
概述
从春节后,就着手这个项目,从开始研究,到上手代码,到样本生成,到真实样本采集等,经历了整个过程,已经2个月了,项目也基本上完成的差不多了,开一个帖子,把自己的项目中的点滴记录下来。
CTPN
代码库
我最终选择的是eragonruan的版本,fork了一份,放到了我的github上,但是CTPN确实有不少问题,如果让我重新选择的话,我可能会选择EAST或者PSNet。特别是PSNet,有个QQ群【785515057】,群主就是复现PSNet代码的“晓恒”,群里面也非常友爱互助,真后悔没有早点遇到这群人。不过,CTPN是一个保守选择,对我们的场景,是够用的了。我也没时间再去研究PSNet了,也只有这样了,下个项目或者二期的时候,我会去再选择PSNet了。
另外,我fork的版本修改了和增加了狠多内容,包括:
- 重写了训练数据生成的部分,基本上是从头写的了
- 重构了样本split的代码
- 修改了样本加载机制,没有用TFRecord,而是用的shuffle_batch的方式
- 重构了训练代码,加入了早停、Validate验证等
- 重构了预测代码
- 修改了很多细节,模型细节,训练细节等
网络结构没有什么变化,还是vgg做为backbone,然后接一个LSTM,全连接后,做一个anchor的正负例和回归预测。不过,这些代码里面,增加了大量的注释,都是我对代码的理解,特别是核心类anchor_target_layer.py,由于注释太多,我都惨不忍睹了,只好备份一下注释版,然后删除掉注释,整了一个整洁版。
修改细节
样本数据生成
generator.py,里面尽量模拟了各种的文字情况。从网上花钱买了一些白纸背景,然后,搞了一堆的20多种字体,生成的时候,不仅仅生成文字,还要生成数字,字母等,而且考虑到各自的比例,按概率生成。并且,做了各类模糊和处理,加入了仿射(完成倾斜),模糊,锐化,加入了干扰线。
bbox样本的split
我们知道,CTPN的样本,不是你的标注,而是把你的标注的四边形,变成一个一个的小矩形,这个是靠split.py完成的,代码读着有些诡异,要对opencv处理多边形的形态学api比较熟悉才行,倒是不难。有个细节说一下,切的时候,第一个图像必须是要和16整数倍的像素对齐的,所以可能会切出来宽度很小,但是太窄了,我担心当做样本去和anchor比较的时候,基本上没啥用(算IoU算不出高值来,算regression调整有比较剧烈),所以,我把小于3个像素的切出来的bbox都直接扔掉了。最后一个bbox也有这个问题,我本来也是同样的处理方法,后来发现右边总是没有,老缺一块,所以后来我就索性多算一些,直接把最后一个bbox直接设成16像素了,多点就多点吧,后面crnn识别反正也能搞定。
训练
启动参数
加入了一系列的参数,方便训练,以及验证。如lambda,是按照论文加上的,主要是观察到rpn classes的loss和regression的loss,差差不多3个数量级,所以默认设置lambda=1000;
验证、F1和早停
之前的代码是没有验证集的,我加入了验证集,并且在训练的过程中进行验证。验证什么?验证F1。F1如何算?这个后面再细谈。
加入了F1,Recall,Precision的计算,并且把他们加到了summary中,以便于后续在TensorBoard中观察。
加入了早停,默认是5次,加载10张验证集图片,计算探测出来的大的GT框的F1,如果持续5次都没有改进,就会早停。
图片Resize
之前,看eragonruan君的代码中总是resize图片,我当时就想,resize啥啊,不resize也没事啊,于是,我就给他的resize相关代码,都删掉了。我造的样本没事,但是,当我用真实的样本的时候,训练不超过100 steps就出现OOM,靠。同样的代码,我切回我的训练集,就没事。没办法,只好又把resize代码加了回来。resize的处理还是有些麻烦的,所以我秉承一个原则,在数据进入network前才做resize,从network预测出来的结果立刻就是un-resize回去。我写了单元测试,没事,但是还有一丝担心,这毕竟对训练息息相关。
可视化调试
我在session.run的feed_dict加入了一个张量,“input_image_name”,把文件名传入了计算图,为何呢?为了可视化。我想在训练过程中,把整个训练过程可视化。可视化什么?可视化anchor的产生过程。anchor的生成,和GT别的比较,选择,这个过程都是在代码中,只能通过读代码理解代码,才能理解,一旦有问题,你根本无法验证。我很郁闷这点。所以,我就写了一个调试代码,把图片传入后,把anchor生成、筛选过程等,都可视化出来,把anchor、gt和一些调试信息,都画到了图上,输出到data/pred目录下。
评价
ICDAR2013则使用了新evaluation方法:DetEval,也就是十几年前Wolf提出的方法。“新方法”同时考虑了一对一,一对多,多对一的情况, 但不能处理多对多的情况。 (作者说,实验结果表示在文本检测里这种情况出现的不多。) 这里的框无论是标定框还是检测框都认为是水平的矩形框
其实,思路很简单,就是分为3种情况,1对1,1对M,M对1。每个框都属于这3种情况中的一个,不会重复。细节可以参考那两篇博文。
这个算法支持对小框,也就是bbox,和大框(GT)的评价,不过,后来bbox的评价基本上被我废弃了,因为,没必要,直接看大框的就可以了。
Anchor的筛选
我认为,这个类才是整个项目的核心,代码复杂,也不好理解,也是我花时间比较多的内容。看这个内容,还是要对论文熟悉,对算法熟悉,否则,你看着肯定是馒头雾水。你可以参阅白裳的这篇讲解,我这里只说说我趟的坑:
一个诡异问题
曾经遇到过一个问题,
gt_argmax_overlaps = overlaps.argmax(axis=0) #G#找到每个位置上9个anchor中与gtbox,overlap最大的那个
gt_max_overlaps = overlaps[gt_argmax_overlaps,np.arange(overlaps.shape[1])]
gt_argmax_overlaps = np.where(overlaps == gt_max_overlaps)[0]
labels[gt_argmax_overlaps] = 1 # 每个位置上的9个anchor中overlap最大的认为是前景
这段代码我理解不了,觉得没用,就给注释了,原因是,我把gt_argmax_overlaps = np.where(overlaps == gt_max_overlaps)[0]得到的这个gt_argmax_overlaps对应的anchor画出来(紫色的),全屏幕都是了:

其实我是没想清楚的,当时,后来凭借实证,就觉着这个代码是祸害,就给注释了。后来和同事讨论了一上午,终于搞清楚了,这个是有用的,这个是有用的。
# 这句话是找到每个gt对应的最大的IoU的那个anchor的行号,一共有多少个个呢,gt的个数一样,也就是270多个
gt_argmax_overlaps = overlaps.argmax(axis=0)
# 然后,从overlaps中,把每个行,对应的gt的那列,的值,拿出来,是一个一维数组(这块有点绕,看下面的例子吧)
gt_max_overlaps = overlaps[gt_argmax_overlaps,np.arange(overlaps.shape[1])]
# gt_max_overlaps是长度为\|GT\|,值为overlaps中每个gt对应最大的ioU的值的数组,
# 那这个where后,就是把这个GT列对应的其他的和这个max最大IoU值一样的anchor行号,也找出来
gt_argmax_overlaps = np.where(overlaps == gt_max_overlaps)[0]
labels[gt_argmax_overlaps] = 1 #设置为前景
所以,这个就是说,把某个GT对应的最大的IoU的anchor挑出来,但是,对某个GT来说,还有别的anchor和他相交的IoU的值和这个max值一样的话,你也不应该漏掉呀,恩,合理,所以给挑出来。可是,为何挑出几乎所有的anchor了呢?满篇的紫框?!原因是,某个GT的最大的IoU值为0,这样的话,不得了了,因为每个anchor都有等于0的overlap中的值,所以每个anchor都成为备选了。那为何为0呢,按理说,GT最大的那个anchor,总是存在的,至少有一个anchor应该和GT相交吧,那IoU怎么也不是0呀?!我们怎么办呢?我们只好把这个问题anchor,也就是IoU=0的这个anchor画出来,也把他相交最大IoU的那个GT也画出来。
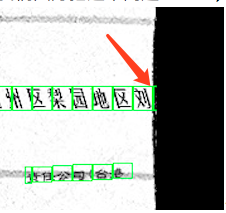
看到了吧,就是最右侧那个半拉子绿框。后来我俩一想,终于想明白了:
那就是你的anchor是按照feature map生成的,是16像素的整数倍数,可是你用feature map还原到原图的时候,那最右侧的,大于最后一个16整数倍像素的,但是又不到下一个16像素宽的边,这个之间的像素,是无法被anchor们覆盖掉的。可是,偏偏有个gt就在这里。那么这个gt无论和那个anchor算IoU都是0啊!这个就是问题所在了。
这个问题,未来的影响是,这种地方的文字可能检测不到了,恩,这是问题。 但是对其他的应该没啥影响,所以,我决定还是忽略掉。 这个问题,很隐蔽,我们的体会就是,一定要可视化,这样,很多问题就明显的显现出来了。
关于预测的交叉熵
有一段时间,死活预测不出来,我只好又回去读论文: 1.读论文,某个GT框,跟他对着的最大IoU的那个anchor,自动就是样本了,我之前给忽略了,这样的样本,不知道是不是跟这个有关系,但是论文里明确说这样的得要:

啥意思?就是说,算回归的时候,除了那些是正例的框外,跟GT的IoU大于0.5的也可以参与回归计算。貌似我fork的这个text-detect-ctpn代码没有实现。如果实现的话,在算overlaps矩阵的时候,应该单独再存一下IoU>0.5的anchor们,他们也许达不到前景的目标$(0.7)$,但是,他们可以参与均方误差回归的。 恩,你看,他的前后景判断,和,他的回归用的anchor可能不是一样的、一批的,但是,我们的这个项目里面,是把这两者绑定到一起的,不过,在我看来,这样倒也无所谓。
一直有个疑问?为何要算背景的概率?你既然算了前景的概率,用1减去前景的概率,不就是背景概率了么?这不是个二分类么?!我看代码里面:
cls_pred_shape = tf.shape(cls_pred)
cls_pred_reshape = tf.reshape(cls_pred, [cls_pred_shape[0], cls_pred_shape[1], -1, 2]) #2是指两个概率值,(1, H, WxA, 2)
rpn_cls_score = tf.reshape(cls_pred_reshape, [-1, 2]) #(HxWxA, d)
rpn_keep = tf.where(tf.not_equal(rpn_label, -1)) # rpn只剩下是非-1的那些元素的下标,注意!是位置下标!
rpn_cls_score = tf.gather(rpn_cls_score, rpn_keep) # 把对应的前景的概率取出来,rpn_cls_score是从cls_pred来的(具体自己读代码)
rpn_cross_entropy_n = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=rpn_label, logits=rpn_cls_score)
然后,我打印了一番: 做交叉熵:predict[[[0.000618884573 -0.00124687876]][[-0.002699879 -0.00737032201]] 卧槽!你看,不是0/1分布的(0,1分布应该是相加为1,概率分布嘛),这!这!这!
tf.nn.sparse_softmax_cross_entropy_with_logits:函数输入的logits是非softmax的。
cls_prob = tf.reshape(tf.nn.softmax(tf.reshape(cls_pred_reshape, [-1, cls_pred_reshape_shape[3]])),
[-1,
cls_pred_reshape_shape[1],
cls_pred_reshape_shape[2],
cls_pred_reshape_shape[3]],
name="cls_prob")
rpn_cross_entropy_n = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=rpn_label, logits=rpn_cls_score)
后来搞清楚,tf.nn.sparse_softmax_cross_entropy_with_logits,要求你出入的logits,一定是非归一化的值。
训练的trick
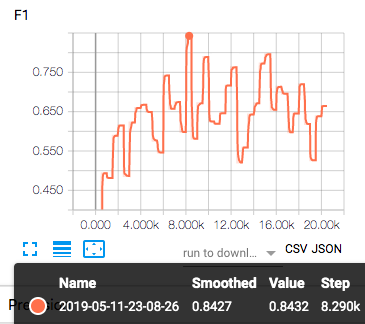
这一次的训练到达了84%的F1,效果如何呢?
CRNN
CRNN的难点在于CTC,其他的都好说。不过还有一些小的trick,在实现和训练过程中。
代码库
我的代码位于Github,是基于一位百度的工程师的实现,我没有用其中的TFRecord方式,而是采用shuffle_batch的方式加载数据。
我的主要的修改包括:
- 修改了字符集合,添加到了将近7000的字符集
- 修改了数据记载方式,采用了tensorflow推荐的shuffle_batch方式
- 自己实现了样本生成的代码
- 修改了加载数据的方式
- 增加了validate和早停
实现
字符集和映射处理
最开始的代码里面只有很少的一部分字符集,我后来找了一个5000的,是包含了一级字库[3375个]和二级字库[3008个],即charset.txt,参考,但是还是不够,后来,又加入了标点符号和一些生僻字,达到了6770个,也就是charset6k.txt。
字库文件的第一个为空格,作为保留,这个原因是因为,在转化labels里面文字对应的id,到稀硫张量的时候,id=0是一个无法使用的,因为稀硫张量会忽略所有的值为0的元素。另外,在load完词表文件后,又在最后的位置加入一个空格。这个空格原因是CTC_Loss函数需要的:
The `inputs` Tensor's innermost dimension size, `num_classes`, represents
`num_labels + 1` classes, where num_labels is the number of true labels, and
the largest value `(num_classes - 1)` is reserved for the blank label.
For example, for a vocabulary containing 3 labels `[a, b, c]`,
`num_classes = 4` and the labels indexing is `{a: 0, b: 1, c: 2, blank: 3}`.
[摘自tensorflow ctc_ops.py]源码。
样本生成
网上有很多样本集,不过,我还是造了自己的样本。
生成逻辑,实际上是借用了CTPN中生成一个文本块的代码,主要完成不同背景、字体、字号、倾斜、噪音等多种处理。你可以用来生成自己的样本。
训练了一轮后,发现正确率只能到50%左右,还是不行。因此再进行了一轮的改进。
识别过程中的一些微小问题:
- 小数点被识别成了逗号(发现是样本中小数点太少)
- 空格被认成负号,原因是缺少左右空格的样本(左右没有留白,但是实际上的切出来的图片都是有留白的)
- 英文效果不好(英文样本太少)
- 有些缺一角的识别不好(
针对这些问题做了如下改进:
- 发现了一个bug,数字都是整数,所以导致没有小数点
- 对所有数字,会左右加空格
- 专门有一部分做字母生成,字母和数字混合,字母和数字和汉字混合在校验的时候,把不认识的字都替换成了■,并且把OolIZS=>0011zs
- 用哼仔提供的程序切除的500万张里面挑了2万张来做验证集
然后,又深入修改造样本的程序,并且,还让哼仔开发了一个打标注程序,请同事们帮着打了一些标注文件,一共4万张,是基于阿里的识别结果基础上做的再校验。
修改样本生成程序:
- 修改了data_generator,支持多进程同时生成,提高效率
- 增加了image_enhance,实现了大于19种增强算法,替换了之前的3种
- 微调了image_enhance的各类参数,特别是kernel size
- 增加了sample_enhance,用来基于标注文件来生成更多的样本 其实是基于4万张样本,在基础上做了数据增强
- 微调了ctpn中的文字生成,增加了特殊字符的增强,空格的增强
最终,是用4万张中的3.5万张标注样本增强生成了60万张图片,另外用生成程序,再造了270万张图片,然后一共用着330多万张图片,训练了3天3夜,最终达到了86%的正确率。
加载数据
数据加载改成了用shuffle_batch的方式:
首先把图像文件名和标签文件名生成文件名队列
input_queue = tf.train.slice_input_producer(
[image_file_names_tensor,labels_tensor],
num_epochs=config.cfg.TRAIN.EPOCHS,shuffle=True)
然后加载图像,并且,转成张量。对应的标签则转成“SparseTensor”。
最后使用shuffle_batch,生成批量的tensor
images_tensor, labels_tensor,seq_len_tensor = tf.train.shuffle_batch(
tensors=[images, labels,seq_len],
batch_size=batch_size,
capacity=100 + 2 * batch_size,
min_after_dequeue=50,
num_threads=FLAGS.num_threads)
图像论文里面是100x32,我改成了256x32,让他宽一些。但是,不是标准大小的图像传入改如何处理呢?我觉得有四种方式:
- 直接暴力resize成为256x32
- 在一个批次里,找最大的宽度或者中位数宽度,向他对齐
- 根本不需要考虑对齐,直接就使用dynamicall-lstm的sequence_length参数来解决
- 还有一种方法就是保持原图比例,然后加入padding
我们最开始还使用的是第1种暴力方法,后来尝试了最后一种padding方法,padding白色背景,但是,我其实最喜欢的还是第三种方法,远航fork了一个版本,正在改成这种方式。
网络设计
CRNN的网络结构就不多说了,我前一篇文章描述过了。
在最后的双向LSTM输出后,要做一个512维度->6K类别的全连接,这个是为了输出对应的字类别,别忘了。
rnn_reshaped = tf.reshape(stack_lstm_layer, [-1, 2*self.__hidden_nums]) # [batch x width, 2*n_hidden]
w = tf.Variable(tf.truncated_normal([hidden_nums, self.__num_classes], stddev=0.1), name="w")
logits = tf.matmul(rnn_reshaped, w) # 全连接
logits = tf.reshape(logits,[ batch_s, -1, self.__num_classes])
这里输出的logits,会作为后续的CTC_loss的输入,这个是为经过归一化的(softmax)的值。
损失函数,用的是CTC_loss,CTC loss细节可以参考之前的文章。
CTC_loss
tf.nn.ctc_loss(labels=labels,inputs=net_out,sequence_length=batch_size)
labels是一个稀硫张量,啥是稀硫张量呢?参考
稀疏矩阵SparseTensor,由3项组成:
* indices: 二维int32的矩阵,代表非0的坐标点
* values: 二维tensor,代表indice位置的数据值
* dense_shape: 一维,代表稀疏矩阵的大小
比如有3幅图,分别是123,4567,123456789那么
indecs = [[0, 0], [0, 1], [0, 2],
[1, 0], [1, 1], [1, 2], [1, 3],
[3, 0], [3, 1], [3, 2], [3, 3], [3, 4], [3, 5], [3, 6], [3, 7], [3, 8]]
values = [1, 2, 3
4, 5, 6, 7,
1, 2, 3, 4, 5, 6, 7, 8, 9]
dense_shape = [3, 9]
代表dense
tensor:
[[1, 2, 3, 0, 0, 0, 0, 0, 0]
[4, 5, 6, 7, 0, 0, 0, 0, 0]
[1, 2, 3, 4, 5, 6, 7, 8, 9]]
input输入就是上面提到的网络输出logits,是一个未经过softmax归一化的raw结果。
然后是sequence_length,实际上就是图像的经过LSTM后的宽度,在我们这里是原始图像除以4以后的结果。
CTC_beam_search
decoded, log_prob = tf.nn.ctc_beam_search_decoder(
net_out,sequence_length=batch_size,merge_repeated=False)
在解析的时候,需要做一个beam search的解析,输入是还是logits,同时要告诉原始图像除以4以后的长度。
返回的是decode,是一个稀硫张量,所以你拿到后,按照上面的讲解,还要还原出对应位置的值,而log_prob则返回这个序列的似然概率(嗯,也可以说是这些字同时出现的联合概率)
训练&调优过程
在整个过程中遇到了一些问题,有些细节需要记录下来,方便以后的回顾:
- 修改了数据加载方式,不再是用基于tf.train.shuffle_batch,太难控制,远航修改了一个很直白的加载方式,就是多进程+队列,跟cptn的方式一样了
- 修改了训练的adam的leaning rate,从0.1变成了0.001,这个是adam默认的值,效果果然好很多,之前0.01的learning rate的死活不收敛的
- 不需要考虑lable的padding了,因为一个batch的labels长度不一,之前是做了一个对齐,缺的用0做padding,开始还担心0这个id会被占用,但是后来发现,转化成了SparseTensor时候0是不用考虑的
- 因为不用padding为0,所以词表的第一个不用空出来了
- 不能用不定长的图像宽度,本来dynamical-lstm支持动态time sequence的,也就是你在lstm中传入ts的,所以对一个batch中不同宽度的图片,本以为可以不用对齐,只要定义好sequence lenght就可以呢,结果后来一想,不行,因为图片再进入lstm之前,得过一个VGG,他要求是预定义统一宽度的,所以只好放弃不对齐的想法,老老实实做padding
- 因此,也决定只能resize成统一,所以加了一个resize为中位数的,尽量减少形变
- 修改了图片的预处理,支持强制resize成为(32,512),或者缩放到宽度为32,不够的部分补成白色(255),或者太长就截断到512
- 类似于ctpn,写了一个早停,自己实现了早停,开始用的负的编辑距离,后来改成了正确率
- 分别尝试在3770个一级字库和6880 二级字库上做训练,发现3770确实容易训练
- 判断正确率用的是标注的5000张图片
- 实现了一个validate batch,600张左右,用来计算编辑距离和正确率,大概需要30秒左右
- 正确率抛弃了繁琐的计算,规则简单粗暴,两个字符串一致才算正确,之前还想了一些复杂的方法,后来觉得都不适用
- 重构了validate,并且把训练和validate的scalar summary分开
- ctc_beam_search实在是太慢了,即时把beam改成1,也需要3-4秒,才可以识别一个batch(batch=32和64都差不多),后来在ocr群里面有人建议用greedy,于是改成了ctc_greedy,我靠,太快了,1秒之内就完成。(可是beam=1就是greedy了呀,这点,一直没想明白)
总结一下整个过程,
开始发现不收敛,后来发现是adam的步长的问题,从0.1->0.001就收敛了;然后是精度上不去,于是针对发现识别过程中的问题,进行改进,比如左右两边留白,中间插入空格,可以增大英文和标点符号、数字的概率;另外,放弃6880二级字库,直接专注于3770一级字库了;另外用标注样本混合自己造的样本共同训练,增加到300万+的样本量,并且用真实标注样本做测试集;终于最终达到了86%的识别率,在实际的测试过程中,感受也是差不多到达这个结果。

遗憾和问题
项目进行了4个月,从不了解OCR,到开始接触OCR的算法,然后读论文,找复现代码,阅读每行代码,到后来大刀阔斧的修改代码,以及不断地趟坑训练,收获满满,但是收获之余,仍然有很多问题和遗憾。
如果让我再选,肯定会CTPN和EAST同时考虑,但是当初由于时间有限,只好先选择CTPN,就没有时间去研究EAST了,EAST据说效果要好很多,从理由上来说,毕竟是使用了多个feature map的FPN,肯定要比单独的一个VGG最后的feature map对细节的感知要敏感的多啊。不过,后续我肯定会再去尝试EAST的。
另外,没有使用attention OCR,CTC由于揉入了$\epsilon$的空格在词与词之间,再加上B算法,你根本就搞不清楚到底从最后的feature map中,从左往右,哪个像素开始到那个像素结束,是某个字。我开始还奢求ctc_beam_search可以告诉我哪个字识别概率低,后来发现,根本没戏,他只返回一个整个句子的似然联合概率,没啥意义。
这样,我就无法知道哪个字识别的概率低,从而反推回去到feature map,然后反推到原图中,找到对应的识别的差的部分,抠图出来,交给单字分类器再去识别了。
而这个方法,正是阿里目前针对低频字的识别方法:
生僻字的解决方法如上图所示,首先使用行识别,再进行了Attention单字识别方案解决了生僻字语料偏少的问题,Attention可以解决单字切字问题。通过上述方法,我们对2万多生僻字测试集进行了测试,精确度从21%提高到了99%,基本上解决了生僻字问题。
另外,目前的web服务方式是gunicorn+flask,使用的是每个进程单独加载一个模型,在GPU服务器上一开多进程worker就肯定显存就崩了,所以还要改进成多个进程共享模型的方式。或者,进一步探索tensorflow serving的方式。
体会
这个项目,最大的体会就是,样本啊样本,样本比啥都重要,我很多时间都画在了样本制作上面,CTPN从自己造样本,到最后放弃直接用真实样本;CRNN最终是真是样本+混合样本。自己的感受就是,只要样本足够多和多样性,模型就一定可以跑出满意的结果来。