
SVM理解
废话几句
这小文,就是自己看的,写给1、2年后的自己,想起SVM的时候,常回来看看,迅速回忆起来,不至于再去搜一堆文章看来看去的。所以,给自己写,就不图行文流畅和思路清晰严谨,主要是讲人话。把大牛们不愿意讲的,羞于说的一些超基础的,或者,看似废话,但是对我自己而言,就是绕不过去的弯,或者那些总结性、本质性的话,写下来,让自己迅速可以还原当初觉得自己看的明明白白的思路。
先说说点到直线的距离
写一下方程:
$ax+by+c=0$ ,我们一般的理解是$y=kx+b$,两种形式一样的,实际上是 $y=\frac{a}{b}x+\frac{c}{b}$。 一个点$(x_0,y_0)$到直线的距离D是怎样的呢? 是D=$\frac{|ax_0+by_0+c|}{\sqrt{a^2+b^2}}$,这个其实一般人都不讲,假设默认知道,其实,推导还挺复杂的,网上有点到直线距离的7种推导,茴香豆的7种写法,呵呵,不过感兴趣的同学可以去研究一下。
我们再来看看$ax+by+c=0$ , 我们可以写成$\left[a , b \right] * \left[ \begin{matrix} x \ y \end{matrix} \right] + c = 0$的样子,然后我们把$\left[ \begin{matrix} x \ y \end{matrix} \right]$看做是$X$,把$\left[a , b \right]$看做是$w$,把$c看做是b$我们可以把直线方程写成,$wX+b=0$的形式了。(注意,把c看做b是,现在是个新b了,就是原来的c,非要这么混乱的原因是为了满足一般书里的wx+b=0的形式)
胡思乱想(可忽略)我脑袋里一致有个问题,不是ax+by+c=0么?那么$ax_0+by_0+c$不就也是0?!晕了吧,前者是指直线上的点,但是这个$x_0,y_0$可不是在直线上的。
那么,我们在去看距离公式 D=$\frac{|ax_0+by_0+c|}{\sqrt{a^2+b^2}}$ = $\frac{|wX+b|}{|w|}$
其中w实际上就是直线$ax_0+by_0+c=0$的法向量,即(a,b),这个是初中知识,忘记的需要回去复习一下,法向量是一个垂直与直线的向量,他有无数个,只要垂直,都是直线的法向量。
$b$是个标量哈,$w$是向量,$x$是向量,别晕哈。
根据点到直线距离公式,$D=\frac{|wX+b|}{|w|}$,我们得到$r = \frac{|w * x_1+b|}{|w|} $,这张图里,我们“恰好”认为x1是一个支撑点,也就是x1“恰好”是wx+b=0这个直线两边最合适的支撑点之一。其实,你说为什么是x1,没有为什么,就是为了“凑”。
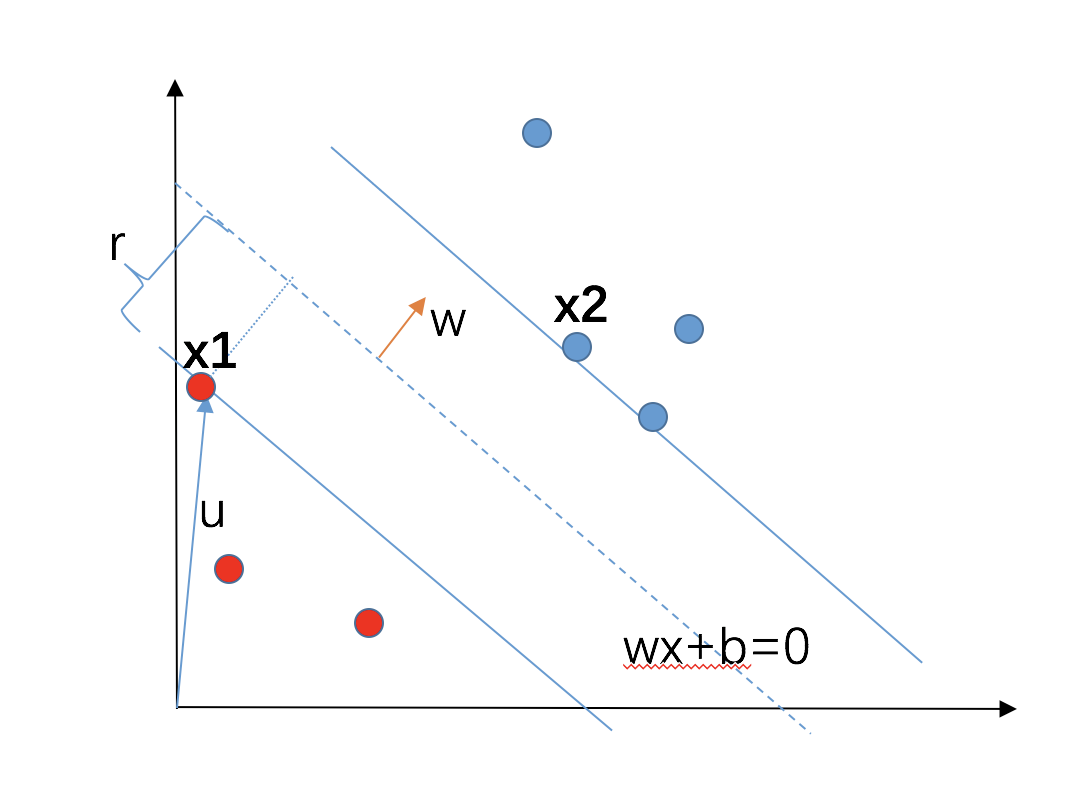
我们故意花了一条很赞的线wx+b=0,恰好可以分开两边的红蓝(正、负)例,而且,支撑点$x_1,x_2$恰好是正例和负例的支撑点。
好,再说一遍,支撑点$x_1$到我们完美策划的直线,距离$r = \frac{|w * x_1+b|}{|w|} $。当然,$x_2$也是一样的,$r = \frac{|w * x_1+b|}{|w|}=\frac{|w * x_2+b|}{|w|} $。这里小说明一下。
现在重点来了,我让这个距离变成$r=\frac{1}{|w|}$,你一定惊呼,不是$r = \frac{|w * x_1+b|}{|w|}$么?!怎么这么强入啊!卑鄙啊。我说,我就是要这么任性,把距离叫做这个$r=\frac{1}{|w|}$,你突然明白过来,此时的w不再是刚才那个w了,而是个新$w’$了,对,真实面目是$r = \frac{|w * x_1+b|}{|w|}=\frac{1}{|w’|}$,那么,啥时候可以这样啊,那一定是分子$|w * x_1+b|=1$的时候啊,那时候会对应一个$w’$,$r = \frac{|w * x_1+b|}{|w|}$不就变成了对应的$r=\frac{1}{|w’|}$了么!
举个例子,原来分割线是 x+y-1=0,也就是,我有个点是(-1,-1),我们可以算出来他到直线的距离是$\frac{3}{\sqrt{2}}$ 也就是说,$r = \frac{|w * x_1 + b|}{|w|}=\frac{3}{\sqrt{2}}$, 也就是,$|\left[1 ,1 \right] * \left[ \begin{matrix} -1 \ -1 \end{matrix} \right] + 1 |= \frac{3}{\sqrt{2}}$,那么重点来了。 敲黑板!!! 对于wx+b=0直线方程来说,等比例地缩放w和b,对应的方程直线是不变的,比如 x+y-1=0 ==> 2x+2y -2 = 0 ==>3x+3y-3=0,w=(1,1)/b=1 w=(2,2)/b=2,w和b的缩放并没有影响直线的表达,对吧。 那么我们就尝试缩放刚才那个 表达式中的w和b,使其从$r = \frac{|w * x_1 + b|}{|w|}=\frac{3}{\sqrt{2}}$变成$r =\frac{3}{\sqrt{2}}=\frac{1}{|w’|}$的样子,实现的方法就是上面说的,适当地缩放w和b,这个时候,就会对应出一个新的$w’, b’$,使得$\frac{3}{\sqrt{2}}=\frac{1}{|w’|}$,这个时候,b其实也要跟着缩放的。 对于上面的例子来说,当w从$(1,1)^T$变成$(\frac{1}{3},\frac{1}{3})^T$的时候,距离还是$\frac{3}{\sqrt{2}}$,当然这个时候,对应的b是$\frac{1}{3}$。
回过头来看,我们的点到线的距离,就可以变成了一个$\frac{1}{|w’|}$的样子,虽然看着简单,对应的b也是有约束的。
这个时候,思路有点散,我们回顾一下我们在做什么?我们在整出一个距离公式,这个公式有个特点,就是我们假设,我们对应的点是支撑点,也就是这个margin里面没有点了。这个正例点的距离和对面的负例点到分割线的距离是等距离的。当距离为$\frac{1}{|w’|}$时候,这个点满足等式$|w’x+b’|=1$,也就是那几个支撑点,都是满足这个要求的。并且,所有的正例呢都满足$w’x+b’>1$,所有的负例都满足$w’x+b’<-1$,这个是超平面的性质(参考)。
所以,这些约束和性质,就推导出来最重要的SVM的基本等式和约束:
SVM基础目标函数I
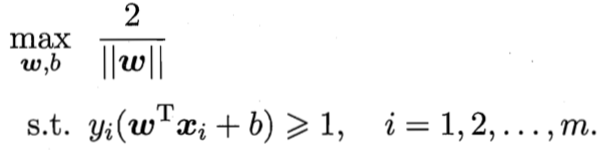
再来看看周志华教授的西瓜书的图,再次回忆一下:
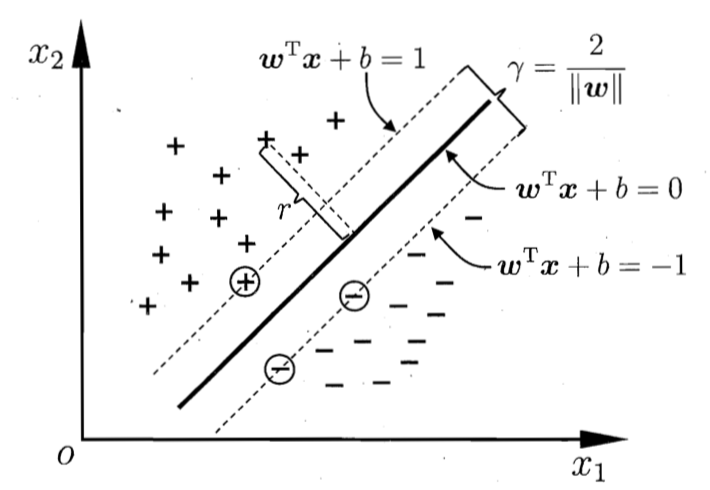
SVM拉格朗日函数
要优化了,上拉格朗日函数吧,参考我的凸优化, 由于这个是个凸优化,都不用上KKT神器,就可以玩的转:
把$max_{w,b} \frac{2}{||w||}$转化成$min_{w,b} \frac{1}{2} ||w|| ^2$ 另外,约束函数要<=0,所以要把$y_i(w^T x_i+b) \geq 1 $变成$1 - y_i(w^T x_i+b) \leq 0$ 写出拉格朗日函数来: $L(w,b,\alpha)=\frac{1}{2} ||w|| ^2 + \sum_{i=1}^n \alpha_i (1 - y_i(w^t x_i + b))$ 我们知道,这个拉格朗日函数的最大值,就是原函数的最小值,那么我们就是对这个函数求下界函数的最大值,就是原函数的最小值,对吧(绕过来了么?嘻嘻)。但是我们其实关心的不是最大最小值到底是多少,我们关心的是取得最大最小值的时候,那个w是多少,也你妈就是我要梦寐以求的分割平面的参数啊。 顺道吐槽一下,书里说的最大最小化,神神秘秘的,其实就是把人家的下界最大化,不讲清楚凸优化里的对偶函数强对偶条件,就说最大最小化之类的话,就是耍流氓。
然后,既然我们按照一般书里讲的,对拉格朗日函数对w和b进行求偏导,可是为什么要求偏导呢?而且偏偏只对w和b求导,而不对$\alpha$求导呢?
想了半天,原来是KKT条件引出来的,KKT条件是凸优化问题充分必要条件(此处心虚,忘了怎么证明的了), 回忆一下强对偶条件:
$d^* = g(\lambda^* ,\nu^* )$
$ \leq f_0(x^* ) + \sum \lambda_i^* f_i(x^*) + \sum \nu_i^* h_i( x^* ) $
$= f_0(x^* )+\sum \lambda_i^* f_i(x^* ) $
$\leq f_0(x^* )$
$=p^* $
在$x^*,\lambda^*,\nu^* $, $f_o(x^*)$取得最小值,$g(\lambda^ *,\nu^ *)$取得最大值,而且这两个值相等。就要求上面所有的$\leq$都要变成=,对与这个等式: “$g(\lambda^*,\nu^*) = f_0(x^*)+\sum \lambda^*_i f_i(x^*) + \sum \nu^*_i h_i(x^*)$”, 感觉“乱上”了啊,啥叫乱上了,就是你丫$g(\lambda,\nu)$本来是后面拉格朗日函数$L(x,\lambda,\nu)$的x取值下的下确界函数啊,你g一直都是小于等于L的,只有在极值点上,你们才相等。 你一定会说,$x^* $不就是极值点么?我扇你丫一个大嘴巴,在$x^* $上是$f_o(x)$取得极小值,谁他妈说过在拉格朗日函数L上,也取得极小值了。 不过,我会扇完你嘴巴,再给你揉揉,其实,在$x’$点上,拉格朗日函数确实是极小值,因为,$g(\lambda^*,\nu^*)$虽然取得最大值,但是它同时又是拉格朗日函数$L(x,\lambda^*,\nu^*)$的最小值(仔细看,x没有*,他是个变量;$\lambda^* ,\nu^* $有*,他们俩是固定值),是最小值,那么这个值对应的x可就是驻点嘛,偏导为0嘛, $\nabla_x L(x^{*} , \lambda^{*} , \mu^{*} )=0 $
[参考] 说说g函数。我的理解是,他是一个关于$\lambda, \nu$的函数,啥意思,就是你取值某个$\lambda, \nu$,就会得到一个值,这叫函数呀。那这个值怎么来的呢?是拉格朗日函数的在x取值范围内的下确界,讲人话,就是你给定一个$\lambda_0, \nu_0$,我就去算整个拉格朗日L函数的下确界,就是最小值,这个值就是g的值;然后你再给定一个$\lambda_1, \nu_1$,我又去得到一个关于x作为自变量下拉格朗日L函数的最小值;。。。。;这样下来,就形成了一个$\lambda, \nu$到L最小值的映射关系,这个映射关系,就是g函数。
总结一下还是,
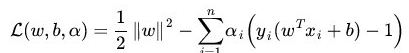
你看这个式子,因为,$y_i * (w^T * x_i + b)-1>0$,为何>0,这个是约束:
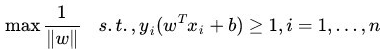
所以,$L(w,b,\alpha)$的后面那项永远是大于0, 所以,$L(w,b,\alpha)$最大也就取到$\frac{1}{2}||w||^2$,对吧。你的本意是要$\frac{1}{2}||w||^2$最小化对吧,所以你要做的就是要让$L(w,b,\alpha)$之后的,找到对应的$\alpah$参数们,然后再去寻找最小化$L(w,b,\alpha)$值的$w,b$。
然后是推导
$L(w,b,\alpha)=\frac{1}{2} ||w|| ^2 + \sum_{i=1}^n \alpha_i (1 - y_i(w^T x_i + b))$ $L(w,b,\alpha)=\frac{1}{2} ||w|| ^2 - \sum_{i=1}^n \alpha_i y_i(w^T x_i + b) + \sum_{i=1}^n \alpha_i$
上面提到了,强对偶的时候,满足对w和b的偏导为0:$\nabla_w$和$\nabla_w$ = 0
$\nabla_wL(w,b,\alpha)=w - \sum_{i=1}^n \alpha_i y_i x_i = 0$ $\nabla_bL(w,b,\alpha)= - \sum_{i=1}^n \alpha_i y_i = 0 $
于是,得到
$ w = \sum_{i=1}^n \alpha_i y_i x_i $ $ 0 = \sum_{i=1}^n \alpha_i y_i $
于是,这个时候,把这2个式子带回到拉格朗日函数里面去,可以只包含$\alpha$的函数:
$L(w,b,\alpha)=-\frac{1}{2} \sum_{i=1}^n \sum_{j=1}^n \alpha_i \alpha_i y_i y_j x_i x_j + \sum_{i=1}^n \alpha_i$
停!我们得到了什么,得到了只包含$\alpha$的拉格朗日函数,这个函数是L,不是下确界函数$g(\alpha)$,但是这个函数的最大值,恰好应该是强对偶的时候那个d * (g函数的最大值)。
那么好了,我们就对这个新得到的包含$\alpha$的函数求取最大值,得到的那一组$\alpha$后,我们用它再反推出w和b,从而得到我们的最佳分割超平面来。
核心思路就是这些,我觉得。
松弛因子

看这种图,最上面那个圆形点,是个异常点,如果你考虑了他,那么分出来的分离超平面的泛化能力就不强,我们凭直觉就感觉的到,虚线那个更好,泛化能力会更强,对不?
之前还记得吧,我们把点到直线的距离定义为 $y_i(w^T \cdot x_i + b) \geq 1$,对吧,总是大于等于1,我们归一化后。 现在,我们加入一个引子$\xi$,我们把这个约束改成: $y_i(w^T \cdot x_i + b) \geq 1-\xi, \xi \geq 0$ 所以,我们之前的SVM目标函数就变成了: $\frac{1}{2} ||w|| ^2 + C\sum_{i=1}^n \xi_i$ 约束s.t.为: $y_i(w^T \cdot x_i + b) \geq 1-\xi, \xi \geq 0, i=1,2…n$
啥意思啊,这公式再加上这个$\xi$,就跟一坨屎一样。 其实就是说,我本来是这个距离,但是我每个距离都加上一个$\xi$,你的$\xi$和我的$\xi$不一样,要去训练和学习的,有了这一堆$\xi$,我们就可以调整我们每个人到分割平面的距离了。 比如你的$\xi$是0.5,那我就允许你的距离大于0.5,就是说,
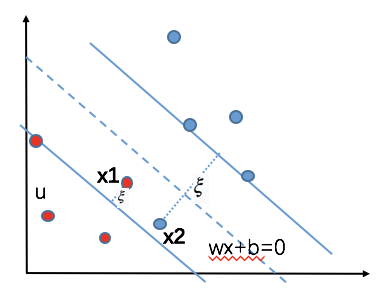
比如上图中的x1的$\xi=0.5$,x2的$\xi=1.5$。
那公司里的“C”呢?
C是个超参数,相当于在算每个点算分割超平面的距离的时候,不再是用$\xi$了,而是$C\cdot \xi$,这里我想吐槽一下,可能是我真的没明白,我的理解,这里距离上用$C\cdot \xi$了,那约束上是不是也应该用$C\cdot \xi$,就像: s.t.$y_i(w^T \cdot x_i + b) \geq 1- C \cdot \xi$, 这样我们就好理解多了,为何一个加C,一个不加C呢?
anyway,有了这个超参,我们就可以控制这个越界的个数了,尽量让。 ????
总结一下,松弛因子是在每个SVM支撑点的距离上加上一个$\xi_i$,注意,是每一个$\xi_i$,也就是会有多个。之前SVM优化的,就是让这些点到支撑平面的距离之和最大化,现在你还得加上一堆的松弛因子啦,然后,还是那套优化流程,最终你的到的是的那个最优化的超平面是考虑了让这些支撑点的松弛因子$\xi_i$也最小,的那个合计的到超平面距离最的,的那个超平面。
这个是和田甜讨论完之后,总结的,说白了,要理解松弛因子是针对每一个支撑点施加的,是一种惩罚项,但是要力求让他们最小。加入松弛因子后,可以容忍一些点的距离是负的了。这样,他可以跑到另外一侧去了,他可能是少量的异常点。这样做后,就可以增加模型的泛化能力。直接的结果是,让学出来的$w,b$得到调整,从而改变支撑平面的位置。
核函数
为什么要升维?
至于为什么需要映射后的特征而不是最初的特征来参与计算,上面提到的(为了更好地拟合)是其中一个原因,另外的一个重要原因是样例可能存在线性不可分的情况,而将特征映射到高维空间后,往往就可分了。(在《数据挖掘导论》Pang-Ning Tan等人著的《支持向量机》那一章有个很好的例子说明)
说白了,就是升维后,在当前低纬度里面不可分的,到了高维就可以分了。 啥叫高维就可以分了么?就是可以线性划分了。就是可以找一个超平面了,在那个$\Phi(x_i)$变换了之后的空间,这个$\Phi(x_i)$实际上是个升维函数,比如我本来是X是$[x_1,x_2]$,二维的,我可以变成$[x_1x_2, x_2x_3,x_3x_1,x_1x_1,x_2x_2,x_3x_3]$,乖乖,妈蛋6维了。在六维空间里,很容易线性可分。(至于为什么高维空间就容易线性可分,据说是可以数学上证明的) 参考
原来在二维空间中一个线性不可分的问题,映射到四维空间后,变成了线性可分的!因此这也形成了我们最初想解决线性不可分问题的基本思路——向高维空间转化,使其变得线性可分。 而转化最关键的部分就在于找到x到y的映射方法。遗憾的是,如何找到这个映射,没有系统性的方法(也就是说,纯靠猜和凑)。具体到我们的文本分类问题,文本被表示为上千维的向量,即使维数已经如此之高,也常常是线性不可分的,还要向更高的空间转化。其中的难度可想而知。
但是高维有高维的苦恼呀:
核函数,是拍脑袋出来的,就是拍脑袋认为kernel函数是一个高斯核 核函数,是$\phi(x_i) * \phi(x_j)$,不需要知道$\phi$是什么,只知道两者相乘的结果
核函数很精巧,可是怎么找啊?怎么就知道一个函数恰好是是一个很赞很赞的核函数呢?怎么就知道丫恰好是2个升维函数相乘的结果啊? 参考
万幸的是,这样的K(w,x)确实存在(发现凡是我们人类能解决的问题,大都是巧得不能再巧,特殊得不能再特殊的问题,总是恰好有些能投机取巧的地方才能解决,由此感到人类的渺小),它被称作核函数(核,kernel),而且还不止一个,事实上,只要是满足了Mercer条件的函数,都可以作为核函数。核函数的基本作用就是接受两个低维空间里的向量,能够计算出经过某个变换后在高维空间里的向量内积值。几个比较常用的核函数,俄,教课书里都列过,我就不敲了(懒!)。
Mercer条件,噢,没能力再钻进去思考了,不学数学,我想也就到这步把,让学数学的同学们替我们保证好吧。
上面提到的参考中的博文写的真好,不由再赞一次! 我就喜欢提问并自己回答的博文,比那种洋洋洒洒地写一通,基本上就是把教科书上的东西流水账的记录下来的文章搬家过来的装逼文章,强多了。这种自问自答的文章实际上就是一个发散型的思考过程,这个文章就是这种好文章:
明白了以上这些,会自然的问接下来两个问题: 1. 既然有很多的核函数,针对具体问题该怎么选择? 2. 如果使用核函数向高维空间映射后,问题仍然是线性不可分的,那怎么办?
多好的问题呀!
在低维中计算高维数据的点积
注意,使用核函数后,怎么分类新来的样本呢?线性的时候我们使用SVM学习出w和b,新来样本x的话,我们使用 $w^Tx+b$来判断,如果值大于等于1,那么是正类,小于等于是负类。在两者之间,认为无法确定。如果使用了核函数后,$w^Tx+b$就变成了$w^T\phi(x)+b$,是否先要找到$\phi(x)$,然后再预测?答案肯定不是了,找$\phi(x)$很麻烦,回想我们之前说过的.
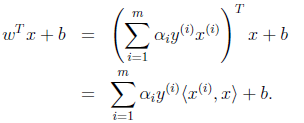
只需将$<x^{(i)},x>$替换成$K<x^{(i)},x>$,然后值的判断同上。
回答了之后,我们知道了很多know how:
对核函数的选择,现在还缺乏指导原则!
操,绝望!看来没啥好办法,就是用前人选好的把,咱也别纠结了,有事没事咱就选径向基函数(就是高斯核)吧,好吧,不纠结了。反正有交叉验证,看效果呗。
对第二个问题的解决则引出了我们下一节的主题:松弛变量。
这个咱上面讨论过欧了。
总结一下,
就是你在低维不可分,然后你就把x做一个映射,映射到高维去,就可以分了。可是,你映射过去后算内积特别费劲,恰好这个计算可以和某个低维x算内积的值一样,这样就好了,你就用低维x直接算出这个内积就好了。其实,你不用关心这个映射是啥,你只关心映射后的内积计算和低维的内积计算一样就成,你要的是高维内积的值。你要这个值干嘛?你要算
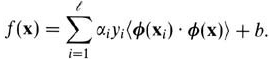
这个结果丫,>0就是正例,<0就是负例嘛。
SMO
写在最后
SVM驰骋机器学习界15年,不是盖的,那也是VapniK憋了N年的大招啊,从95年代初经典SVM的提出,到2010年前,都是最好的算法之一。而整个算法的形成,Vladimir N.Vapnik从1968年就提出来了,俄文写的,没人搭理,后来移民到了美国,才最终确立其在机器学习里的地位。这看上去一个算法很复杂,确实复杂,是包括Vapnik在内的无数智慧的结晶,是经过很多年的冥思苦想才得出的结论,你想一下子就搞明白,确实不容易。况且,数学上的积累和功底不够,很多地方其实自己觉得明白了,也只是自我迷幻的一种假象把。
机器学习算法用起来确实非常简单,import sklearn,用个grid search找到最优超参,然后看泛化能力,大抵如此。但是,即使如此,还是要学习,学习的目的还是让自己在用SVM的时候,心里能多一份自信、踏实,和对原理明确后的那份坦然,而不是,总是看到一个黑盒子那种莫名的恐慌。不过,即使自己觉得学明白了,又真的明白了么?对每个数学推导细节、对每一个引理公理都横亘于心么?不见得。还是上面那句话,只是自己对未知探求的满足而已,只是对自己掌控欲望的满足而已,仅此而已。
学SVM如此,学其他算法又何尝不是呢?
参考
https://blog.csdn.net/v_july_v/article/details/7624837
更新
【2019/2/22 更新】
田甜又给大家讲了一遍,捋了一遍从距离函数,引入约束的拉格朗日,到最大最小互换,到对偶,然后SMO。然后讨论到线性不可分,引出核函数。最后是,处理那些异常点的松弛因子引入提高泛化能力。
SVM就是这么一个思路,难点是距离的理解,本质是为了简化形式;然后是拉格朗日+对偶的折腾,最大最小换来换去,目的是处理好约束下的最优化;然后是SMO理解一下,目的是为了求解那一堆的$\alpha$;然后核函数,目的是为了减少内积计算;最后是松弛因子,目的是引入一个弹性因子来让距离可以变负,容忍一些节点的位置,从而让模型泛化能力更强。
其实,平时也没工夫研究SVM,研究它也就是蛋疼和面试之前,耐心点、细心点,把凸优化复习一遍,就可以按部就班的推导出来,再深一点的Mercer条件,甚至KKT条件,要深入,还是得再化额外的时间的,那就真考验数学功底了。对一般机器学习吃瓜群众来说,能推导一遍SVM就很牛B了,据说鹅厂面试就是手推SVM。再降低点要求,能把SVM的思路从头到尾的捋一遍,清清楚楚讲一遍,也是很赞了。真正用的时候,sklearn里SVC一调用,调调Gamma,做个GridSearch,也就酱紫了。
遗憾的一点是,大家还是没讨论到合页损失函数,找时间,我在补充上。