failed. This is most likely due to a Variable name or other graph key that is missing from the checkpoint. Please ensure that you have not altered the graph expected based on the checkpoint. Original error:
Key shadow/batch_normalization/beta not found in checkpoint
[[node save/RestoreV2 (defined at /Users/piginzoo/workspace/opensource/CRNN_Tensorflow/tools/demo_shadownet.py:99) = RestoreV2[dtypes=[DT_FLOAT, DT_FLOAT, DT_FLOAT, DT_FLOAT, DT_FLOAT, ..., DT_FLOAT, DT_FLOAT, DT_FLOAT, DT_FLOAT, DT_FLOAT], _device="/job:localhost/replica:0/task:0/device:CPU:0"](_arg_save/Const_0_0, save/RestoreV2/tensor_names, save/RestoreV2/shape_and_slices)]]
啥毛病呢,感觉是模型文件和代码中的模型不一致。
去看他的issue,这个帖子讨论了:https://github.com/MaybeShewill-CV/CRNN_Tensorflow/issues/186
感觉是tf版本的问题,于是重新搞了一个tensorflow的环境:用virtualenv,结果还报错:
安装的时候就警告过:
“tensorflow 1.10.0 has requirement numpy<=1.14.5,>=1.13.3, but you'll have numpy 1.13.1 which is incompatible.”
运行run.sh报错:
RuntimeError: module compiled against API version 0xc but this version of numpy is 0xb
于是安装numpy==1.13.3,还是报错,如旧:
RuntimeError: module compiled against API version 0xc but this version of numpy is 0xb
ImportError: numpy.core.multiarray failed to import
ImportError: numpy.core.umath failed to import
ImportError: numpy.core.umath failed to import
2019-01-22 15:39:44.323473: F tensorflow/python/lib/core/bfloat16.cc:675] Check failed: PyBfloat16_Type.tp_base != nullptr
run.sh: line 1: 12910 Abort trap: 6 python -m tools.demo_shadownet --image_path data/test_images/test_01.jpg --weights_path model/shadownet/shadownet_2017-10-17-11-47-46.ckpt-199999
靠,又报错是numpy的问题,升级版本后,发现还之前的问题相同,放弃环境的搞法。
然后再去看issue,帖子后面还有个办法,就是用其他branch
这个帖子讨论了:https://github.com/MaybeShewill-CV/CRNN_Tensorflow/issues/186
一个老外建议,用branch“@wdsd641417025 If you want to use the trained model provided by the author (in folder model/shadownet) you need to use the code provided in branch revert-138-patch-2 that is in TF version 1.3”
于是checkout其他branch: git checkout revert-138-patch-2
好了,
对英文没问题,
但是中文图片全都识别成了英文,
后来才发现,他的char_dict只有500多个,根本不是中文的,只是英文的。
看了他的issue发现,果然是大家都是自己train中文的:https://github.com/MaybeShewill-CV/CRNN_Tensorflow/issues/64
不过在这里面发现了一个,这个哥们的
https://github.com/Sierkinhane/crnn_chinese_characters_rec,以及他的csdn博文:https://blog.csdn.net/Sierkinhane/article/details/82857572
他用的是pytorch,靠,可是不想研究那玩意啊,
不过人家给整了一个360万张的训练集:360万中文数据集:https://pan.baidu.com/s/1ufYbnZAZ1q0AlK7yZ08cvQ,标签:https://pan.baidu.com/s/1jfAKQVjD-SMJSffOwGhh8A 密码:u7bo,
不过,他也没给模型!靠!得自己train了。
5. 一些文章的心得
中间读了一些文章,把其中的文摘摘录出来,以备自己日后参考。
其实,没啥用,都是初期,不靠谱的时候,自己东看西看的一些摘录,写下来了,又不舍得删,就放这里了,客官要是闲的蛋疼,可以看看。
参考
https://mp.weixin.qq.com/s/ULVRX-FpPRtTugrTHrs4lw
https://zhuanlan.zhihu.com/p/38655369
https://zhuanlan.zhihu.com/p/34584411
https://cloud.tencent.com/developer/article/1030422
https://www.jishuwen.com/d/2JVF
http://www.mooc.ai/open/course/605
https://edu.csdn.net/course/play/10506
https://mp.weixin.qq.com/s/jvHwFfcvQQdZYpwK3I1DQg
其他:
https://github.com/YCG09/chinese_ocr
这两个不错:
https://mp.weixin.qq.com/s/Y7Xpe1DlhGR9XRB7GunGnA 这个综述写的很好
笔记1
https://mp.weixin.qq.com/s/jvHwFfcvQQdZYpwK3I1DQg
雷音(OCR技术),阿里云(证件、人脸识别技术),MTEE(实时决策引擎),PAI(模型训练、部署平台)。 很多传统方法可以实现特定模糊类型的检测,比如$\color{red}{Laplacian算子法}$,通过计算二阶微分,然后求方差,根据阈值可以确定图像是否模糊。
传统方法在特征提取及特征表现上存在局限性。
本文改进$\color{red}{MobileNetV2}$的网络结构,实现一种新的$\color{red}{模糊检测算法}$。模糊检测需要特别关注图像细节的差异,因此,先通过$\color{red}{随机切片及HSV颜色空间筛选}$的方法生成样本集合,然后基于OCR识别率指标划分正负样本。
原始MobileNetV2网络包含十七层Bottleneck,模型层数较深,并且每层还进行扩展,在实际训练中,不易收敛且模型较大。通过对原始网络进行裁剪和改进,新的结构仅包含两层卷积、两层池化、两层Bottleneck以及一层全连接,网络更浅更窄,模型参数更少。该模糊检测算法的准确率约93.4%,模型原始大小约2M,而使用原始MobileNetV2训练的模型大小约26M。
传统方法可以解决特定的简单的形变问题,比如对于简单的旋转形变,可以通过Hough Transform先检测直线,然后通过旋转角度进行复原。
基于深度学习的方法,如$\color{red}{FCN,STN,Unet}$等,也被尝试用来处理形变问题。本文结合深度学习语义分割领域的相关知识,针对已有方法的不足设计优化方案,提出一种新的形变复原算法。
本文基于$\color{red}{Dilated Convolution}$优化网络结构,并且通过调整损失函数、$\color{red}{平滑预测值等方法,提出一种新的形变复原算法,提升模型的效果。本文采用$\color{red}{MS-SSIM}$作为算法复原效果的评价指标。
存在至少一成的词识别错误,由于没有$\color{red}{针对领域进行优化和分词}$,无法直接阅读和无人化使用,将识别结果进行领域相关的纠错分词,势在必行。
通过数据合成(根据概率转移矩阵,对字符进行增、删、改等编辑操作),以及迁移优化,训练得到满足目标要 求的模型。目前,图片质量较好时,OCR识别结果与$\color{red}{Ground Truth}$的差错率(编辑距离)为15.91%(若忽略空格:2.91%);经过本文的纠错分词模型,差错率降到2.24%,词准确率提升到93.56%。
笔记2
https://zhuanlan.zhihu.com/p/38655369
最近流行的技术解决方案中,是用一个多目标网络直接训练出一个$\color{red}{端到端}$的模型。在训练阶段,该模型的输入是 训练图像及图中文本坐标、文本内容,模型优化目标是输出端$\color{red}{边框坐标预测误差与文本内容预测误差的加权和}$。在服务实施阶段,原始图片流过该模型直接输出预测文本信息。
模型基础:起源于图像分类、检测、语义分割等视觉处理任务的各个$\color{red}{基础网络(backbone network)}$。同时,起源于物体检测、语义分割任务的多个网络框架,也被改造后用于$\color{red}{提升}$图文识别任务中的准确率和执行速度。
1.基础网络:
图文识别任务中充当特征提取模块的基础网络,可以来源于$\color{red}{通用}$场景的图像分类模型。例如,VGGNet,ResNet、InceptionNet、DenseNet、Inside-Outside Net、Se-Net等。也可以来源于特定场景的$\color{red}{专用}$网络模型。例如,擅长提取图像细节特征的FCN网络,擅长做图形矫正的STN网络。
FCN网络
全卷积网络(FCN,fully convolutional network), 是$\color{red}{去除了全连接(fc)层}$的基础网络,最初是用于实现$\color{red}{语义分割}$任务。 FC的优势在于利用反卷积(deconvolution)、上池化(unpooling)等上采样(upsampling)操作,将$\color{red}{特征矩阵}$恢复到$\color{red}{接近原图尺寸,然后对$\color{red}{每一个}$位置上的$\color{red}{像素}$做$\color{red}{类别预测}$,从而能识别出更清晰的$\color{red}{物体边界}$。
基于FCN的检测网络,$\color{red}{不再}$经过候选区域$\color{red}{回归}$出物体边框, 而是根据高分辨率的特征图$\color{red}{直接预测物体边框}$。因为不需要像Faster-RCNN那样在训练前定义好候选框长宽比例,FCN在预测$\color{red}{不规则物体边界}$时更加鲁棒。
由于FCN网络最后一层特征图的像素分辨率较高,而图文识别任务中需要依赖清晰的文字笔画来区分不同字符(特别是汉字),所以FCN网络很适合用来$\color{red}{提取文本特征}$。当FCN被用于图文识别任务时,最后一层特征图中每个像素将被分成文字行($\color{red}{前景}$)和非文字行($\color{red}{背景}$)两个类别。
STN网络
空间变换网络(STN,Spatial Transformer Networks)的作用是对输入特征图进行$\color{red}{空间位置矫正}$得到输出$\color{red}{特征图}$,这个矫正过程是可以进行$\color{red}{梯度传导}$的,从而能够支持端到端的模型训练。
2.检测网络框架
Faster RCNN
作为一个检测网络框架,其目标是寻找紧凑包围被检测$\color{red}{对象的边框}$(BBOX,Bounding Box)。
它在Fast RCNN检测框架基础上引入$\color{red}{区域建议网络}$(RPN,Region Proposal Network),来快速产生与目标物体长宽比例接近的多个候选区域参考框(anchor);
它通过ROI(Region of Interest) Pooling层为多种尺寸参考框产生出归一化固定尺寸的$\color{red}{区域特征}$;
它利用共享的CNN卷积网络同时向上述RPN网络和ROI Pooling层输入特征映射(Feature Maps),从而减少卷积层参数量和计算量。训练过程中使用到了多目标损失函数,包括RPN网络、ROI Pooling层的边框分类loss和坐标回归loss。通过这些loss的梯度反向传播,能够调节候选框的坐标、并增大它与标注对象边框的重叠度/交并比(IOU,Intersection over Union)。RPN网格生成的候选框初始值有固定位置以及长宽比例。如果候选框初始长宽比例设置得与图像中物体形状差别很大,就很难通过回归找到一个紧凑包围它的边框。
SSD(Single Shot MultiBox Detector)
是2016年提出的一种$\color{red}{全卷积目标检测算法}$,截止到目前仍是$\color{red}{主要的目标检测框架}$之一,相比Faster RCNN有着明显的$\color{red}{速度}$优势。
SSD是一种$\color{red}{one stage算法}$,$\color{red}{直接预测}$被检测对象的$\color{red}{边框和得分}$。检测过程中,SSD算法利用多尺度思想进行检测,在不同尺度的特征图(feature maps)上产生与目标物体长宽比例接近的多个默认框(Default boxes),进行回归与分类。
3.文本检测模型
文本检测模型的目标是从图片中尽可能准确地找出文字所在区域。 视觉领域常规物体检测方法(SSD, YOLO, Faster-RCNN等)直接套用于文字检测任务效果并不理想,原因是:
- 相比于常规物体,文字行长度、长宽比例变化范围很大。
- 文本行是有方向性的。常规物体边框BBox的四元组描述方式信息量不充足。
- 自然场景中某些物体局部图像与字母形状相似,如果不参考图像全局信息将有误报。
- 有些艺术字体使用了弯曲的文本行,而手写字体变化模式也很多。
- 由于丰富的背景图像干扰,手工设计特征在自然场景文本识别任务中不够鲁棒。
近年来出现了各种基于深度学习的技术解决方案。它们从特征提取、区域建议网络(RPN)、多目标协同训练、Loss改进、非极大值抑制(NMS)、半监督学习等角度对常规物体检测方法进行改造,极大提升了自然场景图像中文本检测的准确率。
- CTPN方案中,用BLSTM模块提取字符所在图像上下文特征,以提高文本块识别精度。
- RRPN等方案中,文本框标注采用BBOX +方向角度值的形式,模型中产生出可旋转的文字区域候选框,并在边框回归计算过程中找到待测文本行的倾斜角度。
- DMPNet等方案中,使用四边形(非矩形)标注文本框,来更紧凑的包围文本区域。
- SegLink 将单词切割为更易检测的小文字块,再预测邻近连接将小文字块连成词。
- TextBoxes等方案中,调整了文字区域参考框的长宽比例,并将特征层卷积核调整为长方形,从而更适合检测出细长型的文本行。
- FTSN方案中,作者使用Mask-NMS代替传统BBOX的NMS算法来过滤候选框。
- WordSup方案中,采用半监督学习策略,用单词级标注数据来训练字符级文本检测模型。
CTPN模型
CTPN是目前$\color{red}{流传最广、影响最大}$的开源文本检测模型,可以检测$\color{red}{水平或微斜}$的文本行。文本行可以被看成一个$\color{red}{字符sequence}$,而不是一般物体检测中$\color{red}{单个独立}$的目标。同一文本行上各个字符图像间可以互为$\color{red}{上下文}$,在训练阶段让$\color{red}{检测}$模型学习图像中蕴含的这种$\color{red}{上下文统计规律}$,可以使得预测阶段有效提升文本块预测准确率。CTPN模型的图像预测流程中,前端使用当时流行的VGG16做基础网络来提取各字符的$\color{red}{局部图像特征}$,中间使用$\color{red}{BLSTM层}$提取$\color{red}{字符序列上下文特征}$,然后通过FC全连接层,末端经过预测分支输出各个$\color{red}{文字块的坐标值}$和$\color{red}{分类结果概率值}$。在数据后处理阶段,将合并相邻的小文字块为文本行。
RRPN模型
基于旋转区域候选网络(RRPN, Rotation Region Proposal Networks)的方案,将$\color{red}{旋转因素}$并入经典区域候选网络(如Faster RCNN)。这种方案中,一个文本区域的ground truth被表示为具有5元组(x,y,h,w,$\color{red}{θ}$)的旋转边框, 坐标(x,y)表示边框的几何中心, 高度h设定为边框的短边,宽度w为长边,方向是长边的方向。训练时,首先生成含有文本方向角的倾斜候选框,然后在边框回归过程中学习文本方向角。
FTSN模型
FTSN(Fused Text Segmentation Networks)模型使用$\color{red}{分割网络}$支持倾斜文本检测。它使用$\color{red}{Resnet-101}$做基础网络,使用了多尺度融合的特征图。标注数据包括文本实例的像素掩码和边框,使用像素预测与边框检测多目标联合训练。
DMPNet模型
DMPNet(Deep Matching Prior Network)中,使用四边形($\color{red}{非矩形}$)来更紧凑地标注文本区域边界,其训练出的模型对$\color{red}{倾斜文本块}$检测效果更好。
EAST模型
EAST(Efficient and Accuracy Scene Text detection pipeline)模型中,首先使用$\color{red}{全卷积网络}$(FCN)生成多尺度融合的特征图,然后在此基础上直接进行$\color{red}{像素级的文本块}$预测。该模型中,支持旋转矩形框、任意四边形两种文本区域标注形式。对应于四边形标注,模型执行时会对特征图中每个像素预测其到四个顶点的坐标差值。对应于旋转矩形框标注,模型执行时会对特征图中每个像素预测其到矩形框四边的距离、以及矩形框的方向角。
该模型检测英文单词效果较好、检测中文长文本行效果欠佳,不过,省略了其他模型中常见的区域建议、单词分割、子块合并等步骤,因此该模型的执行速度很快。
SegLink模型 SegLink模型的标注数据中,先将每个单词切割为更易检测的有方向的小文字块(segment),然后用$\color{red}{邻近连接}$(link )将各个小文字块连接成单词。这种方案方便于识别长度变化范围很大的、带方向的单词和文本行,它不会象Faster-RCNN等方案因为候选框长宽比例原因检测不出长文本行。相比于CTPN等文本检测模型,SegLink的图片处理速度快很多。
PixelLink模型
自然场景图像中一组文字块经常紧挨在一起,通过语义分割方法很难将它们识别开来,所以PixelLink模型尝试用$\color{red}{实例分割}$方法解决这个问题。该模型的特征提取部分,为$\color{red}{VGG16基础上构建的$\color{red}{FCN网络}$。模型执行流程如下图所示。首先,借助于CNN 模块执行两个像素级预测:一个$\color{red}{文本二分类}$预测,一个$\color{red}{链接二分类}$预测。接着,用正链接去连接邻居正文本像素,得到$\color{red}{文字块实例分割}$结果。然后,由分割结果直接就获得文字块边框, 而且允许生成倾斜边框。上述过程中,省掉了其他模型中常见的边框回归步骤,因此训练收敛速度更快些。训练阶段,使用了平衡策略,使得每个文字块在总LOSS中的权值相同。训练过程中,通过预处理增加了各种方向角度的文字块实例。
Textboxes/Textboxes++模型
Textboxes是$\color{red}{基于SSD框架}$的图文检测模型,训练方式是$\color{red}{端到端}$的,运行速度也较快。如下图所示,为了适应文字行细长型的特点,候选框的长宽比增加了1,2,3,5,7,10这样初始值。为了适应文本行细长型特点,特征层也用长条形卷积核代替了其他模型中常见的正方形卷积核。为了防止漏检文本行,还在垂直方向增加了候选框数量。为了检测大小不同的字符块,在多个尺度的特征图上并行预测文本框, 然后对预测结果做NMS过滤。
Textboxes++是Textboxes的$\color{red}{升级版}$本,目的是增加对倾斜文本的支持。为此,将标注数据改为了$\color{red}{旋转矩形框和不规则四边形}$的格式;对候选框的长宽比例、特征图层卷积核的形状都作了相应调整。
4. 文本识别模型
文本识别模型的目标是从已$\color{red}{分割出的文字区域}$中$\color{red}{识别}$出$\color{red}{文本内容}$。
CRNN模型
CRNN(Convolutional Recurrent Neural Network)是目前较为流行的图文识别模型,可识别较长的文本序列。它包含CNN特征提取层和BLSTM序列特征提取层,能够进行端到端的联合训练。
它利用BLSTM和CTC部件学习字符图像中的上下文关系, 从而有效提升文本识别准确率,使得模型更加鲁棒。预测过程中,前端使用标准的CNN网络提取文本图像的特征,利用BLSTM将特征向量进行融合以提取字符序列的上下文特征,然后得到每列特征的概率分布,最后通过转录层(CTC rule)进行预测得到文本序列。
RARE模型
RARE(Robust text recognizer with Automatic Rectification)模型在识别变形的图像文本时效果很好。如下图所示,模型预测过程中,输入图像首先要被送到一个空间变换网络中做处理,矫正过的图像然后被送入序列识别网络中得到文本预测结果。
如下图所示,空间变换网络内部包含定位网络、网格生成器、采样器三个部件。经过训练后,它可以根据输入图像的特征图动态地产生空间变换网格,然后采样器根据变换网格核函数从原始图像中采样获得一个矩形的文本图像。RARE中支持一种称为TPS(thin-plate splines)的空间变换,从而能够比较准确地识别透视变换过的文本、以及弯曲的文本.
5. 端到端模型
端到端模型的目标是$\color{red}{一站式}$直接从图片中$\color{red}{定位和识别}$出所有文本内容来。
FOTS Rotation-Sensitive Regression
FOTS(Fast Oriented Text Spotting)是图像文本检测与识别同步训练、端到端可学习的网络模型。检测和识别任务共享卷积特征层,既节省了计算时间,也比两阶段训练方式学习到更多图像特征。引入了旋转感兴趣区域(RoIRotate),可以从卷积特征图中产生出定向的文本区域,从而支持倾斜文本的识别.
STN-OCR模型
STN-OCR是集成了了图文检测和识别功能的端到端可学习模型。在它的检测部分嵌入了一个空间变换网络(STN)来对原始输入图像进行仿射(affine)变换。利用这个空间变换网络,可以对检测到的多个文本块分别执行旋转、缩放和倾斜等图形矫正动作,从而在后续文本识别阶段得到更好的识别精度。在训练上STN-OCR属于半监督学习方法,只需要提供文本内容标注,而不要求文本定位信息。作者也提到,如果从头开始训练则网络收敛速度较慢,因此建议渐进地增加训练难度。STN-OCR已经开放了工程源代码和预训练模型。
6. 数据集
Chinese Text in the Wild(CTW)
该数据集包含32285张图像,1018402个中文字符(来自于腾讯街景), 包含平面文本,凸起文本,城市文本,农村文本,低亮度文本,远处文本,部分遮挡文本。图像大小2048*2048,数据集大小为31GB。以(8:1:1)的比例将数据集分为训练集(25887张图像,812872个汉字,测试集(3269张图像,103519个汉字),验证集(3129张图像,103519个汉字)。
文献链接:https://arxiv.org/pdf/1803.00085.pdf
数据集下载地址:https://ctwdataset.github.io/
Reading Chinese Text in the Wild(RCTW-17)
该数据集包含12263张图像,训练集8034张,测试集4229张,共11.4GB。大部分图像由手机相机拍摄,含有少量的屏幕截图,图像中包含中文文本与少量英文文本。图像分辨率大小不等。
下载地址http://mclab.eic.hust.edu.cn/icdar2017chinese/dataset.html
文献:http://arxiv.org/pdf/1708.09585v2
ICPR MWI 2018 挑战赛
大赛提供20000张图像作为数据集,其中50%作为训练集,50%作为测试集。主要由合成图像,产品描述,网络广告构成。该数据集数据量充分,中英文混合,涵盖数十种字体,字体大小不一,多种版式,背景复杂。文件大小为2GB。
Total-Text
该数据集共1555张图像,11459文本行,包含水平文本,倾斜文本,弯曲文本。文件大小441MB。大部分为英文文本,少量中文文本。训练集:1255张 测试集:300
下载地址:http://www.cs-chan.com/source/ICDAR2017/totaltext.zip
文献:http:// arxiv.org/pdf/1710.10400v
Google FSNS(谷歌街景文本数据集)
该数据集是从谷歌法国街景图片上获得的一百多万张街道名字标志,每一张包含同一街道标志牌的不同视角,图像大小为600*150,训练集1044868张,验证集16150张,测试集20404张。
下载地址:http://rrc.cvc.uab.es/?ch=6&com=downloads
文献:http:// arxiv.org/pdf/1702.03970v1
COCO-TEXT
该数据集,包括63686幅图像,173589个文本实例,包括手写版和打印版,清晰版和非清晰版。文件大小12.58GB,训练集:43686张,测试集:10000张,验证集:10000张
文献: http://arxiv.org/pdf/1601.07140v2
下载地址:https://vision.cornell.edu/se3/coco-text-2/
Synthetic Data for Text Localisation
在复杂背景下人工合成的自然场景文本数据。包含858750张图像,共7266866个单词实例,28971487个字符,文件大小为41GB。该合成算法,不需要人工标注就可知道文字的label信息和位置信息,可得到大量自然场景文本标注数据。
下载地址:http://www.robots.ox.ac.uk/~vgg/data/scenetext/
文献:http://www.robots.ox.ac.uk/~ankush/textloc.pdf
Code: https://github.com/ankush-me/SynthText 英文版
Code https://github.com/wang-tf/Chinese_OCR_synthetic_data 中文版
Synthetic Word Dataset
合成文本识别数据集,包含9百万张图像,涵盖了9万个英语单词。文件大小为10GB
下载地址:http://www.robots.ox.ac.uk/~vgg/data/text/
Caffe-ocr中文合成数据
数据利用中文语料库,通过字体、大小、灰度、模糊、透视、拉伸等变化随机生成,共360万张图片,图像分辨率为280x32,涵盖了汉字、标点、英文、数字共5990个字符。文件大小约为8.6GB
下载地址:https://pan.baidu.com/s/1dFda6R3
笔记3
https://zhuanlan.zhihu.com/p/34584411
在2013年之前,传统算法在OCR领域占主导地位,其标准流程包含文本检测、单字符分割、单字符识别、后处理等步骤。
传统方法中具有代表性的PhotoOCR[1]算法。PhotoOCR是谷歌公司提出的一套完整OCR识别系统,包含文字区域检测、文本行归并、过分割、基于Beam Search的分割区域的组合、基于HOG特征和全连接神经网络的单字符分类、基于ngram方法的识别结果校正。
基于CNN的识别算法,该方法由两部分构成,检测模块采用基于 region proposal 和滑动窗的方法切出词条,识别部分采用 7层CNN对整词分类。此方法另一大贡献是提供了大规模合成数据的方法。标注文字的成本远高于标注人脸、物体等数据,高标注成本限制了OCR数据集规模。因此,合成样本方法的出现,有效缓解了深度网络对于OCR真实标注数据的依赖,极大推动了OCR识别领域的深度算法的发展。CNN方法的出现,最大功能是在特征工程及单字符分类领域替代传统方法,但仍然未能避免传统思路中难度最大的二值化和字符分割问题。在复杂的自然场景、广告场景中,CNN分类方法仍难以满足需要。
腾讯DPPR团队场景文字识别技术
基于联结时序分类(Connectionist Temporal Classification, CTC)训练RNN的算法,在语音识别领域[4]显著超过传统语音识别算法。一些学者尝试把CTC损失函数借鉴到OCR识别中,CRNN [5]就是其中代表性算法。CRNN算法输入100*32归一化高度的词条图像,基于7层CNN提取特征图,把特征图按列切分(Map-to-Sequence),每一列的512维特征,输入到两层各256单元的双向LSTM进行分类。在训练过程中,通过CTC损失函数的指导,实现字符位置与类标的近似软对齐。
本团队也开始尝试把注意力机制引入到OCR识别模块。注意力机制能够聚焦词条图像特征向量的ROI,在当前时刻实现特征向量与原图字符区域的近似对齐,提升深度网络中的Encoder-Decoder模型的聚焦度与准确率。
笔记4
https://cloud.tencent.com/developer/article/1030422

印刷体识别的主要流程大致分为以下几个部分:图像预处理;版面处理;图像切分;特征提取、匹配及模型训练、匹配;识别后处理。
预处理
一般包括灰度化、二值化,倾斜检测与校正,行、字切分,平滑,规范化等等。灰度化处理的主要目的就是滤除这些信息,灰度化的实质其实就是将原本由三维描述的像素点,映射为一维描述的像素点。经过灰度处理的彩色图像还需经过二值化处理将文字与背景进一步分离开,二值化效果的好坏,会直接影响灰度文本图像的识别率。二值化方法大致可以分为局部阈值二值化和整体阈值二值化。目前使用较多的日本学者大津提出的“大津法”
倾斜校正
文本图像的倾斜检测方法有许多种,主要可以划分为以下$\color{red}{五类}$:基于投影图的方法,基于Houhg变换的方法,基于交叉相关性的方法,基于Fourier变换的方法和基于最近邻聚类方法。
最简单的基于投影图的方法是将文本图像沿不同方向进行投影。当投影方向和文字行方向一致时,文字行在投影图上的峰值最大,并且投影图存在明显的峰谷,此时的投影方向就是倾斜角度。
Huogh变换也是一种$\color{red}{最常用}$的倾斜检测方法,它是利用Hough变换的特性,将图像中的前景像素映射到极坐标空间,通过统计极坐标空间各点的累加值得到文档图像的倾斜角度。
Fourier变换的方法是利用页面倾角对应于使Fourier空间密度最大的方向角的特性,将文档图像的所有像素点进行Fourier变换。这种方法的计算量非常大,目前很少采用。
基于最近邻聚类方法,取文本图像的某个子区域中字符连通域的中心点作为特征点,利用基线上的点的连续性,计算出对应的文本行的方向角,从而得到整个页面的倾斜角。
规范化
为了消除文字点阵位置上的偏差,需要把整个文字点阵图移动到规定的位置上,这个过程被称为位置规范化。
常用的位置规范化操作有两种,一种是基于质心的位置规范化,另一种是基于文字外边框的位置规范化。基于文字外边框的位置规范化需要首先计算文字的外边框,并找出中心,然后把文字中心移动到指定的位置上来。基于质心的位置规范化方法抗干扰能力比基于文字外边框的位置规范化方法要强。
图像平滑
文本图像经过平滑处理之后,能够去掉笔划上的孤立白点和笔划外部的孤立黑点,以及笔划边缘的凹凸点,使得笔划边缘变得平滑。
版面分析
将文本图像分割为不同部分,并标定各部分属性,如:文本、图像、表格。目前在版面分析方面的工作核心思想都是基于连通域分析法,后衍生出的基于神经网络的版面分析法等也都是以连通域为基础进行的。
连通域是指将图像经过二值化后转为的二值矩阵中任选一个像素点,若包围其的所有像素点中存在相同像素值的像素点则视为两点连通,以此类推,这样的像素点构成的一个集合在图像中所在的区域即一个连通域。根据连通域大小或像素点分布等特征可以将连通域的属性标记出来,用作进一步处理的依据。
版面理解
获取文章逻辑结构,包括各区域的逻辑属性、文章的层次关系和阅读顺序。根据版面分析时记载的连通域位置信息,确定连通域归属序列。
图像切分 行(列)切分和字切分。经过切分处理后,才能方便对单个文字进行识别处理。
[行、列切分]
由于印刷体文字图像行列间距.、字间距大致相等,且几乎不存在粘连现象,所以可以采用投影法对图像进行切分,得到每列(行)在坐标轴的像素值投影曲线是一个不平滑的曲线,通过高斯平滑后的曲线在每个波谷位置间的区域即为要的一行(列)。
[字切分]
字切分对于不同的文种存在着比较明显的差异,通常意义下,字切分是指将整行或整列文字切分成独立的一个个文字,而实际上根据文种差异,可能还需需要将单个文字进行进一步切分。而因为文种不同,构词法或钩字法也有所不同,所以切分方法的难度差别也是天壤之别。例如将汉字“屋”切分开的难度和将英文“house”切分开的难度差别就很大,因此在识别模式上,也会根据文种特性,设计不同的识别方法。
特征提取及匹配
特征提取是从单个字符图像上提取统计特征或结构特征的过程。所提取的特征的稳定性及有效性,决定了识别的性能。对于统计特征的提取,可利用统计模式识别中的特征提取方法,而对结构特征的提取,应根据具体文字所确定的识别基元确定相应的特征提取方法。在相当长的文字识别的研究过程中,是利用人们的经验知识,指导文字特征的提取。例如边缘特征、变换特征、穿透特征、网格特征、特征点特征、方向线素特征等等。
特征匹配是从已有的特征库中找到与待识别文字相似度最高的文字的过程。当待识别文字提取完特征之后,不管使用的是统计特征,还是结构特征,都需要有一个特征库来进行比对,特征库中应包含欲识别字符集中所有文字的特征。特征匹配的方法有很多,比较常用的有:欧式空间的比对法、松弛比对法、动态程序比对法以及HMM(HiddneMarkovModel)法等等。在神经网络出现之前以及之后很长一段时间,在汉字OCR领域,一直采用的就是这种模板匹配的方法。