
#从RNN到LSTM,到Attention
概述
前言:看官看着可能会有点累,因为非常乱,恩,就是挺乱的,我主要的目的是给自己做个回忆笔记,我主要是在冲着自己嘚逼嘚逼呢,就是自己的一个自己冲自己的唠叨笔记,如果能帮上您,得嘞,就不用谢我了,要是觉得没啥用,就放开我,去网上寻找更多这类文章,有的写得确实不错,包你爽,我这里也都做了不少索引,可以顺着找找。
突然对RNN开启的这套时序预测学习感兴趣,之前听过,忘的差不多了,回过头来,想沿着把这些知识捋一捋,这么个线索:
RNN->LSTM->Attention->Tensorflow实践
李宏毅老师的课是讲的最好的https://www.bilibili.com/video/av13333557/, 第六课《6-Neural Network with Memory 》,可以直接跳过去看,之前的不感兴趣可以直接跳,不影响理解。顺道吐槽下,这些讲课的老师里面,李宏毅老师是最有意思的,还有让我印象深刻的是七月在线的
讲LSTM的https://www.jianshu.com/p/9dc9f41f0b29这片不错,貌似作者是个高产户,还翻译了一个开放文档《神经网络与深度学习》,可以关注下。不过,他翻译的也是2015的那篇经典的LSTM扫盲文http://colah.github.io/posts/2015-08-Understanding-LSTMs/。
还有这篇,讲的也非常好,必须mark一下 https://www.cnblogs.com/surfzjy/p/6715150.html https://zhuanlan.zhihu.com/p/28054589
突然脑洞开,感觉HMM和RNN结构上很像啊,都是处理序列的,于是百度一下,发现了这篇https://www.zhihu.com/question/57396443
马尔科夫网,那是无向图模型,概率图模型的两大类之一(另一大类是贝叶斯网,有向图模型)。HMM是一种特殊的马尔科夫网。神经网络可以看成特定的概率图模型。马尔科夫网和RNN根本不在一个概念层面上。
RNN经典论文,虽然还是看着费劲,先mark一下,放在这里,以便日后阅读: Recurrent neural network based language model RNN用在语言模型上的开山之作.
RNN
好吧,闲言碎语不要讲,赶紧表一表我们的RNN了。
DNN不是挺好的嘛,干嘛还要RNN呢?处理时序问题!
李宏毅老师讲的这个例子,通俗到发指,建议去听一下。这是一个类似于加法进位的例子,看!需要记忆之前的输入了,也就是进位。每次的进位都是一个需要被记住的数,这个数如果不记住,那么这个network就train不出来:
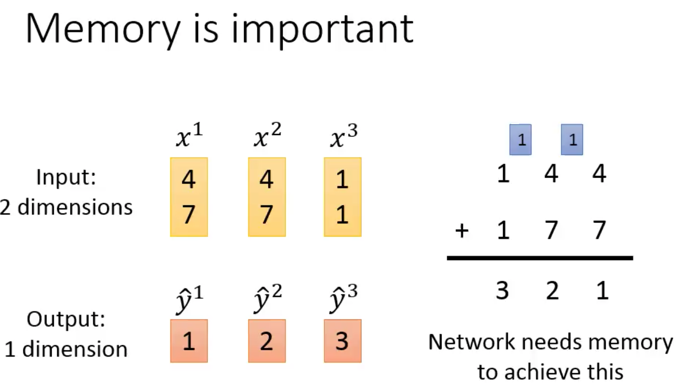
DNN会对数据进行shuffle,说白了,我有x1,x2,x3…xn个数据,你灌谁输入都行,我期待的y也是独立的,但是,RNN不是,x1,x2,x3…xn之间就必须按照一个顺序来,不能颠倒,这样你预测出来的y序列也是有顺序的。注意x1-xn都是向量。 以翻译为例子可能比较好理解,每个中文,对应每个英文,每个中文词,其实都是一个独立的数据,对应为$x_i$,他本身就是个向量,比如使用word2vec词向量,这一对的词向量,就需要按照顺序对应,然后才能输出对应的一个英文的词向量输出,也就是翻译结果。 RNN是一个句子都输入完才是一个整个输入,也就是说,书的多个数据,必须打包在一起,按照严格的顺序,一起灌入。 我过去曾经有错觉,以为整句话是一个输入数据呢,自己还意淫出一个“句向量”的概念。
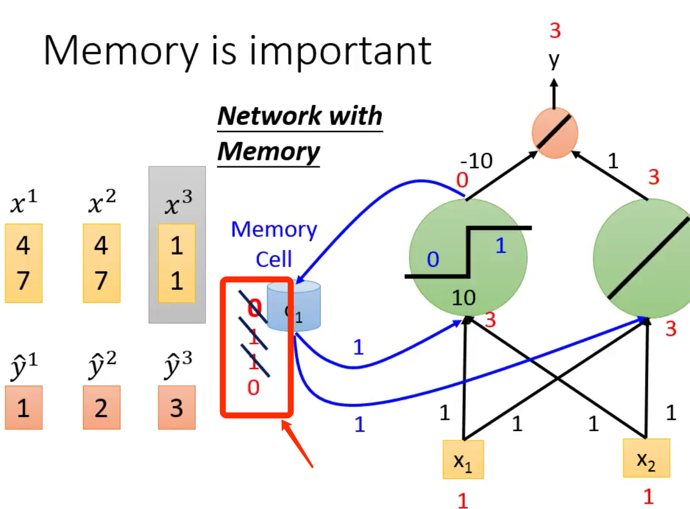
那中间存放的Memory Cell里面存什么?
- 是一个数,对应到多维就是一个向量
- 这个向量是变的,会被更新,之前的那个就被丢弃了
- 每次的y输出其实都要打包收集起来,最终这个y序列是最终的输出结果
RNN的memory就是个向量。对,是向量!我还以为这个memory多大呢?!原来就是个向量,大失所望啊,呵呵。那么这个向量多少维度呢?好问题。
上图,剖析一下一个RNN神经元内部的构造:
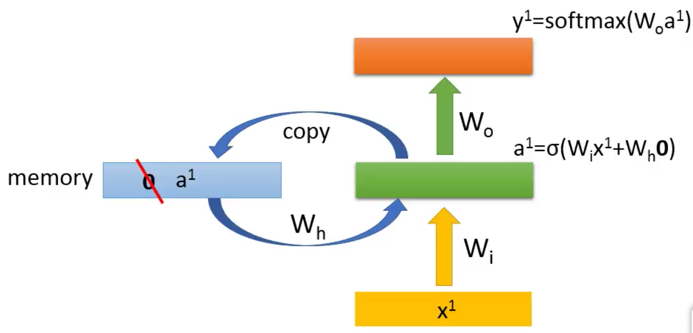
a1=$\sigma$(Wix+ Whm)
- Wi是一个隐藏层的权重矩阵,
- Wh是memory向量对应的权重矩阵,
- m是记忆向量
y1=$softmax$(Wo*a1)
- Wo是上一个$softmax$的权重矩阵
- a1要被copy到memory向量里面
灌入过程前向计算的过程,就是输入x1,x2,x3….xn,然后得到y1,y2,y3,…yn的过程, 其中Wh,Wi,Wo在这一次次输入训练中是不变的,但是memory是变的,每输入一个Xi,就会导致memory向量对应的改变,直到这个向量序列结束(说的就是x1—xn,向量序列),对应产生y1—yn的向量序列。
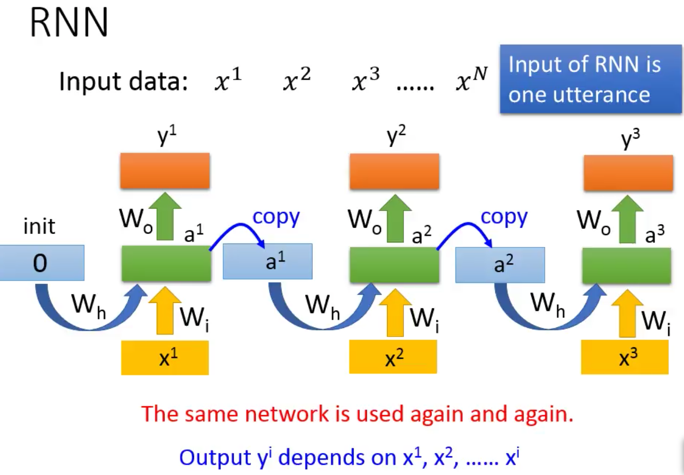
输出是概率,输出是概率,输出是概率,说三遍。 输出是经过softmax之后的分类别的概率。其实是说给自己听的,怕自己忘记。
[ 适用范围 ]
RNN都解决哪些类的问题呢?
- 比如N:N: 严格1对1,如POS词性标准、实体识别、信息提取
- 比如N:1,比如文章的情感识别,正面文章还是负面文章,就是1个判断结果
- 比如1:N,比如图片的看图说话,输入是一个图片的所有的像素组成的一个向量,输出是一堆的文字向量
- 比如M:N,如seq2seq,不再是经典RNN的每个字/词都要对着,而是M:N的关系,可多可少,不过没听懂他说何时断掉,因为他的那个例子“machine learning”-> “机器学习习惯好…”后面的序列可以一直产生下去呀(因为不是1对1嘛),李宏毅老师说,要给翻译结果一个中断符,不过怎么给,没听明白???
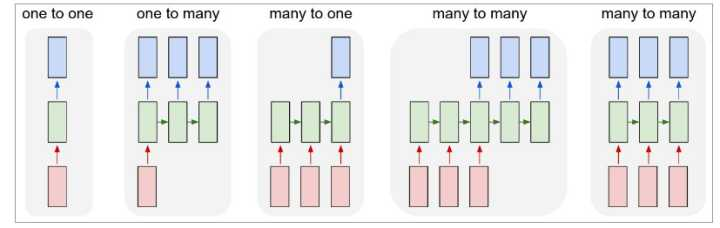
关于这个输出的1:N, M:N啥的映射,看这篇:https://zhuanlan.zhihu.com/p/28054589
[ 损失函数 ]
损失函数就是,对应的y-hat和y的cross entropy(交叉熵)。李宏毅老师讲课用的是均方误差,但是实际上生产中都用交叉熵。怎么个交叉熵法呢?[关于交叉熵,可以参考我的另一篇关于交叉熵的博文,说白了就是对比输出的y序列和你用RNN计算后的序列$\hat y$这两个分布的差异性,$y$序列和$\hat y$实际上可以被看做是两个分布,
这个是李宏毅老师的损失函数(均方误差)
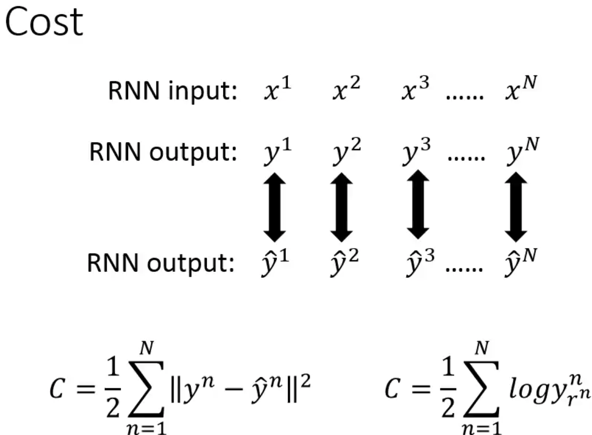
这个是交叉熵的损失函数
$L(y,\hat y) = \frac{1}{N} \sum_{n \in N} y_n log\hat y_n$
这个地方,有个坑,需要解释一下,这个是原始论文里面摘录出来的,最后输出的$\hat y$ 是通过一个softmax函数得到的,我们都知道,softmax是一个对多分类输出一个每个类别上概率分布的函数,为何要这么做呢?像李宏毅老师那样直接输出个线性的$\hat y$不好么?李宏毅老师那样写Cost function有问题么?脑中迸发出这一列问题。 自问自答一下,用softmax是因为,原始RNN论文是为了解决自然语言处理,在处理自然语言的时候,他每次输出的其实都是一个词表维度相同的N维概率向量,代表每个词可能是的概率。 比如翻译英文,我有样本数据(i love beijing tian an men->我爱北京天安门):
- 第一个时刻$t1$,输入为“i”,预期(也就是样本输出数据提供的)是“我”,RNN模型根据这个信息计算出$s_1$,不过RNN最后还要softmax跑出来输出了一个词表向量,可能会在“我”这个维度上值稍微大一些,当然也可以小。这样,这个标签数据和输出数据就产生了差,这个差未来就可以用作反向调整所有的权值。 (样本输出数据为“我”,对应概率向量就是在“我”这个词的维度上为1,其余都是0)
- 第二个时刻$t2$,这个时候输入是“love”,对于RNN来说,这个时候,输出的softmax就依赖于两个输入啦,一个是新输入的“love”,还有是上一个时刻的输出的中间量$s_1$,两者共同作用,才得到了$s_2$
(s是中间结果,做softmax之前,下面图有说明)
- 然后是第三个“北京”,依赖于输入的“beijing”和上一个状态输出值$s_2$

扯的有点多了,那么最终再来看RNN的交叉熵损失函数,就是把各个样本的词表概率和RNN输出概率做交叉熵,但是我们知道,样本输出概率是一个one-hot编码,也就是对应的输出词上是1,所以,$y_n log\hat y_n$ 就变成了$log\hat y_n$ ,$y_n$ 是1嘛。最终,损失函数简化为了:
$L(y,\hat y) = \frac{1}{N} \sum_{n \in N} log\hat y_n$
[ 训练过程&BPTT ]
该训练了,训练过程还是使用梯度下降。 RNN的训练有点小麻烦,那就是你得考虑之前的所有的状态。
RNN训练和DNN的BP不同的是,他的W要反复被更新,这个是因为某个$y_i$需要依赖于$a_i$,$a_i$又依赖于前面的$a_{i-1}$,就依赖于之前的$w_{i-1}$,….,然后递归向前。 w其实只有一份,所以每次更新的时候(就是每一层),都会更新这个w,这也是就是大家常说的,RNN的参数w是共享的。 举个例子,$y_3$是由$a_3$决定的,而$a_3$是由$x_3$和$a_2$一起决定的,而$a_2$是由$x_2$和$a_1$一起决定的,最后,$a_1$是由$x_1$决定的,这样,一个$y_3$的结果,实际上是由$x_1,x_2,x_3$一起决定的,感受到了吧。 这种不停往前倒腾的方法,就被起了个名字叫BPTT(back propagation through time)
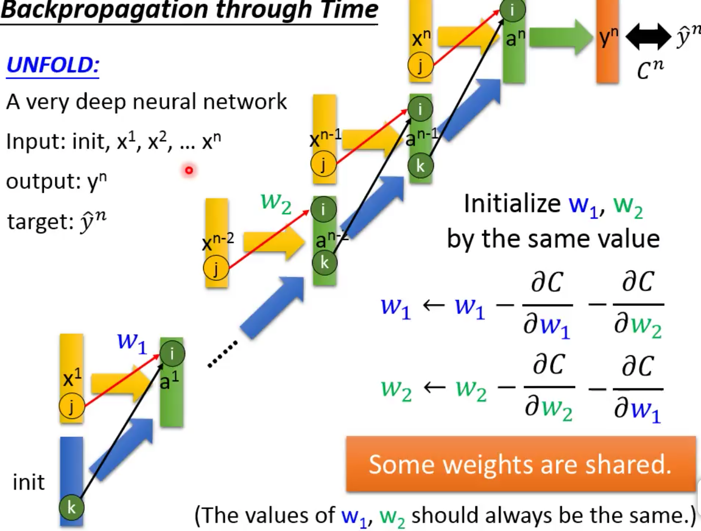
还有一点,可以直观感受到,越往前的$x_i$对当前的y输出影响越小,当前的x输入影响是最大的。 这块常常晕,感觉每次RNN里面的东西是变的,仿佛权值w也是变得似得,不是的。w在整个input数据序列过程中是不变的,变的是memory,这点不能晕。
BPTT
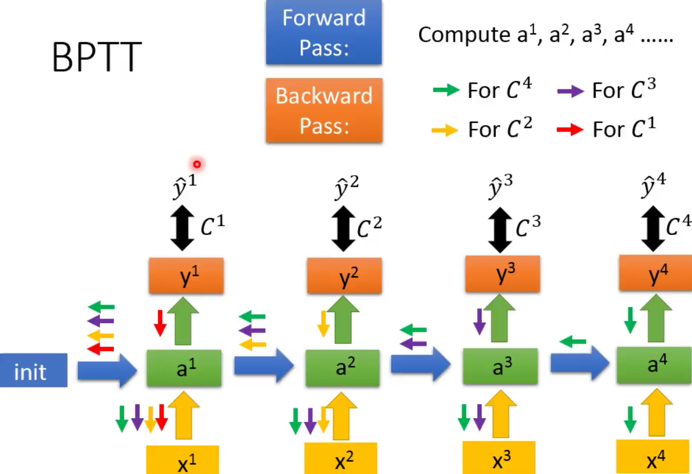
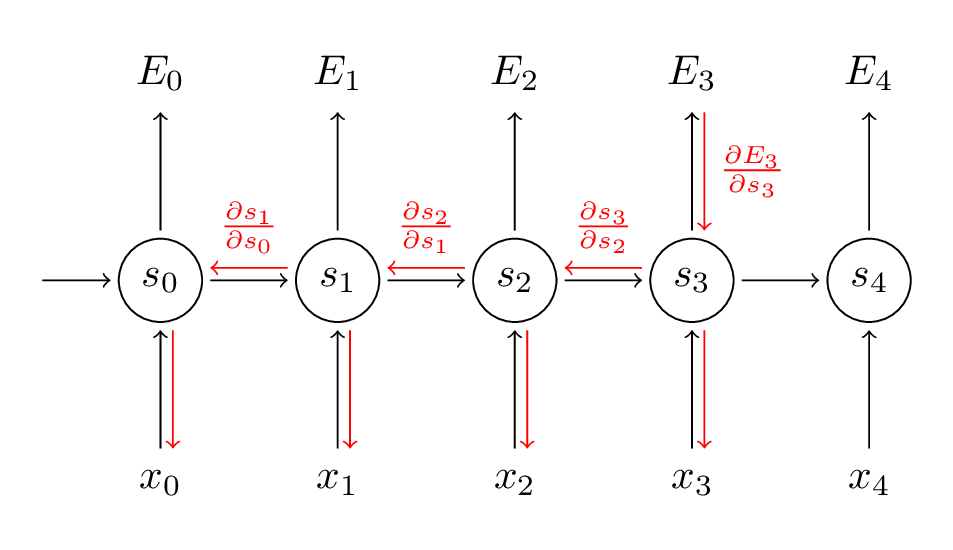
我们看看这个过程: 首先是损失函数,不用L了,用E来表示:$E_{t}(y,\hat y) = -\sum_t log(\hat{y_{t}})$ 然后对每一个w求偏导,然后得到偏导值 乘以 一个步长值,更新w,寻找极小值点。恩,还是之前那个套路。 但是,but,你把这个偏导求一求,展开一下就发现不是那么容易。 我们前面其实已经讨论过了,你求第t个的值,实际上是有1..t-1所有的输入和输出都要相关的,那么你要求这个t时刻的E的时候,就得循环把前面的都求出来。 比如:
$E_t= log(\hat y_t)$
$\hat y_t=softmax(s_t)$
$s_t=\sigma(a_t)$
$a_t = w_i x_t + w_h s_{t-1}$
说明:
- w_i是输入层的参数
- w_h是隐层参数,也就是和上一时刻的$s_{t-1}$相乘的参数
以$E_3$为例,链式法则,会让他一直倒腾到$s_0$,因为每个$s_t$都包含权值w: $\frac{\partial E_{3}}{\partial W}=\frac{\partial E_{3}}{\partial \hat{y_{3}}} \frac{\partial \hat{y_{3}}}{\partial s_{3}} \frac{\partial s_{3}}{\partial s_{2}} \frac{\partial s_{2}}{\partial s_{1}} \frac{\partial s_{1}}{\partial s_{0}} \frac{\partial s_{0}}{\partial W}$
而,整个损失函数求导,是 $E=\sum_{t} E_t$,恩,每个$E_t$计算完了,都加到一起。越往后的E,计算约复杂,约需要把前面的相关的都求导一遍。就是后面的都是前面的一个嵌套,越往后约复杂,所以训练数据越长,计算量越大。 形象写一下,就是 $E = E_0 + E_1(s_0)+ E_2(s_0,s_1)+ E_3(s_0,s_1,s_2)+ ….+ E_t(s0,…,s_{t-1})$ 没那么严谨啦,只是表示一下。
RNN的训练不好训练,狠困难,据说是“the error surface is rough”,就是他的cost函数不是平滑的凸函数,而是崎岖或者陡峭,不好训练。
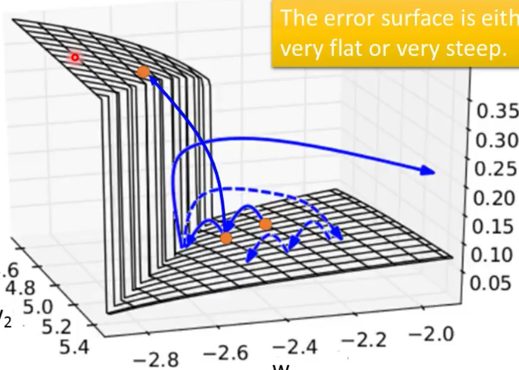
这么一个损失函数,有个很大问题,具体我也没去试验过,说是存在
RNN的Training没有特别好的方法,只能有一些最佳实践方法: NAG,RMSProp,没有详细关注,未来用到再说。
LSTM有效地解决了RNN的gradient vanish问题???
LSTM
LSTM要解决RNN的啥问题?
主要是为了解决长依赖问题,RNN可以解决对之前上下文的依赖,但是,只能离的比较近的上下文,对于离的比较远的上下文,他就无能为力了。LSTM通过一个变态的3门结构,可以将一些前文中的重要信息,一直保留到她们后面被需要的地方。
门上的信息通不通过,靠的是sigmoid函数,它的输出是0-1的概率值,它跟把锁一样,让信息是否通过。
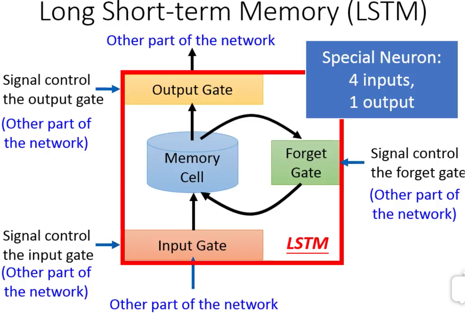
[ 三重门 ]
LSTM,3个gate(门)
- 一个管是不是改把上次的输出输入到memory cell里:
输入门 - 一个管是不是把memory cell的值吐给下一次序列:
输出门 - 一个管是不是把memory cell里面的记忆之清空:
忘记门
之前RNN提过,越往前的输入影响越弱,有了这3个门,我可以控制离我近的输入所产生的影响,比如我保留上上上次的输出,而选择忘记上次和上上次的输出,这样就可以让远处的输出保持比较强的影响力。
李宏毅老师为了简化,把3个门都简化了,而生产中的一般LSTM相对复杂一些,
李宏毅老师版本
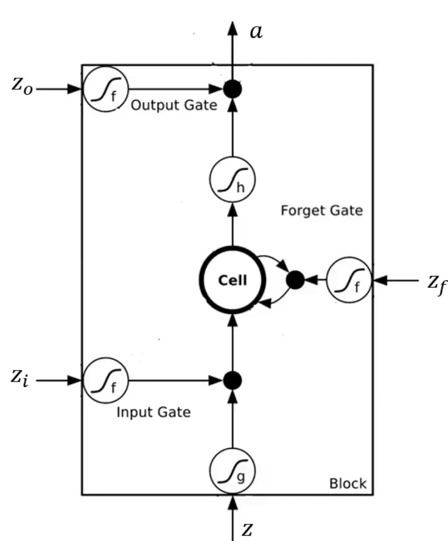 |
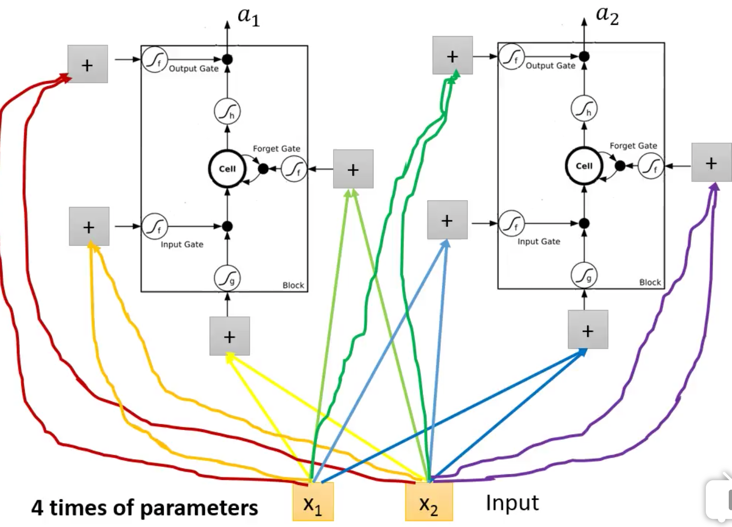 |
这个是一个神经元内部结构,以及和输入连接的关系。 可以看到,各个门的输入,就是实际的输入数据$x_1,x_2….$,但是他画的有一点不好,给人错觉,这个图感觉是并行输入的似的,但是其实$x_1,x_2….$其实是顺序输入的。 这里他画了两个神经元,也可以是多个,多个的话,每个$x_i$都会灌入给每一个LSTM神经元的每一个门的。
LSTM一般版本
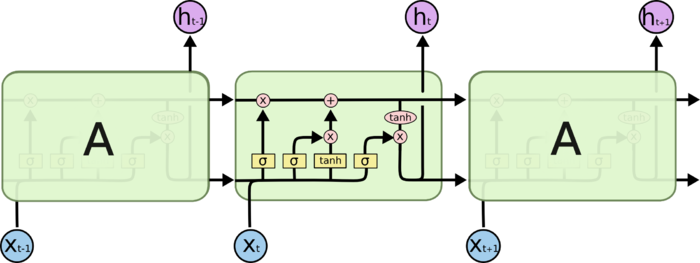 |
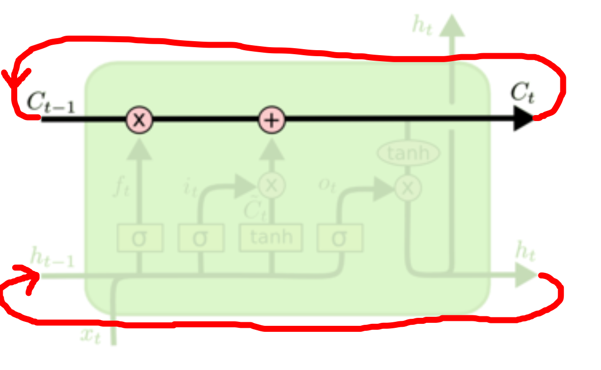 |
LSTM一般版本就复杂了一些,李宏毅老师提过,就是最终上图中的a,实际上在生产版本中,也会把上一层的输出$C_{t-1}, h_{t-1}$,合并到下一层的输入中,继续使用。啥叫合并,就是把输入$x_i$和$h_{t-1}$俩向量做一个并,变成更大维度的一个向量,灌入。
如上图所示。我觉得,上图第一个那个画的不好,感觉跟有3个神经元似得,其实不是,就一个,我下面用红线勾勒了一个我认为的样子,就是把这次得到的$C_t$接入到下一个的输入,$h_t$也是。
不过这里有个问题,你看宏毅老师的那个图,有个Cell的单元,缓存着这次的需要记住的Cell变量,但是LSTM这图里面,我没有看到,文章里也没提到缓存区的概念。因为$x_i$灌入的时候,是一个…吧嗒吧嗒…下一个,这样一个个按顺序输入的,要是没有缓存到某个地方,它怎么能顺利交接给下一个$x_{i+1}$进行运算呢。这个是问题,回头找明白人问问???
[ 4个步骤 ]
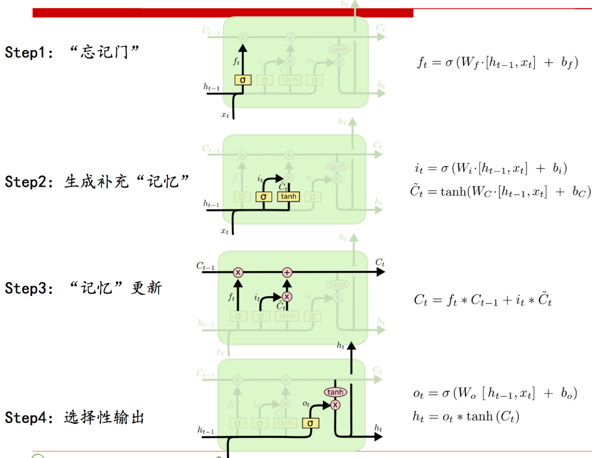
- Step1 忘记门,你看它输出是一个是否忘记的概率,越接近0,越偏向于忘记。这个门是由什么决定的,上一次的输出$h_t$和本次的输入$x_t$,注意注意,是上次的输出$h_t$,而不是上次的$C_t-1$,诡异吧,论文就是这么设计的,不知道为何(不是我说的,July寒老师这么评论的) [$h_{t-1},x_t$]是把两个向量做了拼接。 对了,忘记啥东西啊?这点忘说了。忘记的是,上一次的状态,是不是让上一次的状态就过来了,然后和这一次的状态一起做个线性组合,变成下一次的状态,喂给下下次。
- Step2 准备新的信息,和信息通过的概率 $\bar C_t$就是生成新的信息,为何用tanh函数,据寒老师说,是为了BPTT的时候不至于梯度爆炸,不解? $i_t$又是生成一个概率值,多大程度上接受这些新知识,所以,下一步就会看到 $\bar C_t$ * $i_t$ ,对了,这个式子很像忘记门啊,不过细看,不是一回事,对应的权值不一样,他是$W_f$,我是$W_i$,各玩各的,各为其主。
- Step3 得到最新的“记忆”内容,也就是$C_t$,他实际上是上一个$C_{t-1}$和刚才挑选出来的新信息$\bar C_t$,$C_{t-1}$乘以忘记概率$f_t$,$\bar C_{t}$乘以接受概率$i_t$,得到最终的本次要记忆下来的内容。 寒老师说,这个加法,可以避免RNN反向求导的时候,由于连乘导致的梯度消失的问题,不解?
- Step4 最后一步,输出的时候,再来一个概率判断$o_t$,才输出
LSTM变种很多,不过效果都大同小异。
接下来,老规矩:损失函数、如何训练
[ 损失函数 ]
[ 如何训练 ]
[ 一些变种 ]
一个序列训练完就做BPTT么?还是整个都完成一批,才做一次?
Attention
她们都是这么说的,过去的RNN、LSTM,都是把一个序列先灌给训练好的模型,我是说在预测过程中(不是训练),然后呢,等着这一个序列,比如8个英文单词,每个词向量都顺序灌入后,得到一个输出,这个输出了不得,了不得,据说隐藏着这个8个单词内的无穷信息,就是这么神奇,一个向量竟然藏着8个词的神魄,服了。然后用这个神魄,再交给网络,吐出后面的8个的词的翻译,这个翻译可能是4个汉字词组组成的。恩,这就完成了一个8英语单词—>4个汉字词语组成的翻译句子。 还是得看这篇https://zhuanlan.zhihu.com/p/28054589
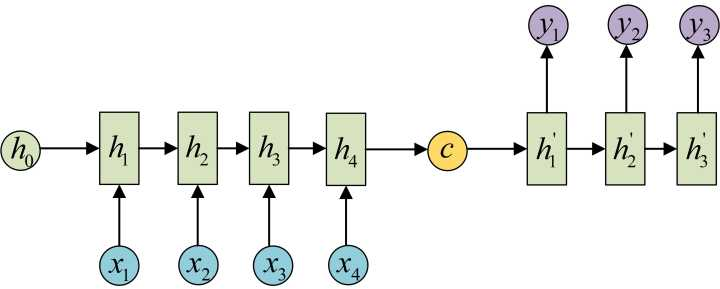
你知道吧,网上那些讲Attention的帖子,他们丫一讲LSTM,RNN不好的时候,就拿Seq2Seq的Encoder-Decoder模型说事,我也确实也不明白,也只好这么听着,将来我搞明白了更多的东西,再来反思她们说的对与否,留下这个文字给自己提醒。(其实RNN是N:N,严格对应,难道就没有M进行到一半或者1/3,就输出N的模型呢?不过也是哈,太随意这模型可怎么做呀?要么严格N:N,要么先把输入都灌进去-M,然后,一口气输出N,恩,也只有这么理解了)。
总之,就是,这个么个神魄,其实是敲错了,魂魄,妈蛋,懒得改了。就是上图中的黄色的$c$,她们觉得太压缩了,太浓缩了精华,不好,一定要在后期翻译的时候,也就是h1’,h2’,h3’,输出的时候,把原来的x1,x2,x3,x4都带着,
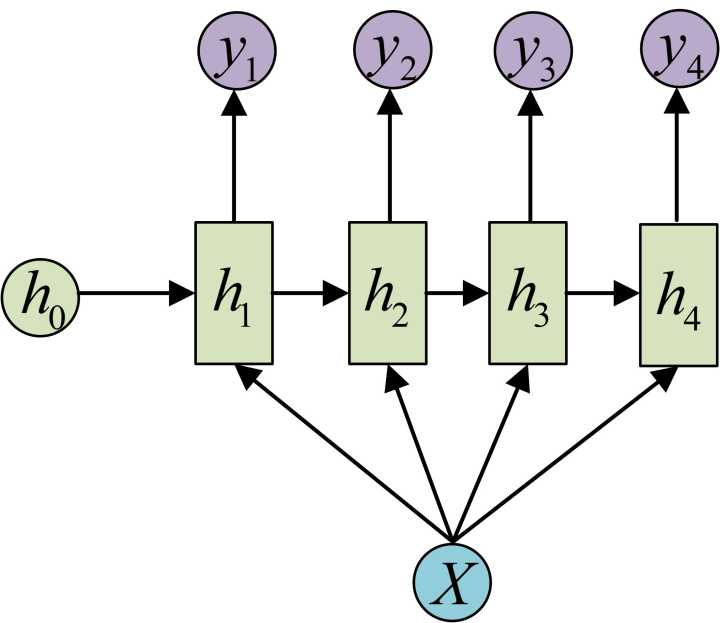
瞧,就跟着给似得,其实完全可以啊,但是,注意,但是,她们又觉得,虽然在翻译阶段,你给了之前的输入,这些输入应该是重点的,比如
i love beijing tian an men=>我爱北京天安门。
翻译“爱”的时候,love这个词明显最重要嘛!所以,这个时候,我们要是把注意力Attention集中到love身上,这才符合正常人类的思维习惯嘛,所以,每次再把这x1,x2,x3,x4(上上图中)灌给输出阶段,也就是翻译阶段的时候,每次告诉这个网络,你丫应该关注哪个输入的词。 所以,我赶紧补刀一下,你看,Attention每次就是一个概率向量,维度就是你输入的那个x序列的个数,每个维度,标明这个x1,x2,x3,x4四个词,我应该重点关注哪个词,通过概率体现。
接下来把李宏毅老师的思路捋捋,
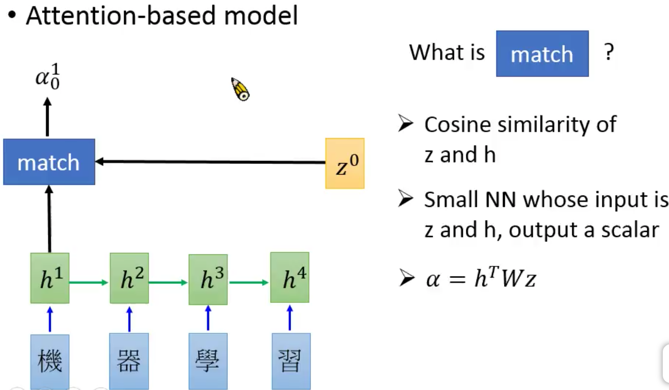
先用某种方法(李老师说了3中,余弦相似度、神经网络、矩阵变换,就是那个match),将翻译过程中的隐层输出+一个$z$,得到一个$\alpha^1)$,z是啥?z是另外一个RNN的隐层,你听不懂吧?没关系,后面你就明白了。
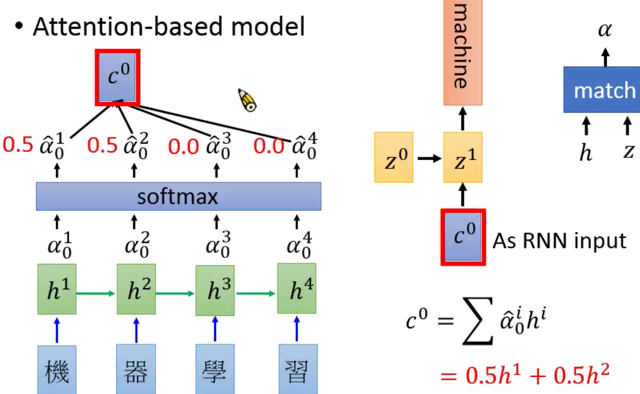
根据$h^1,h^2,h^3,h^4$,得到$\alpha^1,\alpha^2,\alpha^3,\alpha^4$,softmax她们,得到一个$c^0$,然后用$z^0+c^0$,通过一个RNN神经元(也可以是LSTM神经元,都行),得到一个新的隐层输出$z^1$,再经过$z^1$,输出一个结果,是个softmax的概率分布,这里再冲自己唠叨一下,y1=softmax(z1)
知乎上的王赟大神说的:每个时刻的输入都是一个向量,它的长度是输入层神经元的个数。在你的问题中,这个向量就是embedding向量。它的长度与时间步的个数(即句子的长度)没有关系。 每个时刻的输出是一个概率分布向量,其中最大值的下标决定了输出哪个词。
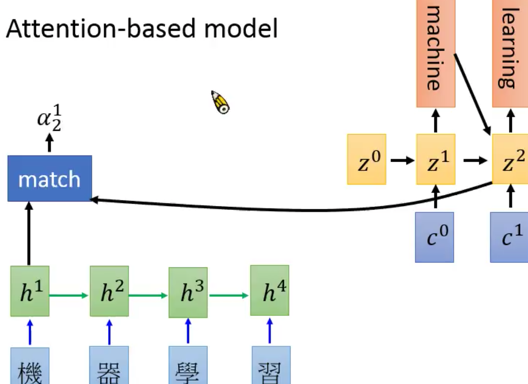
你看!右边整个一个RNN啊,只不过,隐层变成了z,这个z每次还要在返回到左边的RNN上,去参与$alpha$的计算,你看,简直是在两个维度空间穿梭呀。
总结一下李宏毅老湿讲的内容吧: 就是先用你开始train的那个输入rnn的输出$h$加上一个另外一个输出rnn的隐层输出$z$,干出一个$\alpha$,挨个干每个输出得到一堆$\alpha_x$,softmax她们丫呢,得到一个概率向量$\hat{\alpha}$,维度是输入的个数,然后类似于求期望值,把$\sum \hat{\alpha}h^i$,得到$c$,用$c$和$z_{t}$通过一个RNN,得到下一个$z_{t+1}$,进而得到输出$y$。
真的是复杂死了,总之,就是,每次的结果,都是对输入进行“关注attention”后,得到重点(概率分布)后,得出结果。并且,这个隐层会帮助产生下一个“关注”。
Attention,实际上是两个RNN,输入的RNN,关注(Attention)+输出的RNN。
以下帖子,对我理解帮助很大,必须围观:
https://zhuanlan.zhihu.com/p/22081325
https://zhuanlan.zhihu.com/p/28054589
http://www.cosmosshadow.com/ml/…/Attention.html
http://blog.csdn.net/malefactor/article/details/50550211
https://zhuanlan.zhihu.com/p/27743442